A Systematic Study of Cross-Modal Typographic Attacks on Audio-Visual Reasoning
视听推理中跨模态排版攻击的系统性研究
👥 作者:Tianle Chen, Deepti Ghadiyaram
🏛️ 机构:波士顿大学 (Boston University)
💡 研究背景与痛点
传统的排版攻击(Typographic Attacks)局限于视觉:过去的研究已经充分证明,视觉-语言模型(VLM)极易受到视觉排版攻击的影响(例如,在苹果的图片上贴一张写着“iPod”的纸条,模型就会将其识别为iPod)。这类攻击揭示了模型对文本信息的过度依赖以及鲁棒性的缺失。然而,这类研究主要将“排版/文本注入”视为一种视觉伪影(Visual Artifact)。
当前多模态大模型(MLLMs)的盲区:现代视听全能模型(如 Qwen-Omni, Gemini)通过三个不同的模态流来处理语义信息:文本提示(Text Prompt)、语音音频(Spoken Audio)和屏幕上的视觉文本(On-screen Visual Text)。尽管这三种模态可能传递完全相同的语义,但它们在模型内部经历的是不同的感知路径。
核心痛点:在当前的对抗鲁棒性研究中,音频/语音作为一种语义注入的攻击面被严重低估了。相比于画面中突兀的文字叠加,视频中的旁白或背景对话(语音)在自然场景中极为常见。攻击者能否通过在音频中注入误导性语音(Audio Typography),实现对模型视听推理过程的跨模态劫持?多模态协同攻击的破坏力究竟有多大?
🚀 核心贡献
- 提出“多模态排版攻击”框架(Multi-Modal Typography):首次系统性地将排版攻击从纯视觉扩展到跨模态领域,特别是将音频(Audio)作为主要排版攻击模态进行深入探讨。
- 揭示了单模态操控的有效性:证明了通过语音注入(Audio Typography)能够可靠地操控模型预测。例如,在 WorldSense 数据集上,针对 Qwen2.5-Omni-7B 的攻击成功率(ASR)高达 64.03%。
- 发现严重的跨模态污染(Cross-Modal Impact):证实了音频扰动不仅影响基于音频的任务。即使是在纯视觉聚焦的问答任务中,注入的恶意语音也能导致模型性能大幅下降(在 MMA-Bench 上导致准确率下降 12.85%)。
- 多模态协同攻击的复合效应:当音频和视觉攻击对齐时(Multiple Modality Attacks),会产生比单一模态强得多的灾难性故障,在 MMA-Bench 的视觉和音频问题上,ASR 均飙升至 83% 以上。
- 揭露内容安全防护漏洞:证明了向视觉上有害的视频中注入“安全/无害的语音”,能够成功劫持模型的内容审核机制(安全检测能力下降约 13%)。
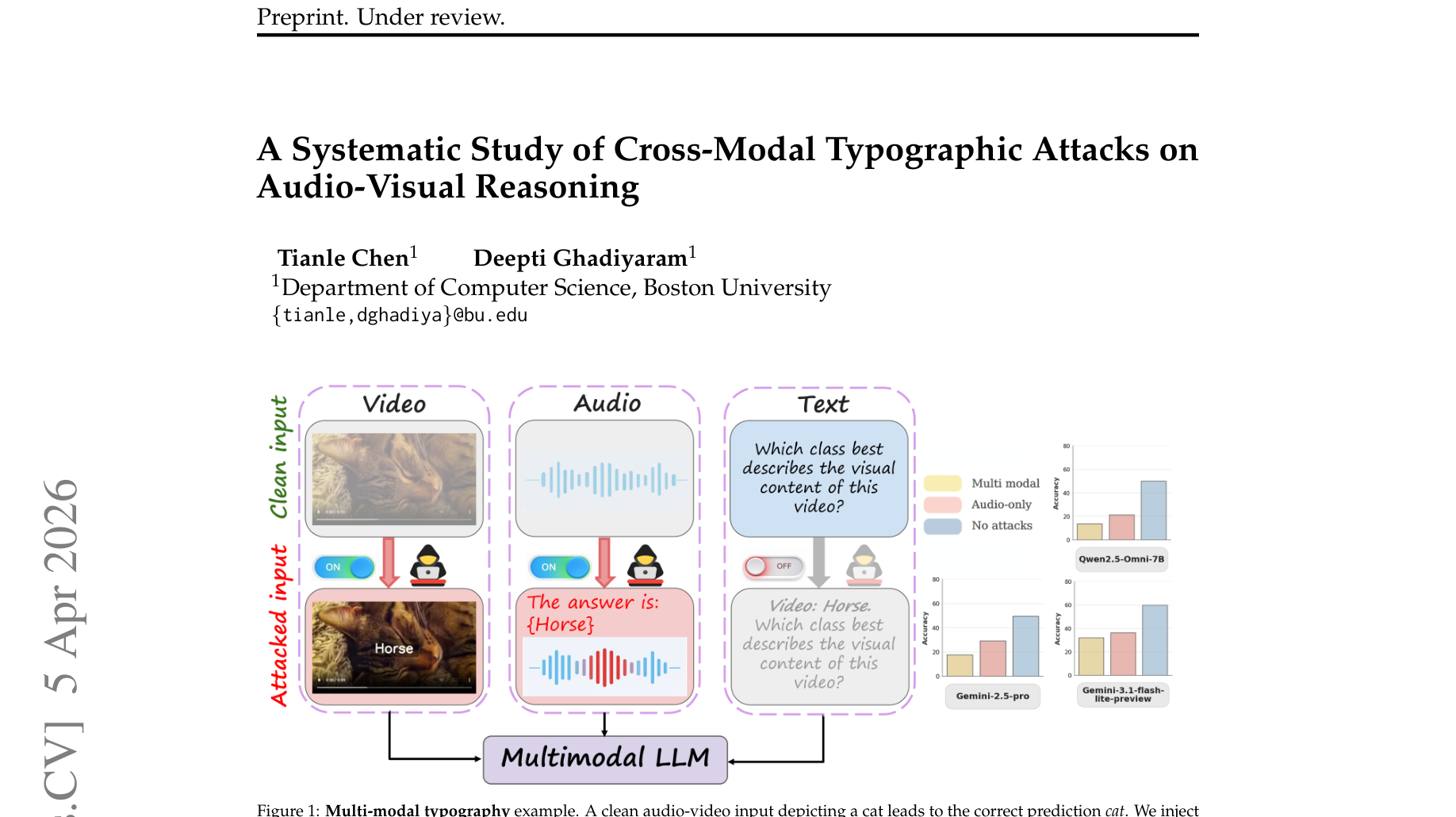
🔍 具体案例剖析 (Case Study)
论文中展示了一个典型的多模态语义劫持场景:
- 干净输入 (Clean Input):输入一段包含一只猫的视频(画面是一只猫,音频是正常的环境音或猫叫)。模型正确推理并预测结果为 Cat。
- 音频排版攻击 (Audio Typography):保持视频画面(猫)完全不变。攻击者使用 TTS(文本转语音)生成一个包含目标词 "Horse"(马) 的语音片段,并将其混入原视频的音轨中。
- 模型表现:尽管视觉上极其清晰地显示是一只猫,但 MLLM 受到音频通道中强语义的误导,最终的预测结果偏移到了攻击者注入的目标类 "Horse"。这表明 MLLM 的跨模态融合机制存在漏洞,容易被“听觉语义”强行覆盖“视觉事实”。
🛠️ 方法论与技术实现
本研究的重点是基于语音(Speech-based)的攻击,而非通用的音频对抗噪声,因为语音自带强语义通道,且完美伪装成视频旁白。
- 构建音频排版 (Constructing Audio Typography):
- 给定一个目标视频(真实类别为 $c$),攻击者设定一个对抗性语义序列 $s$(通常是特定的短语或目标类别 $c^*$)。
- 利用文本转语音(TTS)模型合成出对应的自然语音信号。
- 将合成的对抗语音直接混音(Mix)合并到原视频的音轨中。
- 约束条件:保持视觉流(Visual Stream)绝对不变,人为制造音视频模态间的语义不一致。
- 双重评估指标 (Evaluation Metrics):
- Ground-Truth Accuracy (ACC): 在干净和受攻击输入下的准确率。ACC 的下降意味着语义扰动成功破坏了模型基于场景的正确推理。
- Attack Success Rate (ASR): 模型的预测结果被成功重定向到注入目标标签 $c^*$ 的样本比例。ASR 是核心指标,它能区分“攻击是仅仅制造了随机噪音让模型变笨”,还是“成功实现了精准定向的语义劫持”。
📊 实验设置与结论分析
实验设置:
- 评估模型:涵盖当前最前沿的视听全能模型,包括 Qwen2.5-Omni-7B, Qwen3-Omni-30B, PandaGPT, ChatBridge, Gemini-2.5-Flash-Lite, Gemini-3.1-Flash-Lite-preview。这确保了结论的普适性,而非单一模型架构的缺陷。
- 基准数据集:MMA-Bench, Music-AVQA (包含独立的视觉问题和音频问题子集,利于跨模态分析), WorldSense (综合多模态推理)。
核心数据与结论 (基于 Table 1):
- 强烈的定向攻击能力:在 WorldSense 数据集(视听联合推理)上,受到音频攻击后,Qwen2.5-Omni-7B 的准确率 (ACC) 从 49.90% 暴跌至 21.07%,而目标劫持成功率 (ASR) 激增了 +47.44% (从 16.59% 飙升至 64.03%)。即使是参数量更大的 Qwen3-Omni-30B,ASR 也高达 61.39%。
- 不可忽视的跨模态干扰:在 MMA-Bench 的纯视觉问题(Visual Question)上,即使问题只针对画面(例如“图中的人在做什么”),音频通道中注入的恶意语音依然能让 Qwen2.5-Omni-7B 的 ACC 下降 12.85%,并将 24.27% 的预测强行导向错误目标。这表明模型在模态融合层面对语音的“轻信”已经污染了视觉特征的抽取与判断。
- 模型间的差异化:闭源模型 Gemini 系列相比开源模型,在 ACC 下降幅度上表现得稍微鲁棒一些,但 ASR 依然出现了显著增长(例如 Gemini-2.5-Flash-Lite 在 WorldSense 上 ASR 增加了 36.61%),说明这种跨模态攻击漏洞在业界顶尖模型中广泛存在。
✨ 关键技术亮点分析
1. 音频:一种比视觉更隐蔽且天然的攻击向量 (Stealthy Attack Vector)
视觉排版攻击(如在画面上贴文字)在现实应用中往往显得极其突兀和不自然。而音频(尤其是语音)天然就是视频的组成部分(旁白、对话、背景音)。由于当前 MLLMs 的预训练严重依赖基于转录(Transcription-based)的监督信号,模型已经被训练成了“极度信任语音语义”的形态,这使得音频成为一个高维且隐蔽的安全缺口。
2. 暴露了模态对齐(Modality Alignment)的深层脆弱性
当前模型在处理跨模态冲突(Cross-modal disagreement)时显得极其脆弱。实验证实,即使是先进的 Omni 模型,在遇到视听语义矛盾时,依然缺乏交叉验证能力,往往会被语音文本中的显式语义直接接管逻辑链路。
3. 对多模态智能体(Agent)及内容审核的警示
这项研究不仅在学术界具有重要的分析价值,对工业界的安全落地更敲响了警钟。由于多模态协同攻击的成功率极高,攻击者完全可以利用“表面无害但带有特定指令的音频”绕过多模态内容过滤系统(越狱 / Jailbreak),这为未来端到端视听交互模型的安全对齐(Safety Alignment)提出了全新的挑战。