Deliberative Searcher: Improving LLM Reliability via Reinforcement Learning with Constraints
基于约束强化学习提升大模型可靠性的审慎搜索框架
作者:Zhenyun Yin, Shujie Wang, Xuhong Wang, Xingjun Ma, Yinchun Wang
机构:复旦大学、上海人工智能实验室
📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Pain Points)
在当前大模型(LLM)的落地应用中,开放域问答、代码合成和复杂决策高度依赖于检索增强(RAG)和Agentic Search。然而,业内普遍面临一个致命痛点:置信度校准失效(Miscalibrated Confidence)。模型经常以极高的确定性输出错误答案,即陷入“错误且自信(False & Certain)”的状态。这种过度自信严重破坏了用户对系统的信任,是阻碍LLM走向高可靠性生产环境的核心壁垒。
现有的RAG或搜索增强方法主要存在两点局限:
- 信息主导(Information-Primary)而非推理主导:系统倾向于将海量检索结果直接堆砌到上下文窗口中,让模型“大海捞针”,而非主动通过推理来引导信息获取。
- 缺乏动态的置信度评估机制:虽然已有RLHF或基于CoT(Chain-of-Thought)的搜索框架(如R1-Searcher),但它们无法在多步搜索轨迹中显式且准确地追踪认知不确定性(Epistemic Uncertainty)。
💡 核心贡献 (Core Contributions)
本作提出了一种全新的“推理主导”搜索框架——Deliberative Searcher(审慎搜索者),通过带约束的强化学习(Constrained RL),将外部搜索无缝融入CoT生成中,同时维持显式的置信度校准。
- 引入动态置信度校准的交互式搜索:在CoT推理过程中,模型不仅决定何时搜索、阅读哪些文档,还在每一步观测后动态更新置信度分数,形成透明的不确定性追踪轨迹。
- 自适应约束强化学习(Constrained RL):结合最近的GRPO算法,通过自适应拉格朗日乘子(Lagrangian multipliers),在最大化回答正确率的同时,严格约束可靠性误差,有效消除了“错误且自信”的幻觉。
- 赋能高效的 Test-Time Compute (TTC):得益于完美校准的置信度分数,论文提出了一种置信度加权聚合(Confidence-Weighted Aggregation)方法替代传统的多数投票(Majority Voting),仅需 4 次采样即可达到 16 次采样的精度,推理计算成本降低 4 倍。
🔬 具体案例剖析 (Case Study)
为了直观展示模型如何将“置信度”作为一种需通过证据获取的内部状态,论文提供了一个具体的推演轨迹(图4):
Query: "BERT base比Attention is All You Need多多少个Transformer block?"
- Step 1: 模型发起
<search> bert base layers。找到BERT有12层。
当前置信度 (Confidence): 4/10(初步获取信息,仍不确定原始Transformer结构)
- Step 2: 发起
<search> original transformer architecture。检索结果有歧义,需要查阅一手信源。
当前置信度: 2/10(发现信息冲突,置信度合理下降)
- Step 3: 执行
<read> 阅读特定文档摘要,确认原始论文中 N=6。
当前置信度: 8/10(核心证据链闭环,置信度大幅上升)
- Step 4: 为求稳妥,再次执行
<read> 交叉验证两个架构的层数。
当前置信度: 9/10(交叉验证完成,得出最终结论 12-6=6)
资深从业者视角:这个案例极其关键。它证明了约束RL成功地将置信度从一个“二分类判定器”转变为一种“认知探测器”。模型学会了在信息不全时表现出不确定性,并通过主动检索权威证据来“赚取”高置信度。
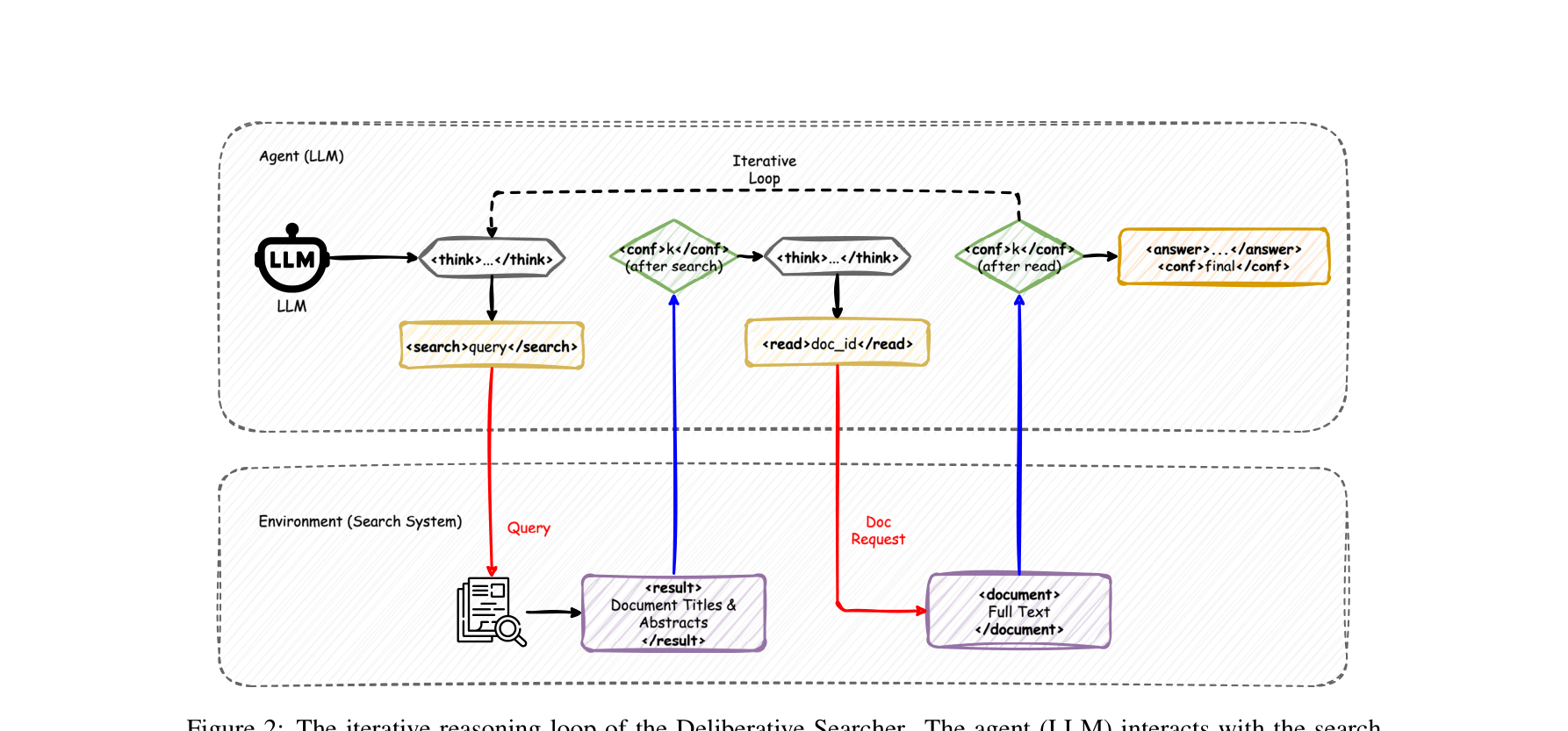 图注:Deliberative Searcher 的核心交互架构。Agent (LLM) 在内部思考 (think) 后决定发起搜索 (search) 或精读 (read),并在每次环境返回观测结果后,动态自我评估当前的置信度 (confidence),直至输出最终答案 (answer)。
图注:Deliberative Searcher 的核心交互架构。Agent (LLM) 在内部思考 (think) 后决定发起搜索 (search) 或精读 (read),并在每次环境返回观测结果后,动态自我评估当前的置信度 (confidence),直至输出最终答案 (answer)。
⚙️ 方法论与技术实现 (Methodology)
模型的动作空间定义为 $\mathcal{A} = \{\text{think, search, read, confidence, answer}\}$。模型采用“两阶段检索”:先基于摘要评估相关性,再决定是否提取全文,以此缩减Context长度并提供清晰的决策信号。
1. 约束强化学习目标 (Constrained RL Objective)
传统的RL模型目标是最大化奖励,但在追求正确率时往往会导致过度自信。本文通过引入可靠性约束 $U_i(\theta) \ge a_i$ 扩展了传统框架:
$$P^* = \max_\theta \min_{\lambda \ge 0} \mathcal{L}(\theta, \lambda) = R(\theta) + \sum_{i=1}^m \lambda_i (U_i(\theta) - a_i)$$
这里的 $\lambda$ 是自适应拉格朗日乘子。在GRPO优化过程中,策略网络最大化期望正确率(Primal update),而 $\lambda$ 则通过梯度上升(Dual update)持续调整,以保证系统满足预设的可靠性阈值。
2. 复合奖励设计 (Reward Design)
系统的最终奖励由三部分构成:格式合规性 ($r_{format}$)、回答准确性 ($r_{acc}$) 和 可靠性奖励 ($r_{reliab}$)。其中可靠性定义为正确率与模型自我报告的确定性($c(s_T) \ge \zeta$)的一致性:
$$r_{reliab} \triangleq (r_{acc} \land (c(s_T) \ge \zeta)) \lor (\neg r_{acc} \land (c(s_T) < \zeta))$$
最终 Reward 计算为:$r_{final} = r_{format} \cdot (0.1 r_{format} + 0.9 r_{acc} + \lambda r_{reliab})$。如果格式错误则全局奖励归零,充当硬约束。
📊 实验设置与结论分析 (Experiments & Results)
论文在三大类模型上进行了实验:7B级别(如Qwen2.5-VL-7B, R1-Searcher)、70B级别(如DeepSeek-R1-Distill-Llama-70B)以及闭源SOTA(GPT-4o, Claude 3.5 Sonnet)。评测集覆盖了 In-Distribution 多跳推理(HotpotQA, 2Wiki, MuSiQue)和 OOD 真实联网评测(GAIA, xbench-deepsearch)。
- 根除“危险的自信” (Eliminating False-Certainty):7B版本模型将平均 False-Certain Rate (FC%) 从竞争对手的 54% 压倒性地降低到了 2%。72B版本在匹配 GPT-4o 准确率的同时,FC% 仅为 9%(优于 GPT-4o 的 26%)。
- OOD泛化能力极强:在 GAIA 等真实开放域检索任务中,基线模型因为从未见过此类问题,FC% 高达 50% 以上;而本作的模型能敏锐地察觉到“知识盲区”,在 OOD 数据上依然保持极佳的置信度校准。
- 测试时计算的高效利用 (TTC Efficiency):由于产出了高度可信的连续置信度,这使得自适应计算 (Adaptive Compute) 成为可能。在相同预算下,基于置信度加权的投票(Confidence-weighted voting)全面碾压标准的多数投票(Majority Voting)。72B模型仅需 4 次 Rollout,其准确率即可媲美传统方法 16 次采样的结果(4倍算力节约)。
🌟 关键技术亮点分析 (Key Highlights for Practitioners)
- 自适应 $\lambda$ 解决奖励塌陷难题:在消融实验中,如果将可靠性权重 $\lambda$ 设为定值,模型会迅速找到一条“捷径”(退化解)——永远输出极低的置信度来逃避惩罚。采用自适应拉格朗日乘子,迫使优化器在准确率陷入瓶颈时,自动动态拉升对校准的约束。这使得算法具有极强的架构可迁移性,7B/72B 规模无需繁杂的超参网格搜索即可跑通。
- 对 O1/R1 范式推理缩放(Scaling Inference Compute)的启示:当前主流的推理增强往往依赖暴力采样(如 Self-Consistency)。但当涉及到外部工具调用(Search)时,由于网络结果的非确定性,暴力投票成本极其高昂。Deliberative Searcher 证明了,通过RL将“认知不确定性”内化为一条可信的标量轨迹,能够为Test-Time Compute提供一个精妙的分配权重。将算力集中在“高置信推理路径”上,是下一代 Agent 降本增效的核心方向。
AgentV-RL: Scaling Reward Modeling with Agentic Verifier
AgentV-RL:利用智能体验证器扩展奖励建模
作者:Jiazheng Zhang, Ziche Fu, Zhiheng Xi, et al.
机构:复旦大学,华中科技大学,香港大学,字节跳动 Seed
📄 查看 ArXiv 原文
💡 研究背景与痛点 (Background & Motivation)
随着 o1 和 DeepSeek-Math 等推理模型的崛起,测试时扩展(Test-Time Scaling, TTS)已成为提升 LLM 复杂推理能力的核心范式。TTS 的有效性(如 Best-of-N 并行采样或迭代拒绝采样)高度依赖于奖励模型(Reward Model, RM)/验证器(Verifier)的精准度。
然而,现有的验证模型(包括结果奖励模型 ORM、过程奖励模型 PRM 以及基于生成式的奖励模型 GenRM)在复杂数学或逻辑领域面临两个致命挑战:
- 错误传播(Error Propagation): 大多数 LLM 训练数据是正确的解答。面对表面看似合理但中间步骤存在逻辑谬误的解答时,由于采用“单轮推理”范式,模型极易被误导,产生“幻觉式赞同”(False Positives)。
- 缺乏外部事实锚定(Lack of External Grounding): 在计算密集型或知识密集型任务中,纯文本模型自身算力有限,缺乏外部工具(如代码解释器)的支持,导致验证结果不稳定、不可靠。
🚀 核心贡献 (Core Contributions)
- 提出 Agentic Verifier 范式: 摒弃了传统的标量打分或单次文本生成,将验证过程重塑为多轮交互、工具增强的深思熟虑过程(Deliberative Process)。引入了互补的前向智能体(Forward Agent)和后向智能体(Backward Agent),分别进行充分性与必要性检查。
- 设计 AgentV-RL 训练配方: 提出了一套可扩展的模型蒸馏与强化学习方案。包含端到端的合成轨迹数据引擎、拒绝采样微调(SFT)以及群体相对策略优化(GRPO),旨在解锁验证器的长程推理与工具集成能力。
- 实现 SOTA 性能突破: 仅以 Qwen3-4B 为基座的变体,在 MATH500 和 AIME24 等基准测试中,一致超越了当前的 SOTA 结果,甚至以 4B 的参数量击败了 70B 级别的结果奖励模型(如 INF-ORM-Llama3.1-70B,提升最高达 25.2%)。
🔍 具体案例剖析 (Case Study: 为什么传统 GenRM 会被骗?)
以附录 D 中的复杂多项式求根题为例($x^{10} + (13x - 1)^{10} = 0$,求复数根特征):
- 错误解法(候选解答): 伪造了一个根变换映射(如果 $r$ 是根,则 $1/13r$ 也是根),并盲目套用韦达定理得出“所有根之和为0”,最终得出错误结论。
- 标准 GenRM 的表现: 模型顺着给定的解题思路往下看,被表面高级的数学公式(韦达定理、复数共轭)唬住,顺着逻辑补齐了幻觉验证文本(如“通过检查系数确实发现和为0”),给出了 Verdict: Correct (False Positive)。
- Agentic Verifier(前向智能体)的表现:
- Plan(规划): 分析出需要验证两个核心支柱:根变换映射和韦达定理的应用。
- Validate(验证 - 根测试): 代入 $s=1/13r$ 到原方程,通过多轮推导发现结果必须满足 $(1-r)^{10} = -1/13^{10}$,与原方程约束不符。直接证伪根映射。
- Validate(验证 - 韦达定理): 针对原方程,提取 $x^{10}$ 和 $x^9$ 的系数,发现求和并非 0。
- Verdict(结论): 逻辑不自洽,Verdict: Incorrect (True Negative)。
- Agentic Verifier(后向智能体)的工具表现: 在另一道代数展开题中,后向智能体从错误结论倒推,直接调用 `sympy`(Python 工具)展开多项式,发现真实系数与候选解答中的系数完全不匹配,当场驳回。
⚙️ 方法论与技术实现 (Methodology)
1. 双向智能体架构 (Bidirectional Agentic Verifier)
受数学证明策略启发,验证器分为两个独立协同的角色:
- 前向智能体 (Forward Agent): 执行充分性检查。遵循 "Plan-Validate-Verdict" 策略。首先规划出可验证的原子子步骤(Plan);接着对每个子步骤进行逻辑推演,并可调用 Python 解释器进行复杂的数值计算(Validate);最后全局汇总给出 True/False 判断(Verdict)。
- 后向智能体 (Backward Agent): 执行必要性检查。从最终答案反向追溯到问题条件,检查解法中的中间状态是否能够满足问题约束,专门用于捕捉“逻辑表面通顺但偏离题意”的解答。
2. AgentV-RL 训练配方
为了让单体 LLM 具备上述多智能体协同、多轮推理和工具调用的能力,作者设计了严密的训练管线:
第一阶段:合成轨迹数据构建与 SFT (Rejection Fine-Tuning)
利用提示工程引导基础模型生成带有工具调用的验证轨迹 $\mathcal{H}$。仅保留其预测结论 $\tilde{l}$ 与真实标签 $l$ 一致的高质量轨迹进行 SFT 训练。SFT 损失函数旨在对齐多轮决策行为,由于遮蔽了环境观察(工具返回结果),损失仅计算在策略生成的 action 和 thought 上:
$$ \mathcal{L} = -\mathbb{E}_{\tau \sim \mathcal{H}} \left[ \sum_{i=1}^{|\mathcal{H}|} \mathbb{I}[\tau_i \neq o_i] \cdot \log \pi_\theta (\tau_i | \mathcal{H}_{
第二阶段:群体相对策略优化 (GRPO)
为了进一步解锁自主探索能力并拉长验证视界,引入 GRPO 进行强化学习。对同一问题-解答对,使用当前策略采样 $G$ 条验证轨迹。奖励函数直接基于最终 Verdict 是否与 Ground Truth 匹配来给分:如果 $\tilde{l} = l$ 则 $r = 1$,否则 $r = -1$。优化目标为:
$$ \mathcal{J}_{GRPO}(\psi) = \mathbb{E} \left[ \frac{1}{G} \sum_{i=1}^G \sum_{t=1}^{|\mathcal{H}_i|} \min \left( \frac{\pi_\psi}{\pi_{old}} \hat{A}_{i,t}, \text{clip}\left(\frac{\pi_\psi}{\pi_{old}}, 1-\epsilon, 1+\epsilon\right) \hat{A}_{i,t} \right) - \beta D_{KL}(\pi_\psi || \pi_{ref}) \right] $$
📊 实验设置与结论分析 (Experiments & Results)
实验设置:基座模型选用 Qwen3-4B,在 MATH500, GSM8K, Gaokao2023, AIME24 等高难度数学基准上进行测试。评估场景分为 Best-of-N (BoN, 并行扩展) 和 Sequential Scaling (迭代修正)。
核心结论:
- 绝对性能碾压: 在 MATH500 (BoN@128) 上,Agentic-Verifier-Qwen3-4B 达到 79.0% 准确率,大幅领先 Skywork-V2-Llama-8B (53.8%) 甚至 70B 级别的 INF-ORM (55.4%)。在最具挑战的 AIME24 上,取得了 53.3% 的极高水平。
- 高效的迭代修复指南 (Critique Model): 在迭代修正场景下,模型输出的自然语言反馈极大地帮助了 Actor 纠正错误。第一轮交互中,Actor 在 MATH500 上的错误解答有 41.6% 被成功修正,而引入的降级错误(原本对的改错)仅有 0.6%。
- 消融实验揭示的机制:
- 双向检查缺一不可:前向或后向单独使用均有提升,但结合使用(Agentic Verifier)在 AIME24 等难题上表现最强。
- 工具至关重要:去除 Python 工具后性能有明显下降,证明外部计算锚定有效抑制了验证过程中的幻觉。
- 测试时计算力(Compute Scaling)法则:随着采样的验证轨迹数量增加,判别准确率单调提升。
🌟 关键技术亮点分析 (Expert Highlights)
从大模型对齐与推理系统架构的角度来看,本论文贡献了几个非常具有前瞻性的 insight:
- Verifier 的“智能体化 (Agentic)”是必然趋势: 随着 Generator/Actor 模型输出的 CoT 越来越长(如 o1-like 模型的几千 tokens),期待用一个静态的 ORM 甚至 PRM 一次性完成精准打分已经不现实。将 Verification 本身视为一个需要多步探索、验证的推理任务,是打破 Reward Model 能力瓶颈的核心解法。
- “双向验证”完美对应数学中的“充要条件”: 前向推导防范的是逻辑断层,后向倒推防范的是伪造前提。这种机制在算法层面逼迫 LLM 逃离自身的“上下文惯性”(Attention Drift),避免被生成的漂亮但不讲理的代码/公式洗脑。
- “RL for Verifier” 的闭环: 过去 RL 大多用于训练生成器(Actor)。本篇工作展示了通过 GRPO 优化带有工具调用的验证器轨迹,证明了 Verifier 自身也可以通过 RL 产生深刻的 System-2 思考。这为构建超越人类标注水平的超强自动化判别器(Super-human AI Judge)铺平了道路。
整合图、大语言模型与智能体:推理与检索的全面综述
Integrating Graphs, Large Language Models, and Agents: Reasoning and Retrieval
作者:Hamed Jelodar, Samita Bai, Mohammad Meymani, 等
机构:加拿大网络安全研究所,新不伦瑞克大学 (University of New Brunswick)
📄 查看 ArXiv 原文
📍 研究背景与痛点 (Background & Pain Points)
近年来,基于 Transformer 的大语言模型(LLMs)在自然语言理解和非结构化文本生成方面展现了极其强大的能力。然而,作为资深从业者,我们深知纯参数化的 LLM 在处理复杂逻辑、长逻辑链推理以及知识强依赖场景时,存在明显的局限性:
- 拓扑与关系建模的缺失: LLM 主要基于序列 Token 表示进行自回归计算,缺乏对结构化关系知识(如多跳依赖、实体拓扑)的显式建模机制(Inductive Bias)。这导致模型在需要严格关系推理的场景下极易产生幻觉(Hallucination)。
- 传统 RAG 的“扁平化”瓶颈: 传统的检索增强生成(RAG)依赖于向量相似度(Dense Retrieval),将检索到的文本块(Chunks)视为独立且扁平的段落。在面对复杂的组合型查询(Compositional Queries)或需要跨多篇文档进行逻辑连线时,传统 RAG 无法提供结构化的证据链。
- 图神经网络(GNN)的语义短板: 另一方面,虽然 GNN 擅长处理拓扑结构(如社交网络、知识图谱),但其对节点特征中蕴含的深层自然语言语义理解不足,且容易面临过平滑(Over-smoothing)问题。
因此,将图结构(Graphs)、大语言模型(LLMs)与智能体(Agents)进行深度融合,取长补短(结构化推理的严谨性 + 非结构化语义的泛化性),成为了当前 Gen-AI 走向可信、可解释决策系统的核心演进路径。
🚀 核心贡献 (Core Contributions)
本文是一篇极具参考价值的宏观综述,系统性地梳理了“图-大模型”融合的技术全景,为从业者提供了清晰的架构设计指南(When, Why, Where, and What):
- 构建统一的 Graph-LLM 融合分类法: 按照“功能角色分类”(图构建、图推理、图谱问答、场景图)、“图模态分类”(知识图谱、场景图、交互图、依赖图等)以及“集成策略”(Prompting、RAG、Training、Agentic)进行了详尽的解构。
- 深度剖析 Hybrid GNN-LLM 架构: 梳理了当前预训练、协同训练与单向增强(LLM4GNN vs GNN4LLM)的最新 SOTA 范式。
- 提出 Graph-Agent-LLM 新范式: 探讨了如何将图作为 Agent 的“记忆(Memory)”和“规划(Planning)”载体,推动多步复杂工作流的自动化。
- 落地场景映射: 详细评估了该技术栈在网络安全(恶意软件分析)、医疗(电子病历提取)、推荐系统及合规审计等领域的实际工程价值。
💡 具体案例剖析 (Case Studies)
为了直观展示 Graph-LLM 融合的威力,以下提取论文中提及的几个典型落地范例:
- Case 1: GraphRAG 在复杂知识图谱问答(KGQA)中的应用
输入查询: “在患有慢阻肺(COPD)且有心衰病史的患者中,哪种药物可能导致特定的不良反应链?”
纯 LLM/传统 RAG 处理: 往往只能召回“药物A与COPD相关的文档”或“药物A与心衰相关的文档”,LLM 需要隐式地将这些文档拼凑,极易因丢失上下文或逻辑链断裂而胡说八道。
GraphRAG 处理: 系统在检索阶段将外部知识建模为图。首先命中实体“COPD”和“Heart Failure”,随后执行图遍历(Graph Traversal)提取包含这两个节点及其多跳关系(如 ` -> [causes] -> -> [worsens] -> `)的子图(Subgraph)。
输出: LLM 基于严格的子图证据生成答案,完全消除了关系漂移。
- Case 2: 医疗电子病历 (EMR) 的 Agentic 图标注系统
输入文档: 一段非结构化的医生病历摘要:“患者持续咳嗽、发烧气短,有COPD病史,诊断为社区获得性肺炎,开始服用头孢曲松。”
Graph-Agent 处理: 临床 AI Agent 会将任务拆解。提取症状实体并映射到 ICD-10 图谱,在图谱的约束下进行实体消歧(Contextual Disambiguation),并通过验证模块(Verification Module)检查用药与诊断在图谱中的一致性。
输出结构化结果: 包含诊断编码(Pneumonia: ICD-10 J18.9)、并发症、风险等级及可解释性的推理链。
- Case 3: 网络安全中的恶意代码混淆检测(DeCoda 框架)
痛点: 恶意 JavaScript 代码常使用多态混淆,纯文本序列分析难以察觉。
Graph-LLM 方案: 先用 LLM 尝试对代码进行渐进式反混淆,转化为抽象语法树(ASTs)。随后,一个具备“节点-集群注意力(node-to-cluster attention)”的分层代码图模型捕捉全局结构关系。
效果: LLM 负责语义还原,图模型捕捉控制流异常,在测试中实现了高达 94-97% 的 F1 分数,远超传统基于 Token 的大模型方案。
⚙️ 方法论与技术实现 (Methodology & Architecture)
论文对两大基础架构的数学本质进行了对比,并提出了多种技术融合路径。大模型通过自回归机制计算序列联合概率:
$ P_\theta(\mathbf{x}) = \prod_{t=1}^{T} P_\theta(x_t \mid x_{
而 GNN 通过消息传递(Message Passing)显式捕获局部邻域信息并更新表征:
$ \mathbf{h}_v^{(l+1)} = \phi^{(l)} \left( \mathbf{h}_v^{(l)}, \bigoplus_{u \in \mathcal{N}(v)} \psi^{(l)}\left(\mathbf{h}_v^{(l)}, \mathbf{h}_u^{(l)}, \mathbf{e}_{uv}\right) \right) $
两者的融合可划分为以下几个核心范式:
1. LLM 辅助的图构建 (LLM-Assisted Graph Construction)
即 Text2KG。传统的多阶段流水线(NER -> RE -> EL -> Schema Alignment)需要大量标注数据且易发生级联错误。当前 SOTA 转向统一生成范式(Unified Generation),通过 Prompt 或 RAG 约束,LLM 可以端到端地输出 JSON/RDF 三元组。进阶做法包括零样本迭代构建(如使用 LLM 动态提取并反向验证幻觉)。
2. 图增强大模型推理 (Graph-Enhanced LLM Reasoning)
包含了如今大火的 GraphRAG 技术。它将检索单元从“孤立的文本块”升级为“关联的知识子图”。模型不再依赖隐式学习,而是通过硬提示(Hard Graph Prompting)、软提示图词表化(Soft Graph Tokenization)或路径指引推理(Path-Guided Inference)将显式的结构约束输入给 LLM。这种方法使得模型具备了多跳推理(Multi-hop inference)能力。
3. 混合 GNN-LLM 架构 (Hybrid GNN-LLM Models)
这是学术界目前最硬核的研究方向,分为四类耦合策略:
- 协作框架 (Collaboration Frameworks): 如 GLEM 框架,通过 EM 风格的优化算法,让 LLM 的伪标签和 GNN 的图表征进行双向迭代协同训练(Iterative Co-training)。
- 单向增强 (Directional Integrations):
- LLM4GNN: 利用 LLM 强大的特征提取能力为图的节点生成高质量的 Embedding,作为 GNN 的输入特征增强。
- GNN4LLM: GNN 充当大模型的检索器或图结构编码器,通过指令微调(Instruction Tuning)使得 LLM 可以“读懂”图结构(如 LLaGA 模型)。
- 图原生大模型 (Pre-trained Hybrid Architectures): 如 GOFA 或 GDL4LLM,在预训练阶段就将图计算与文本联合编码,将图结构直接融合到 LLM 的 Transformer 架构深处(Graph-as-language 或 GNN inside LLM)。
4. 场景图 (Scene Graphs) 与大语言模型
结合多模态(VLM),LLM 充当了推理、解析、规划和验证的大脑。在 2D/3D 甚至动态时间场景下,场景图将物理世界的物体属性与空间关系抽象化,LLM 基于此执行零样本导航(Zero-shot Navigation)、机器人任务规划甚至 3D 场景生成与编辑(如 SceneCraft)。
5. Graph-Agent-LLM 融合 (Agentic Reasoning)
将图作为智能体的情景与语义记忆库 (Episodic + Semantic Memory)。例如 LAFA 框架在联邦分析中,Agent 将复杂查询分解为有向无环图 (DAG) 格式的执行计划进行优化调度;而 X-GridAgent 利用规划层、协调层和动作层与领域特定图数据库交互,实现自动化电力网分析。
📊 实验设置与结论分析 (Experiments & Findings)
论文对当前领域的测试基准与实验结论进行了宏观总结:
- KGQA 任务上的跃升: 在 WebQSP、Complex Web Questions (CWQ) 以及金融/医疗垂直数据集上,集成了图结构约束的 LLM 框架(如 READS 或 GoG)通过剪枝子图和引入鉴别式推断策略,在答案准确率和长尾问题(Long-tail queries)的泛化能力上显著超过了 GPT-4 Baseline。
- 动态演化图处理: 实验表明,在零样本(Zero-shot)和少样本(Few-shot)的链路预测任务(如 WN18RR 和 NELL-995)中,通过将图路径转化为 Chain-of-Thought(CoT)式的自然语言 Prompt 对 LLM(如 LLaMA2, Gemma)进行指令微调,能够赋予模型强大的泛化图推理能力。
- Agent 编排效率: 通过采用 DAG 优化和带有 RAG+GNN 支持的图导航(例如 AgentBench 评测),多智能体系统在复杂任务成功率上大幅上升,同时极大减少了多余 API 调用的开销。
🌟 关键技术亮点分析 (Key Innovations & Challenges)
站在资深技术人员的视角,本综述揭示了当前 Graph-LLM 融合落地的几个关键亮点和未解难题(Open Challenges):
- 对齐问题 (Graph-LLM Alignment): 这是当前最棘手的问题。LLM 运作在潜变量的语言空间中,而图表示严格的、离散的实体拓扑关系。当前的融合往往依靠 Prompt 工程或简单的图序列化(Graph Serialization),导致 LLM 有时依旧会“无视”图中的边约束,发生“关系漂移”。未来的突破口在于结构感知的分词机制(Structure-aware tokenization)以及带有图一致性惩罚项的联合解码(Graph-constrained decoding)。
- 系统可扩展性 (Scalability Bottleneck): GraphRAG 在应对超大规模知识图谱(Web-scale KGs)时,提取多跳子图的计算成本极高。且动态更新图谱时,如何使得 LLM-GNN 协同系统免于完全重训(Incremental graph updates)是落地的大挑战。层次化图抽象(Hierarchical graph abstraction)是目前可见的解法。
- 解释性即护栏 (Explainability as Guardrails): 综述强烈指出,在网络安全和医疗等高优领域,图结构的引入不仅仅是为了提升准确率,更是作为 LLM 的强制护栏(Guardrails)。通过输出显式的检索路径(Reasoning trace extraction),实现了真正的 Trustworthy AI,这也是未来 Agentic Workflow 进入传统行业的刚需。
CoEvolve: Training LLM Agents via Agent-Data Mutual Evolution
作者:Shidong Yang, Ziyu Ma, Tongwen Huang, Yiming Hu, Yong Wang, Xiangxiang Chu
机构:AMAP, Alibaba Group (高德/阿里集团)
📄 查看 ArXiv 原文
1. 研究背景与核心痛点
强化学习(RL)已成为训练具身或软件环境交互式大语言模型(LLM Agent)的主流范式。然而,目前大多数Agent的训练重度依赖静态数据集(Static Data Distribution)。这种传统范式面临以下痛点:
- 高昂的专家数据成本与长尾覆盖缺失:通过人工专家操作收集环境轨迹极其昂贵,且静态切片难以覆盖真实世界的长尾变化和复杂边缘场景。
- 合成数据的“开环”缺陷:目前的合成数据(Synthetic Data)生成通常是开环(Open-loop)和弱适应性的,主要依赖前置LLM“无脑”的随机探索。生成的轨迹集依旧是静态语料库,无法随着Agent训练过程中的能力进化和暴露出的真实短板进行动态自适应补救。
2. 核心贡献
本论文提出了一种零人工干预的动态强化学习框架——CoEvolve(协同进化)。该框架使得Agent策略与其训练数据分布在闭环的交互反馈中实现“相互促进,共同演进”:
- 首创“Agent-数据相互演进”范式:通过Agent在训练过程中的交互试错,将环境反馈转化为新的、针对性强的数据,再用这些数据进一步迭代Agent。
- 基于反馈信号制导的探索机制:不同于无脑随机探索,CoEvolve创造性地从Rollout中提取行为层面的“弱点信号”(如遗忘、边界游移、罕见状态),通过LLM生成强针对性的探索任务。
- 在复杂Benchmark上获得巨大提升:在AppWorld和BFCL等复杂交互评测上,配合GRPO优化算法,使Qwen2.5/Qwen3等多个尺寸的开源模型实现了15%~19%的绝对精度飞跃,展现了极强的泛化和Scale up潜力。
3. 具体案例剖析 (Case Study)
为了直观理解CoEvolve是如何通过信号制导生成能够“压榨”Agent能力的复杂任务,我们可以参考论文附录中在AppWorld环境下的生成案例:
- 静态原始样本(Original Sample):
查询当前播放歌曲艺术家的粉丝数。
特性: 这是一个典型的短视距、几乎呈线性的工具调用任务(获取当前播放 -> 获取艺术家 -> 查询信息)。一旦最终状态达成即判定成功,对中间过程的约束较小。
- CoEvolve合成样本(Synthetic Sample):
“点赞Spotify播放队列中当前的所有歌曲,但前提是我以前没有点赞过”。
特性: 这是一个高度复杂的条件控制与状态追踪任务。Agent不仅需要处理密码鉴权,还需要分别拉取“播放队列”和“已点赞列表”,在工作流中实现中间变量存储、集合求差集(过滤已点赞),并最终执行循环操作进行点赞。这种任务大幅增加了交互轮数(从约8步拉长至11步以上),引入跨节点状态对齐,直接暴露且针对性修复了Agent在多步条件规划和正确性校验上的短板。
4. 方法论与技术实现
CoEvolve建立在一个支持训练时数据动态扩充的循环系统上,其基线优化算法采用最新的组相对策略优化(GRPO),优化目标如下:
$$ \mathcal{J}(\theta) = \frac{1}{\sum_{k=1}^K |\tau_k|} \sum_{k=1}^K \sum_{t=1}^{|\tau_k|} \text{CLIP}(r_{k,t}(\theta), \hat{A}_k, \epsilon) - \beta \cdot \mathbb{D}_{\text{KL}}[\pi_\theta \parallel \pi_{\text{ref}}] $$
在此基础上,整个演化过程分为三个关键Stage:
Stage 1: 训练与弱点信号提取 (Training and Signal Extraction)
在GRPO训练采样时,算法通过监控轨迹指标,实时捕获三种行为信号:
- Forgetting Signals(遗忘信号):Agent在过去窗口内对某类任务成功率较高,但在当前策略下突然失败的任务。这反映了训练中的灾难性遗忘。
- Boundary Signals(边界信号):同一个Query采样的一组输出(K个Trajectory)中,既有成功也有失败,说明Agent对该分布的掌握游走在决策边界上,极其不稳定。
- Rare Signals(罕见信号):触发频率低于设定阈值的动作模式,表明存在对长尾/随机事件的探索不足。
Stage 2: 信号制导的环境重探索 (Signal-Guided Environment Re-exploration)
首先由一个辅助LLM将提取到的带标注信号与历史轨迹转化为“探索上下文(Context)”,明确失败根因和重点探索方向。随后,LLM基于该上下文在真实环境中进行两个维度的正交展开:多轮探索(Multi-round)以提升多样性,多步探索(Multi-step)以确保观察-动作依赖反馈链的完整性。此阶段产出的是底层的步级别交互三元组(Step-level Triplets)。
Stage 3: 任务抽象与验证 (Task Abstraction and Validation)
把底层的杂乱Triplets直接喂给Agent显然是低效的。论文引入了抽象机制:由LLM将相关Triplets总结归纳出高层的“意图指令(Query)”和“黄金解法(Action Sequence)”。最核心的是环境验证(Environment Validation):新合成的任务必须在真实环境跑通验证(完成任务或取得正向Reward),才会被正式加入任务集 $D_t$ 中,这彻底过滤了LLM极易产生的“幻觉任务”,保证了闭环演进的稳定性。
5. 实验设置与结论分析
团队在具有高度复杂性的评测工具上进行了详尽测试,包括AppWorld(跨多App的长链条API调度)和BFCL-V3(Berkeley Function Calling的复杂工具链场景)。
- 大幅领先基础模型: 在引入CoEvolve后,基于Qwen2.5-7B的平均胜率提升了19.43%,Qwen3-4B提升15.58%,百亿级模型Qwen3-30B-A3B在AppWorld上的高难度挑战测试(TestC)TGC指标暴涨了+23.21%,甚至在多项指标上碾压DeepSeek-V3.2与Claude-Sonnet-4.5。
- 对比传统GRPO: 实验证明,单纯在静态数据上使用GRPO存在明显的上限天花板(表2中GRPO提升有限),而结合了闭环动态数据发现后,不仅保留了对之前成功Case的能力(不会遗忘),还能大幅修复失败Case(对BFCL修复了10%的先前错误案例)。
- 消融实验(信号拆解): 若移除Forgetting Signal,整体增益下跌最严重(约掉4个点),证明遗忘矫正在强化学习过程中的不可替代性;Boundary和Rare信号同样为拓展长尾场景和稳定能力边界提供了关键支撑。
6. 关键技术亮点分析
- RL中的“对症下药”范式转移: 传统的合成数据流水线通常独立于训练存在(即离线生成语料池)。CoEvolve将“出题者”(合成引擎)和“做题者”(Agent策略)耦合绑定,让Agent自己提供Failures作为“错题本”,真正实现了哪里薄弱打哪里,极大提高了训练效率,这对于未来Scaling RL具有重要启示。
- Ground Truth环境约束对抗幻觉: “合成数据的致命伤是偏离真实分布”。CoEvolve在Task Validation环节引入了强制的“环境闭环校验执行”。不能Run成功的Task一律丢弃,这相当于给数据演化加了一层物理/逻辑法则的硬约束,避免模型陷入自产自销的退化(Mode Collapse)。
- 轻量级开销撬动高杠杆: 实验显示,与纯静态GRPO训练相比,CoEvolve仅引入了额外不到10%到12%的时间开销(主要用于合成与执行校验),但带来了超20%的相对性能提升。这种极高的性价比证明了基于Feedback驱动探索在工业落地中的价值。
Experience Compression Spectrum: Unifying Memory, Skills, and Rules in LLM Agents
中文标题:经验压缩光谱:统一LLM Agent的记忆、技能与规则
作者:Xing Zhang, Guanghui Wang, Yanwei Cui, 等人
机构:AWS Generative AI Innovation Center, HSBC Holdings Plc.
📄 查看 ArXiv 原文
1. 研究背景与痛点 (Background & Pain Points)
随着 LLM Agent 从单次会话的 Demo 走向持久化、长周期的真实环境部署,Agent 积累的交互经验(Interaction traces)正呈指数级增长。一个每天处理数千个任务的 Agent,其产生的日志会迅速耗尽任何实际的 Context Window 或检索预算。管理这些经验知识成为了第一级的扩展性瓶颈。
当前业界主要有两个独立的研究社区在试图解决这一问题:
- Agent Memory 社区:侧重于提取和检索经验性的“情景片段”(如 Mem0, MemGPT)。
- Agent Skill 社区:侧重于从执行轨迹中发现和复用过程性的“操作技能”(如 Voyager)。
核心痛点:作者通过对22篇核心论文的1,136篇参考文献进行分析,发现这两个社区的交叉引用率不到 1%。这两个社区在各自的孤岛中独立解决了相同的基础子问题(如知识检索、冲突解决、陈旧数据清理)。此外,现有的系统都在单一、预设的压缩层级上运行,导致了“专业化有余而通用性不足”,无法实现根据经验积累动态改变抽象层级的自适应扩展。
2. 核心贡献 (Core Contributions)
本文没有提出一个具体的代码库或单一模型,而是提出了一个极具高屋建瓴视角的**统一架构框架**,具有深远的指导意义:
- 提出“经验压缩光谱” (Experience Compression Spectrum) 理论:将记忆(Memory)、技能(Skills)和规则(Rules)统一为对原始交互轨迹的单一“压缩”轴上的不同点。
- 揭示“缺失的对角线” (The Missing Diagonal):通过将当前 20+ 个主流 Agent 系统映射到光谱上,发现所有系统都固定在特定的压缩层级,完全缺乏跨层级的“自适应向上压缩/向下回退”能力。
- 系统性暴露结构盲区:量化了不同压缩层级的收益转移关系(Transferability vs. Specificity),并指出知识的“生命周期管理”(Lifecycle Management)在当前 Agent 研究中几乎被完全忽视。
- 定义未来架构设计原则:提出了构建全光谱、可伸缩 Agent 学习系统的三大设计原则和具体的 Open Problems。
3. 具体案例剖析 (Case Study: 跨层级动态演进)
为了具象化“缺失的对角线”到底应该怎么运作,作者给出了一个非常精彩的理想化客服 Agent(Customer-support Agent)演进案例,展示了知识如何在 L1 到 L3 之间双向流动:
场景设定:客服 Agent 处理 API 请求
- 阶段 1 (L1 Episodic Memory):Agent 在调用
/api/export 时遇到了 Timeout(超时)错误,它将这次具体的失败过程存为一个 L1 级别的记忆。
- 阶段 2 (L2 Procedural Skill 向上晋升):当系统积累了 5 次类似的 L1 记忆后,系统的“晋升引擎”触发,将这些记忆合并提取为一个 L2 级别的通用技能(Skill):
"HANDLE_EXPORT_TIMEOUT: 检查 Batch Size,如果大于 1000 行则减小 Batch 并重试。"
- 阶段 3 (L3 Declarative Rule 向上抽象):随着 Agent 在几十个不同的 Endpoint(不仅仅是 export)上都运用了类似策略,系统泛化出一条 L3 级别的领域陈述性规则:
"处理数据密集型 Endpoint 时,Timeout 通常源于过大的 Batch Size。"
- 阶段 4 (向下回退 Demotion):如果在某个极其特殊的全新上下文中,这条 L3 规则失效了,系统会自动回退(Demote),降级回 L1 模式,重新开始收集该特殊上下文的独立证据。
当前的系统只能做到其中一步(要么存记忆,要么写技能),而未来的架构应该像人类认知一样,实现上述全生命周期的流转。
4. 方法论与技术实现 (Methodology)
作者建立了一个形式化框架来描述经验压缩:
定义交互轨迹为 $\mathcal{T} = \{(s_t, a_t, o_t, f_t)\}_{t=1}^N$,包含状态、动作、观察和反馈。经验压缩函数定义为 $\mathcal{C}_L: \mathcal{T} \rightarrow \mathcal{K}_L$,其中 $L \in \{0, 1, 2, 3\}$ 代表压缩层级。
- Level 0 — Raw Trace(原始轨迹):1:1 比例。完整的对话日志和执行轨迹,无复用性。
- Level 1 — Episodic Memory(情景记忆):5–20倍压缩。以键值对或时间戳事件摘要的形式,保留了“发生了什么”,抛弃了冗余交互机制(如 Mem0)。
- Level 2 — Procedural Skill(过程技能):50–500倍压缩。抽象出“如何应对一类情况”,形成可复用的行为模式、代码片段或工作流模板(如 Voyager, SkillWeaver)。
- Level 3 — Declarative Rule(陈述性规则):1000倍以上压缩。提取“基于什么原则决策”,形成自然语言的全局策略或约束(目前该层级几乎空白,Constitutional AI 的规则是预设的,而非从 Agent 经验中提取)。
系统设计的三个属性权衡 (Trade-offs):
- 泛化性 vs. 特异性:压缩级别越高,知识泛化能力越强,但上下文细节越少。
- 压缩率 vs. 细节保留:高级别压缩通过语义抽象丢弃背景噪声(如 Mem0 从 26k Token 压到 1.8k Token)。
- 获取成本 vs. 维护成本:获取一条 L1 记忆很便宜,但大规模部署时维护/检索 L1 的成本是线性的且极高。L3 规则提取需要大量算力,但一旦成型,在千百次调用中维护和检索成本极低。
5. 实验设置与结论分析 (Experiments & Analysis)
作为一篇 Meta-Analysis 导向的论文,作者通过横向对比各顶级顶会的实证结果,提炼出了对 Agent Scaffold 系统开发至关重要的结论:
- 技能的下游性能表现压倒单纯记忆检索:在汇总的表格中(如 SkillRL 在 ALFWorld 测试集),使用 L2 技能比使用 L1 轨迹检索的任务成功率高出 +68.5%。Trace2Skill 的实证也显示提取后的技能显著优于人类手写技能(+21.5%)。
- 评估方法的严重耦合(Level-Coupled):目前 L1 系统倾向于用 QA 的 F1 Score 评估,而 L2 倾向于用任务成功率评估。这种指标割裂掩盖了知识资产对 Agent 全局效率的真实下游影响。
- 跨模型和跨任务迁移:实证支持一种“凹曲线”(Concave Curve)关系,即 L2 处于转移性和特异性的 Sweet Spot(最佳击球点)。例如,Trace2Skill 证明在 35B 参数模型上获取的 L2 技能可以直接迁移提升 122B 模型的能力(+57.7%)。
6. 关键技术亮点分析 (Key Highlights & Open Problems)
对于深入 Agent 架构设计的工程师和研究者,本文指出了极具商业和研究价值的未来方向:
- 摒弃固定层级,拥抱 Meta-Controller:未来架构必须解决“自适应层级选择”问题。Agent 不应只学习“提取什么”,而是要根据信息的价值(Value-of-information,未来的效用收益是否大于算力/维护成本)来学习“在哪个层级提取”。
- 系统级的生命周期治理 (Lifecycle Governance):软件工程领域的版本控制思想必须引入 Agent 知识库中。每一条 Memory/Skill/Rule 都必须带有元数据(数据溯源、置信度、使用频率、最后验证时间),建立“最小可塑性”(minimum plasticity)原则——只有在充分证据支持时才触发知识层级的升级,并在检测到策略退化时进行自动化废弃(Deprecation)。
- 闲时合并 (Idle-time Consolidation) 假说:作者从认知科学(互补学习系统 CLS,海马体到新皮层的巩固)汲取灵感,提出向上压缩(L1 → L2 → L3)不应在推断流中同步发生,而应在系统的低活跃期(类似睡眠时间)异步执行,这直接为多节点 Agent 集群的算力调度提供了架构级思路。