SpecRLBench: 规范引导强化学习的泛化性评估基准
SpecRLBench: A Benchmark for Generalization in Specification-Guided Reinforcement Learning
作者:Zijian Guo, İlker Işık, H. M. Sabbir Ahmad, Wenchao Li
机构:波士顿大学 (Boston University)
💡 研究背景与痛点 (Background & Motivation)
在强化学习(RL)领域,让智能体执行具备长期时序逻辑约束的复杂任务一直是一个核心挑战(例如:“按特定顺序到达多个目标区域,同时始终避开危险区域”)。为了描述这类任务,当前主要有两种路线:
- 自然语言指令 (Natural Language Instructions):虽然灵活直观(常用于如 CALVIN 等基准),但语言存在固有的歧义性,缺乏精确的语义定义,导致策略解释和严格的安全性验证变得极其困难。
- 形式化规范 (Formal Specifications):采用如线性时序逻辑(Linear Temporal Logic, LTL)来提供精确、无歧义的任务描述。它能将复杂的长期目标和安全性约束编码为严格的逻辑公式。
核心痛点:尽管基于规范引导的强化学习(Specification-Guided RL)日益受到关注,但该领域缺乏一个标准化的、用于评估模型泛化能力的 Benchmark。现有的方法大多在孤立的、单一的环境中进行评估,缺乏对未知规范(Unseen Specifications)、环境动态变化、不同机器人本体(Embodiments)以及多智能体协同等维度的系统性测试,严重阻碍了该方向算法的横向对比与演进。
🚀 核心贡献 (Core Contributions)
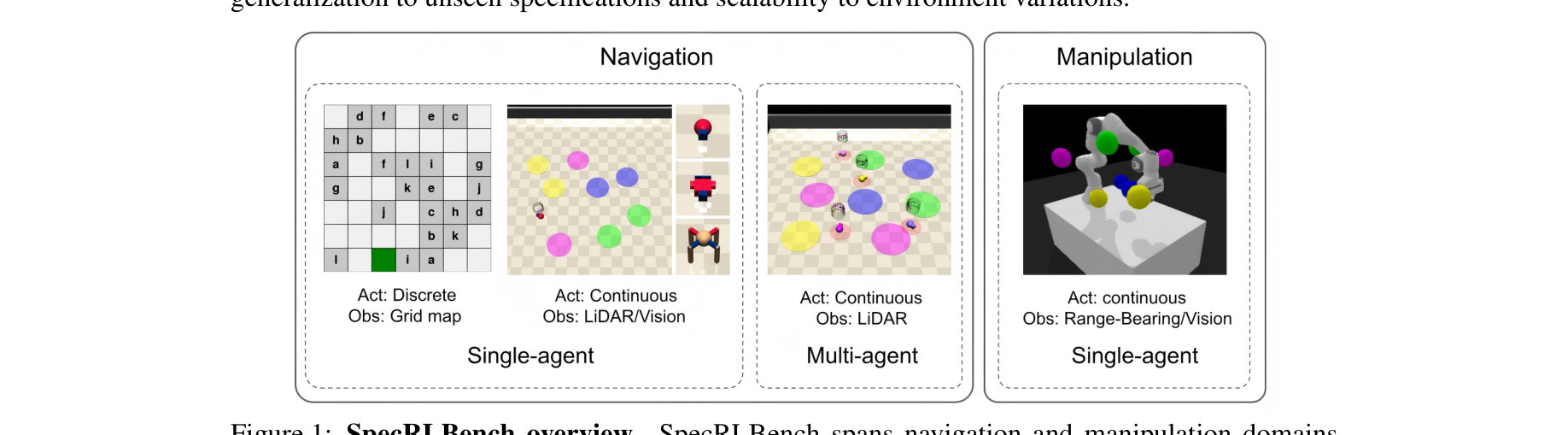
本文提出了 SpecRLBench,这是第一个专门为评估基于 LTL 形式化规范的 RL 泛化能力而设计的综合性基准测试集。其核心贡献包括:
- 多维度环境矩阵:包含 19 个环境变体,覆盖导航(Navigation)与机械臂操作(Manipulation)两大核心领域,支持离散与连续控制空间。
- 丰富的环境复杂度变化:支持静态与动态环境(如移动的避障区域)、多模态观测输入(网格、LiDAR、视觉图像、测距方位等),以及包括 Point, Car, Ant 等多种机器人动力学模型。
- 完善的泛化性评估体系:构建了涵盖“分布内(IND) vs 分布外(OOD)”、“有限期(Finite-horizon) vs 无限期(Infinite-horizon)”、“单智能体(Single-agent) vs 多智能体(Multi-agent)”等维度的评测任务集。
- 标准化的 Gymnasium 接口:环境设计完全兼容 Gym API,状态空间被解耦为“命题相关(Proposition-dependent)”与“命题无关(Proposition-independent)”两部分,便于现有算法的快速接入。
🔍 具体案例剖析 (Case Study)
为验证智能体是否真正理解了 LTL 的逻辑组合,SpecRLBench 提供了具有复杂时序深度的规范示例。例如在 Zone 环境(多颜色区域导航)中:
- 有限期安全到达 (Reach-avoid, IND):
公式:$\neg (c \lor d) \cup ((\neg e \cup l) \land (\text{F } g))$
含义:在到达由 $l$ 指定的目标并最终到达 $g$ 之前,绝对不能触碰区域 $c$ 或 $d$;同时在到达 $l$ 之前不能触碰 $e$。 - 多智能体协作 (Multi-agent Cooperative):
公式:$\text{F} ((b_0 \land b_1) \land (\neg(m_0 \lor m_1) \cup ((y_0 \land y_1) \land \text{F} (g_0 \land g_1))))$
含义:智能体 0 和 1 必须合作,最终同时到达区域 $b$;且在同时到达 $y$ 区域并进而同时到达 $g$ 区域之前,两者都必须避开区域 $m$。 - 无限期重复与持久性 (Infinite-horizon Recurrence & Persistence):
公式:$(\text{G F } b) \land (\text{G F } g) \land \text{G} \neg(y \lor m)$
含义:智能体需要无限次地交替访问区域 $b$ 和 $g$,同时在整个生命周期内永远避开区域 $y$ 和 $m$。
现象剖析:从论文给出的轨迹可视化可以看出,面对复杂的 Reach-Avoid 任务 $\neg(g \lor y) \cup (m \land (\neg g \cup b))$,部分 Baseline (如 LTL2Action) 的智能体不仅走出了低效的轨迹,甚至直接穿过了绿色 ($g$) 和黄色 ($y$) 的违规区域;而显式建模安全约束的 GenZ-LTL 则能规划出一条完全合规且更为紧凑的路径。
🛠 方法论与技术实现 (Methodology & Implementation)
SpecRLBench 将基于规范的强化学习建模为带有标签函数(Labeling Function)的马尔可夫决策过程 (MDP):$\mathcal{M} := (\mathcal{S}, \mathcal{A}, P, r, \gamma, d_0)$。
1. LTL 语义与标签系统:
环境实现了一个底层的标签映射 $L: \mathcal{S} \rightarrow 2^{AP}$,在每个时间步计算并返回当前状态满足的原子命题集合(Atomic Propositions, AP)。例如,在机械臂任务中,AP 包含 `grippers_green`(夹爪碰到绿区)或 `arm_blue`(机械臂本体碰到蓝区),支持不同细粒度的时序约束检测。
2. 观测空间解耦设计:
为了不绑定特定的网络架构,基准测试的 Observation 被结构化为两部分:
- $s_{AP}$ (命题相关):如彩色目标区域的位置、相对距离或视觉图像,对应外部任务环境的感知。
- $s_{\neq AP}$ (命题无关):如智能体的本体感受(Proprioceptive)或运动学特征(关节角度、速度等),对应机器人内在状态。
3. 奖励机制的开放性:
SpecRLBench 在默认配置下提供 0 奖励,旨在测试算法本身的 内在奖励塑造(Reward Shaping)能力 或 目标达成率验证。环境返回 Ground-truth 命题赋值,用户可以根据自身算法灵活构建基于自动机 (Automaton) 的奖励函数机制。
📊 实验设置与结论分析 (Experiments & Analysis)
作者评测了五个代表性的基于 LTL 的前沿强化学习基线模型:LTL2Action, GCRL-LTL, DeepLTL, GenZ-LTL, RAD-Embeddings。评测指标包括成功率 $\eta_s$、违规率 $\eta_v$(违反安全约束)、平均步数 $\mu$ 等。
- 分布外泛化能力 (OOD Generalization):从训练分布 (IND) 转移到未见过的 LTL 公式 (OOD) 时,所有模型都出现了显著的性能退化(成功率暴跌,违规率上升)。这表明当前利用句法树或自动机提取子目标的表征方法,在面对未见过的新型组合逻辑或更长序列时非常脆弱。
- 无限期安全约束维持 (Infinite-horizon Tasks):在包含持久性 ($\text{G }\neg\alpha$) 的无限期任务中,大多数 Baseline(如使用启发式阈值的 GCRL-LTL 和 DeepLTL)的违规率大幅上升。只有显式将安全条件视为硬约束的 GenZ-LTL 能够保持极低的违规率。
- 规范复杂度扩展 (Scaling with Complexity):通过增加目标序列长度和析取($\lor$,即多选一路径)的数量来测试。实验发现,序列变长导致 LTL2Action、DeepLTL 的成功率快速衰减;且析取数量增多导致探索空间爆炸,大部分模型的路径规划步数远不及基于 Dijkstra 算法计算的最优步数。
- 多智能体部署困境:将单智能体策略零样本直接扩展到多智能体环境时,由于缺乏协作机制,模型无法进行最佳的任务分解和路径分配(例如难以处理需两个智能体“同时”到达某地的协同规范),导致合作(Cooperative)和混合(Mixed)规范的达成率堪忧。
🌟 关键技术亮点分析 (Technical Highlights & Takeaways)
- 填补生态空白:相比于 Meta-World 或 CALVIN 等关注“单步物理目标”或“自然语言泛化”的基准,SpecRLBench 准确命中了“严格形式化逻辑+长期时序依赖+连续控制”这一交叉领域痛点,为 Neuro-Symbolic RL 提供了一个急需的统一考场。
- 暴露现有算法的致命弱点:实验深刻揭示了目前所谓“懂 LTL”的 RL 算法,很多只是过拟合了训练集中的逻辑结构。当面临分布外的状态自动机图结构变化,或需要无限期“抑制”(即不违规)时,表征学习能力和探索策略面临崩溃。
- 指明了多智能体+时序逻辑的广阔空间:论文验证了基于自动机全局状态的多智能体协同分解仍是未解难题,传统的将全局 LTL embedding 喂给单个智能体的做法极为低效,这为接下来的 MARL 提出了极佳的挑战方向。