基于蒙特卡洛树搜索的 Agent Skills 双层优化框架
Bilevel Optimization of Agent Skills via Monte Carlo Tree Search
机构:新加坡国立大学 (NUS), 加州大学伯克利分校 (UC Berkeley), 香港中文大学 (CUHK)
作者:Chenyi Huang, Haoting Zhang, Jingxu Xu, Zeyu Zheng, Yunduan Lin
📄 查看 ArXiv 原文
💡 研究背景与痛点
在大语言模型(LLM)的工程实践中,为了让 Agent 在特定复杂任务上表现更好,业界越来越倾向于使用 Agent Skills。这不仅是一段系统提示词,而是一个以特定目录结构组织的“能力包”。一个标准的 Skill 通常包含指令文档(SKILL.md)、工具代码脚本(scripts/)、辅助参考资料(references/)和静态资源(assets/)。
然而,如何系统性地迭代和优化这些 Skills 成了新的痛点:
- 异构且高度耦合: Skill 中的各个组件互相依赖。修改一行 Prompt 可能会导致某个外挂脚本失效。
- 搜索空间离散且约束多: 优化过程不仅要修改具体的文字或代码,还要调整整个架构,并受到文件大小、渐进式加载等约束。
- 评价信噪比低: 对于生成式组件,单次 Evaluation 结果通常波动极大,很难判断一次修改是否真正带来泛化提升。
传统针对纯文本或纯代码的优化方法难以直接应用。本文把 Skill 优化解耦为架构搜索与内容精炼两个层面。
🚀 核心贡献
- 宏观结构探索: 将 Skill 的结构变化建模为决策树,引入 MCTS 搜索不同的组织架构路径。
- 微观内容精炼: 在外层敲定结构后,内层依据改动类型触发特定家族的 LLM 内容重写和微调。
- 悲观置信度截断: 引入基于下置信界(LCB)的验收准则,降低自评噪音,保证优化稳步前进。
🔍 具体案例剖析
论文以 ORQA(运筹学问答) 为例。任务要求 Agent 根据业务描述判断正确的运筹学建模方式。
输入示例: 一家广播网络必须选择播出哪些节目,每个节目有时长、截止日期和收视率,目标是在约束下最大化总收视率。问题:决策活动是什么?选项:(A) 截止日期 (B) 节目播放顺序 (C) 节目播放指示器 (D) 处理时间。答案:(C)。
优化前: 核心分类指南放在外挂 references/,Agent 经常漏看,分类错误。
优化后: MCTS 发现 reference 外置会导致检索脱节,于是把分类指导合并回 SKILL.md,新增前置的 Question-Type Triage Checklist,并把输出约束写得更硬。
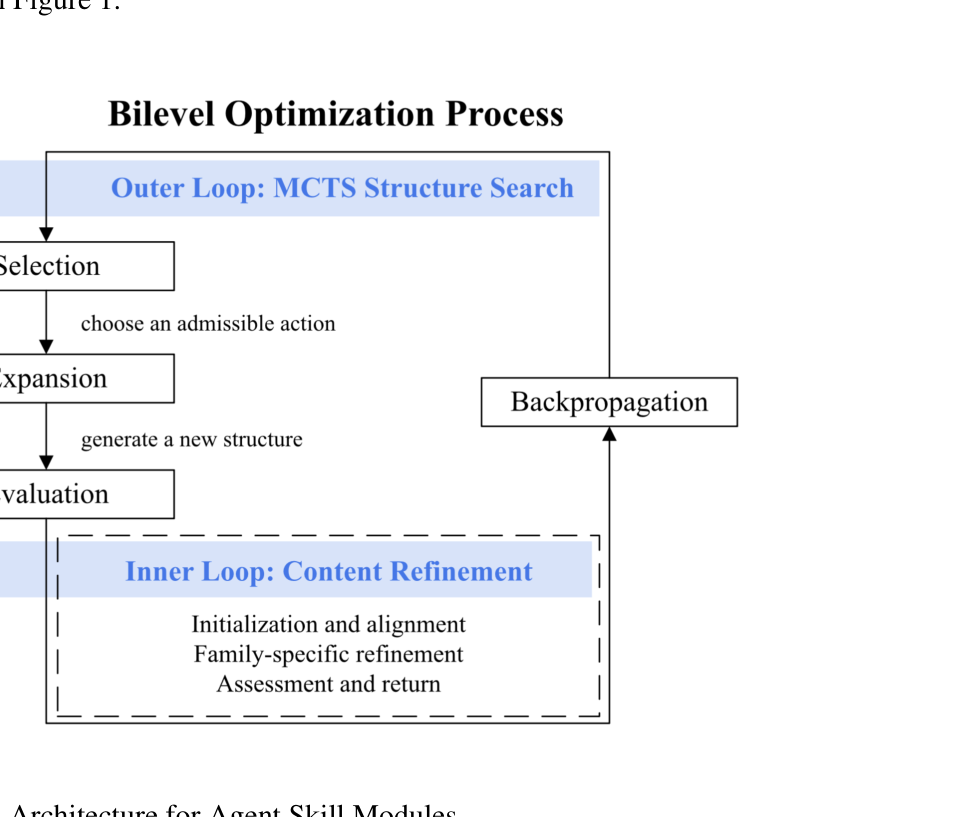 图注:Agent Skill 的双层优化架构。Outer Loop 用 MCTS 搜索结构,Inner Loop 负责具体内容精炼。
图注:Agent Skill 的双层优化架构。Outer Loop 用 MCTS 搜索结构,Inner Loop 负责具体内容精炼。
⚙️ 方法论与技术实现
论文将 Skill 表示为元组 $S=(\theta,\phi)$,其中 $\theta$ 表示结构配置,$\phi$ 表示该结构下的具体内容。目标是:
$$ \max_{\theta \in \Theta} \max_{\phi \in \Phi(\theta)} R_{S_0}(\theta, \phi) $$
外层 MCTS 完成 Selection / Expansion / Evaluation / Backpropagation 四步;内层则进行内容迁移、家族化精炼以及基于 $LCB=\bar{\delta}-t_{crit}\frac{s}{\sqrt{k}}$ 的悲观验收。
📊 实验设置与结论分析
- 数据: ORQA,共 1513 题,切分为 Search / Confirm / Test。
- 模型: 优化器使用
gpt-5.4,运行时评测模型使用 gpt-5.2-codex。
- 结果: 原始 Seed Skill 的精确匹配得分为
0.90625,优化后达到 0.9375,绝对提升约 3.1%。
🌟 关键技术亮点分析
- 把 Skill 当作软件工程产物来优化: 不再只调 Prompt,而是把多文件结构、加载方式、脚本和说明共同纳入搜索。
- 双层设计很实用: 先定结构,再做内容,能避免大规模重写时的灾难性遗忘。
- LCB 防暴走: 用统计下界筛掉噪音改动,是 Auto-Prompt / Auto-Agentic 系统很值得抄的工程技巧。
Agent-World: 扩展真实世界环境合成,演进通用Agent智能
英文标题:Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
作者:Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, 等
机构:中国人民大学、字节跳动 Seed
📄 查看 ArXiv 原文
研究背景与痛点
当前通用 Agent 训练面临两个硬伤:一是可交互、可验证、可扩展的真实世界环境极其稀缺;二是大多数 Agent RL 仍停留在静态环境或静态数据集,缺乏自我演进能力。
手工搭环境太贵,而让 LLM 直接“幻想”环境又会导致严重幻觉,无法逼真反映真实状态转移逻辑。
核心贡献
- 提出 Agent-World,把“真实环境合成”和“持续自我演进训练”打通。
- 构建了 1978 个环境、19822 个真实可执行工具组成的大规模生态。
- 结合多环境 GRPO 与动态诊断竞技场,在 23 个基准上显著提升 Agent 能力。
具体案例剖析
论文给出电商 MCP Server 的退货案例:Agent 需要先做身份验证,再枚举订单、判断已送达且可退商品、确认退款方式,最后真正提交退货动作并修改数据库状态。
这类任务不是“会说就行”,而是必须让数据库真实变成 return requested,所以奖励更接近工业级在线任务。
 图注:Agent-World 的持续自我演进闭环,上半部分是多环境强化学习,下半部分是自动诊断与针对性任务生成。
图注:Agent-World 的持续自我演进闭环,上半部分是多环境强化学习,下半部分是自动诊断与针对性任务生成。
方法论与技术实现
框架包含两块:一是 Agentic Environment-Task Discovery,从真实 MCP、API 文档、PRD 中挖掘环境并生成可验证任务;二是 Continuous Self-Evolving Training,把环境放入动态 POMDP 中,用 GRPO 在多环境上做训练。
奖励设计不是字符串匹配,而是代码/数据库状态验证。对于图任务与程序任务分别用不同验证器,保证 reward 真正对齐外部世界状态。
实验设置与结论分析
- 在 MCP-Mark、BFCL V4、τ-Bench 等多项基准上,Agent-World-8B/14B 显著优于同规模基线。
- 环境规模从 10 扩到 2000 时,平均准确率从 18.4% 提升到 38.5%。
- 随着 self-evolution 轮数增加,复杂任务表现持续上涨,说明“诊断 → 造更难数据 → 再训练”的闭环是有效的。
关键技术亮点分析
- Execution Grounding: 从“幻想环境”转向真实数据库和工具调用,是 Agent 训练范式的重要跃迁。
- RLVR 深化: 代码验证型奖励比偏好打分更适合长视野工具任务。
- 自动课程学习: 通过失败轨迹诊断生成对抗性新任务,形成真正的数据-策略共演化。
ResRL:通过负样本投影残差强化学习提升大语言模型推理能力
英文标题:ResRL: Boosting LLM Reasoning via Negative Sample Projection Residual Reinforcement Learning
作者:Zihan Lin, Xiaohan Wang, Jie Cao 等
机构:美团、中国科学院自动化研究所等
📄 查看 ArXiv 原文
研究背景与痛点
RLVR 已经成为提升 LLM 推理的重要后训练范式,但典型问题是模式坍缩:模型为了追求高 reward,生成越来越单一,Pass@k 和泛化能力下降。
已有方法 NSR 试图通过惩罚负样本维持多样性,但正负样本早期往往共享合理前缀,盲目惩罚会破坏本来正确的推理部分,形成严重梯度冲突。
核心贡献
- 提出 ResRL,只惩罚负样本中偏离正确语义子空间的“错误独有成分”。
- 通过单次前向传播估计几何代理,低成本实现梯度解耦。
- 在数学、代码、Agent、函数调用等 12 个基准上同时提升准确率与多样性。
具体案例剖析
在 Humaneval+ 中,ResRL 对同一题目可以生成暴力枚举和排序+扫描两种完全不同的解法;在数学题中也会保留不同推导风格,而不是坍缩成单一路径。
这说明它保住的不是表面措辞多样性,而是“多条通向正确答案的高价值思路”。
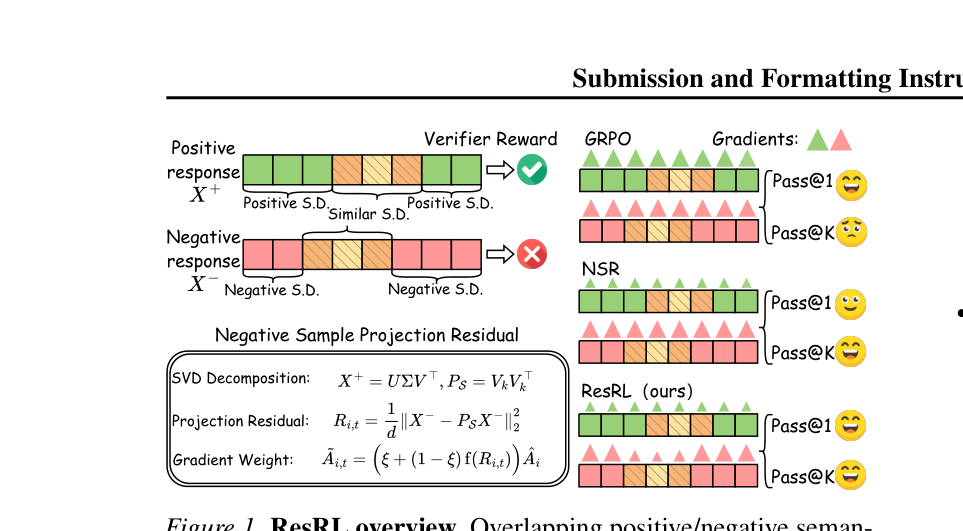 图注:ResRL 通过 SVD 构造正样本语义子空间,再根据负样本的投影残差动态调节惩罚强度。
图注:ResRL 通过 SVD 构造正样本语义子空间,再根据负样本的投影残差动态调节惩罚强度。
方法论与技术实现
作者使用倒数第二层隐状态 $h_{i,t}$ 作为语义表示,对正样本做中心化和截断 SVD,得到正子空间投影矩阵 $P_S$。对负样本计算残差能量:
$$ \mathcal{R}_{i,t}=\frac{1}{d}\|(I-P_S)x^-_{i,t}\|_2^2 $$
残差越大,说明越偏离正确语义,负向权重越强;残差越小,说明与正样本共享合理前缀,应该弱化惩罚。最终用加权 Advantage 进入 GRPO 更新。
实验设置与结论分析
- 在 AIME24 上,Avg@16 相比 NSR 提升显著。
- 在 Codeforces 上刷新同规模模型纪录。
- 在 ALFWorld 等长轨迹 Agent 任务中,优势尤其明显,因为这类任务最怕破坏共享正确前缀。
关键技术亮点分析
- Token 级负权重: 从 trajectory-level 深入到 token-level,是这篇论文最值钱的地方。
- 效果与算力平衡: 用 SVD 的低秩几何结构换来可落地的复杂度。
- 隐藏层选择有洞见: 倒数第二层比最后一层更适合做语义对齐,这个经验很有复用价值。
基于大语言模型多智能体系统的强化学习:一种编排轨迹视角
英文标题:Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces
作者:Chenchen Zhang
机构:Independent Researcher
📄 查看 ArXiv 原文
研究背景与痛点
单智能体 RL 优化的是线性 trajectory,但 LLM 多智能体系统优化的是系统编排:什么时候 spawn 子 Agent、如何分工、如何通信、如何聚合、何时停止。
这让经典 MARL 的前提基本失效:动作是开放自然语言、智能体数量动态变化、通信是自由格式且异步,导致信用分配和训练稳定性都变得极难。
核心贡献
- 提出用 Orchestration Trace 取代传统 Trajectory 作为核心优化对象。
- 建立奖励设计、信用分配、编排学习三大 taxonomy。
- 系统总结工业界与学术界之间的 scale gap,并提炼 15 个开放问题。
具体案例剖析
论文以 Kimi PARL 为代表案例,说明 Orchestrator 的 reward 不只是结果正确性,还包括并行加速和反伪并行惩罚:
$r_{orch}=r_{perf}+\lambda_1 r_{parallel}+\lambda_2 r_{finish}$
重点是这些辅助奖励需要在训练后期退火,不然系统会学会“刷并行度”而不是做好任务。
方法论与技术实现
作者把经典 Dec-POMDP 扩展为 Dynamic-Dec-POMDP,允许智能体数量和联合动作空间随编排动态变化。价值函数不再基于固定状态,而是定义在 trace prefix 上:
$$V^\pi(G_{\le t})=\mathbb{E}_\pi[\sum_{\tau\ge t}\gamma^{\tau-t}r_\tau\mid G_{\le t}]$$
论文还系统梳理了 Team / Orchestrator / Role / Agent / Turn / Message / Tool / Token 八层信用承载结构。
实验与工程分析
这篇更像 position paper,不是给出单一算法指标,而是揭示三大工业限制:多 Agent rollout 成本极高、部署 harness 限制真实可学习动作空间、现有 benchmark 过度关注 success rate 而忽略协调质量与并发效率。
关键技术亮点分析
- 从一维轨迹到时态图: 是对 LLM-MAS RL 问题定义本身的升级。
- 奖励-信用对偶性: 奖励越稀疏,信用分配越难;奖励越密集,reward hacking 风险越大。
- 工程洞察很强: 真正限制多 Agent RL 的往往不是算法 paper,而是 rollout 与 harness 成本。
OpenSeeker-v2:用高信息量与高难度轨迹突破搜索智能体的极限
英文标题:OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
作者:Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang 等
机构:上海交通大学
📄 查看 ArXiv 原文
研究背景与痛点
深度搜索已经成为前沿 LLM Agent 的核心能力,但工业界通常依赖 CPT→SFT→RL 的重型训练管线,门槛极高,开源社区难以复现。
本文的核心反问很直接:如果训练数据足够难、足够有信息量,是否只靠 SFT 就能把 Search Agent 做到很强?
核心贡献
- 提出 OpenSeeker-v2,证明高质量长轨迹 SFT 数据就足以支撑 SOTA 级 Search Agent。
- 通过扩大图谱规模、扩展工具集、严格过滤低步数轨迹三招提升数据难度。
- 只用 10.6k 训练样本,就在多个深度搜索 benchmark 上超过一些重型工业训练方案。
具体案例剖析
论文的关键证据是轨迹统计特征:训练集中平均每条 trajectory 需要执行 64.67 次 tool-call,显著高于前代与对比方法。
这意味着模型不是在学浅层关键词检索,而是在学真正的多跳检索、证据汇聚、失败回退与替代路径探索。
方法论与技术实现
作者围绕数据合成 pipeline 做三项核心改进:
- 扩大图谱规模: 从更大的子图中生成 query,强制任务天然具备多跳依赖。
- 扩展工具集: 让 trajectory 更复杂,促使 Agent 学习更丰富的交互模式。
- 严格低步数过滤: 只保留足够长、足够难的轨迹。形式上可写作:$$ \mathcal{D}_{v2}=\{(q,\tau)\in\mathcal{D}_{raw}\mid T(\tau)\ge T_{min}\} $$
这篇论文没有强制要求插图,我也没有从 PDF 中稳定拿到“足够代表全方法”的高质量架构图,因此这里不放图,避免污染页面质量。
实验设置与结论分析
- 基座模型:
Qwen3-30B-A3B-Thinking-2507,上下文窗口 256k。
- 训练方式:纯 SFT,无 RL。
- 结果:在 BrowseComp、BrowseComp-ZH、HLE、xbench-DeepSearch 等榜单上表现非常强,并超过部分采用 CPT+SFT+RL 的工业方案。
关键技术亮点分析
- 再次证明数据质量比花哨 pipeline 更重要。
- “先造难题再训练” 对搜索 Agent 特别有效。
- 对开源社区友好: 无需预训练、无需 RL,也能做出很强的搜索智能体。