BALAR : A Bayesian Agentic Loop for Active Reasoning
中文标题:BALAR:一种面向主动推理的贝叶斯 Agent 外循环
作者:Aymen Echarghaoui, Dongxia Wu, Emily B. Fox
机构:Stanford University
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文解决的是一个很典型但一直被低估的问题:当用户问题本身信息严重不足时,LLM 系统到底应该如何“主动地问对问题”,而不是被动地继续胡乱推理。传统的 ReAct、ToT 或纯对话式 agent,大多只擅长在已有信息上做规划,却不擅长显式建模“不确定性来自哪里、下一问能消掉多少不确定性”。
作者把这个问题 formalize 成 latent state inference:用户当前任务背后存在一个隐变量状态 $\theta$,系统必须通过若干轮高价值澄清问题,把 posterior belief 逐步收缩到足够确定的区域。这种视角对医疗问诊、侦探推理、客服定位问题都非常自然。
核心贡献
- 提出 training-free 的 Bayesian outer-loop,显式维护对 latent task state 的 belief 分布。
- 用 Mutual Information 选下一问,而不是让 LLM 凭感觉问问题。
- 提出 EXPAND 机制:发现当前状态空间不够时,动态扩展新的澄清维度。
- 在 AR-Bench-DC、AR-Bench-SP、iCraft-MD 上显著优于 baselines,说明“会问问题”本身就是核心能力。
具体案例剖析
输入案例:用户只说“我最近一直头痛”。这在临床上几乎没有可直接诊断的信息量。
BALAR 不会立刻给出诊断,而是先在 sleep-time 阶段构造潜在维度,例如:血管性/非血管性、偶发/慢性、是否伴随 autonomic features。然后用互信息选择最高价值问题,比如“疼痛是否伴随搏动感?”
输出路径:如果用户回答“像脑子里在打鼓一样一阵一阵地疼”,系统会把自由文本 soft-map 到预定义选项分布,再做 Bayesian update,使 vascular headache 的 posterior 快速上升。若剩余问题预算不足以区分 migraine 与 cluster headache,系统再动态增加新维度继续问。
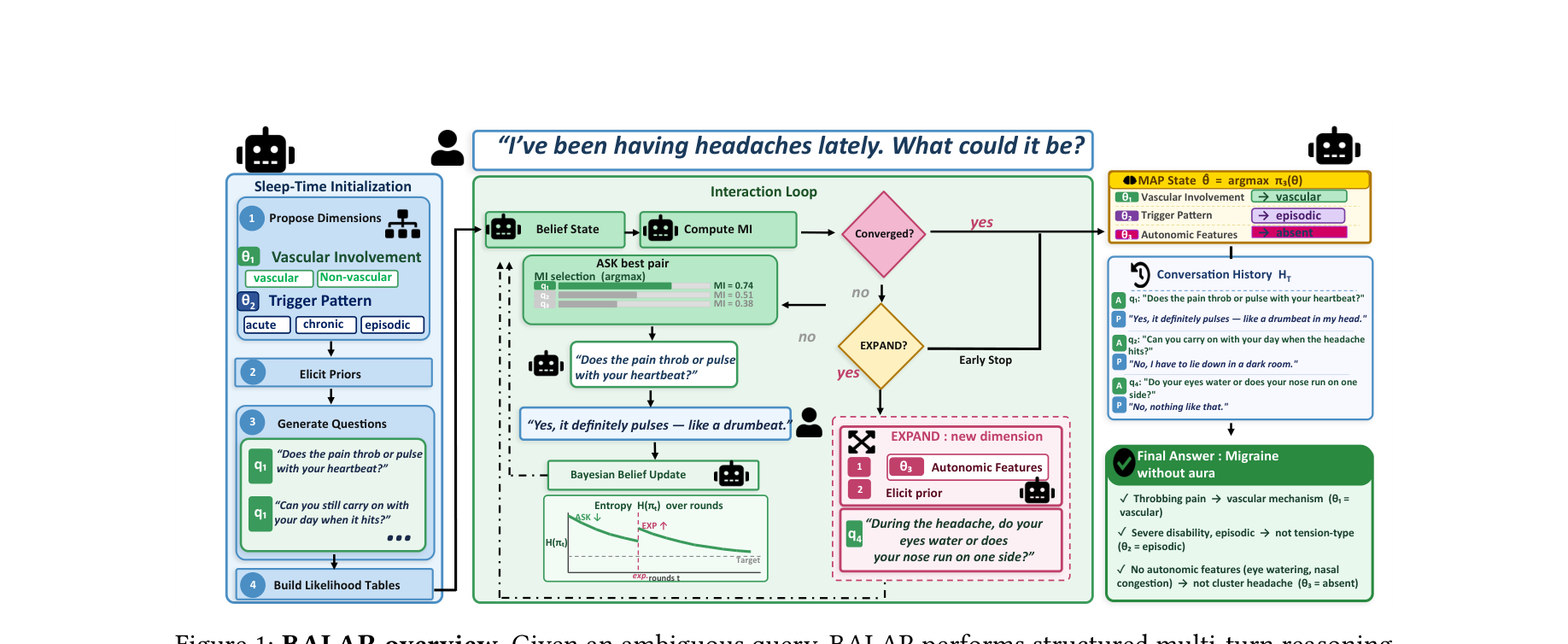 图注:BALAR 的核心是把“主动提问”形式化为 belief-state 收缩问题:先构建潜在状态空间,再用互信息挑选问题,并在必要时扩展新的状态维度。
图注:BALAR 的核心是把“主动提问”形式化为 belief-state 收缩问题:先构建潜在状态空间,再用互信息挑选问题,并在必要时扩展新的状态维度。
方法论与技术实现
初始 belief 记为 $\pi_0(\theta)$。第 $t$ 轮的熵为:
$$ \mathbb{H}(\pi_t) = - \sum_{\theta \in \Theta} \pi_t(\theta) \log \pi_t(\theta) $$
对候选问题 $(q,u)$,系统计算其带来的预期信息增益:
$$ I_t(\theta;Y\mid \mathcal{H}_t;q,u)=\mathbb{H}(\pi_t)-\mathbb{H}(\theta\mid Y,\mathcal{H}_t;q,u) $$
真正高明的点在于:用户回答不是结构化 label,而是自由文本,因此作者用 LLM 做 soft semantic alignment,把回答映射成 answer-option distribution,再进行 soft Bayesian update。这样既保留了数学上的 belief update,又适配真实对话形态。
实验设置与结论分析
在医疗诊断任务 iCraft-MD 上,BALAR 和 Oracle 之间的差距已经被大幅压缩,说明高质量澄清问题本身几乎等价于“补采关键观察”。更重要的是,移除 EXPAND 后性能明显下降,表明固定 slot/schema 的 dialog state tracking 对复杂开放问题确实不够。
关键技术亮点分析
- 这是非常典型的 neuro-symbolic agent 设计:LLM 负责语言理解与候选生成,Bayesian controller 负责决策。
- 它把“active reasoning”从 prompt engineering 拉回到了信息论与统计推断的框架里。
- 对资深从业者最有启发的一点是:很多 agent 失败不是不会推理,而是不会决定“下一步该问什么”。
PRISM: Perception Reasoning Interleaved for Sequential Decision Making
中文标题:PRISM:面向序贯决策的交错式感知-推理框架
作者:Mohamed Salim Aissi, Clemence Grislain, Clement Romac, Laure Soulier, Mohamed Chetouani, Olivier Sigaud, Nicolas Thome
机构:Sorbonne Université / CNRS / Inria / Hugging Face 等
📄 查看 ArXiv 原文
研究背景与痛点
Embodied agent 里一个老问题是:VLM 看到了图像,但没抓住任务真正相关的信息;LLM 擅长规划,但拿到的是一段目标无关、噪声很大的视觉描述。于是系统出现 perception-reasoning-decision gap:不是 planner 不会想,而是 perception 根本没把该看的地方讲清楚。
直接把 goal 塞给 VLM 虽然能让它“更聚焦”,但又容易 hallucinate 出任务想要的对象。PRISM 的出发点非常对:不要让 VLM 一次性给完答案,而是让 LLM 先读初始描述,再反过来追问 VLM 缺失的视觉细节。
核心贡献
- 提出 Dynamic Question-Answering (DQA) 闭环:LLM 质询 VLM,而不是被动接收描述。
- 把多模态感知转写成更干净的文本状态 $d_f^t$,再交给 RL-trained decision LLM。
- 支持 BC + PPO 两阶段训练,并避免直接对大型多模态模型做高风险 RL。
- 在 ALFWorld 与 R2R 上显著优于现有 image-based baselines。
具体案例剖析
输入案例:任务是“把 CD 放到餐桌上”。VLM 初始描述只会说“桌子上有杯子、电脑,背景有墙”,完全没有告诉 agent 当前视野有没有 CD、有没有 dining table、路径是否可达。
PRISM 中,LLM 会立刻追问:附近是否能看到 CD?能否看到通往餐桌的路径?VLM 分别回答后,LLM 再 synthesize 出一个更适合决策的 compact description。这样 agent 不会在错误的 table 上瞎操作,而是知道必须先探索环境。
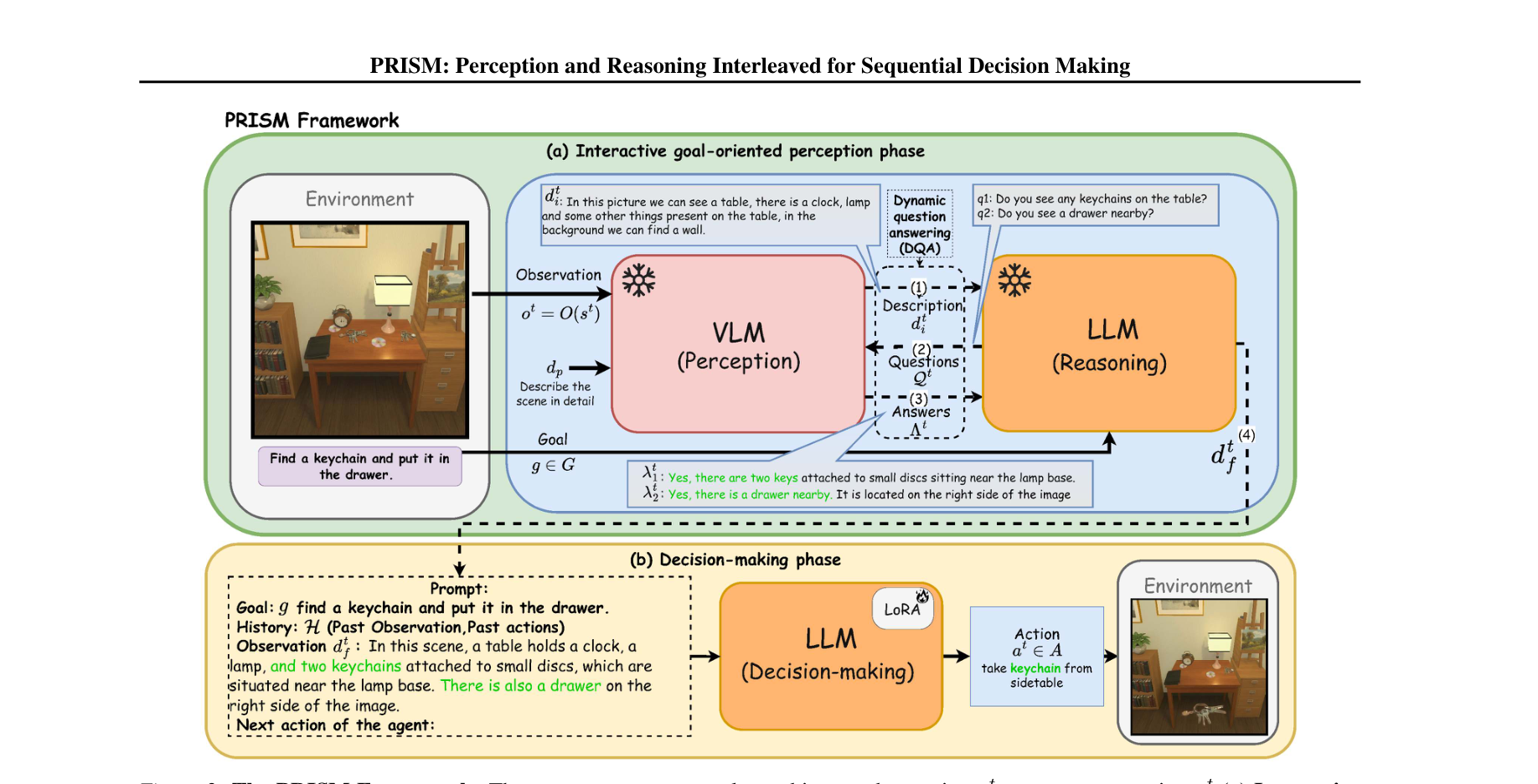 图注:PRISM 先让 VLM 生成初始描述,再由 LLM 提问、VLM 回答,最后把问答结果压缩成任务相关状态,送入决策策略网络。
图注:PRISM 先让 VLM 生成初始描述,再由 LLM 提问、VLM 回答,最后把问答结果压缩成任务相关状态,送入决策策略网络。
方法论与技术实现
给定观测 $o^t$,VLM 先生成初始描述 $d_i^t$,LLM 基于目标 $g$ 产生问题集 $Q^t$,VLM 对每个问题回答 $\lambda_j^t$,然后 LLM 生成最终状态描述 $d_f^t$:
$$ d_i^t = \mathcal{V}_p(d_p, o^t), \quad Q^t = \mathcal{R}(d_i^t, g), \quad d_f^t = \mathcal{R}(d_i^t, Q^t, \Lambda^t) $$
之后策略网络按自回归方式预测动作:
$$ \pi_\theta(a_i \mid g,\mathcal{H},d_f^t)=\prod_{j=0}^{|a_i|} P_{LLM}(w_j \mid g,\mathcal{H},d_f^t,w_{
从工程角度看,作者最聪明的设计不是更大的模型,而是让 perception output 变成可以被 RL 稳定优化的 textual state representation。
实验设置与结论分析
在 ALFWorld 上,PRISM 相比单体 VLM 或简单拼接 QA 的方案有非常明显的提升;在 R2R 上也优于固定问题模板方法。这说明“动态生成问题 + 语义融合”比把多轮 QA 原样塞回 prompt 更有效。
关键技术亮点分析
- 这是 embodied agent 里非常值得推广的 top-down active perception 方案。
- 它证明了 perception 不是一次性模块,而可以被 planner 反向驱动。
- 对从业者最实用的启发是:别盲目拼接多模态中间结果,先做一个 synthesis node 再决策,效果通常更稳。
Agentic Retrieval-Augmented Generation for Financial Document Question Answering
中文标题:面向金融文档问答的 Agentic RAG 框架
作者:Yang Shu, Yingmin Liu, Zequn Xie
机构:Zhejiang University
📄 查看 ArXiv 原文
研究背景与痛点
金融文档 QA 难点不只是 retrieval,而是 multi-step numerical reasoning + heterogeneous evidence alignment。企业年报里同一个问题往往横跨表格、正文、脚注和不同 fiscal year;普通 RAG 的一次检索根本不够,而且 LLM 的心算对财务问题尤其不靠谱。
所以本文不是简单做“更强检索器”,而是完整设计了一个 financial agent loop:复杂问题要拆解、要重写 query、要执行代码、要做 cross-evidence verification,还要控制 token 成本。
核心贡献
- 训练对比式金融检索器,专门区分时间、指标、粒度、实体上的 hard negatives。
- 用 Program-of-Thought 生成并执行 Python,规避 LLM 数学错误。
- 引入 Adaptive Strategy Router,简单问题直走 cheap path,复杂问题才进入 agentic loop。
- 在 FinQA、ConvFinQA、TAT-QA 上取得稳定领先,并兼顾工业可落地性。
具体案例剖析
案例 1:问 2018 到 2019 所得税 provision 的百分比变化。第一轮检索拿对了 2019 数字,却拿错了 2018 的来源口径。Self-verifier 发现一个数来自主表、另一个来自附注,触发 query refinement,再次检索后得到正确配对证据。
案例 2:问 operating expenses 的 CAGR。普通 CoT 容易把 CAGR 当平均增长率乱算;PoT 则生成 Python:
cagr = (v_end / v_begin) ** (1/n) - 1
让计算回到确定性执行环境,这是金融场景里非常必要的 architectural choice。
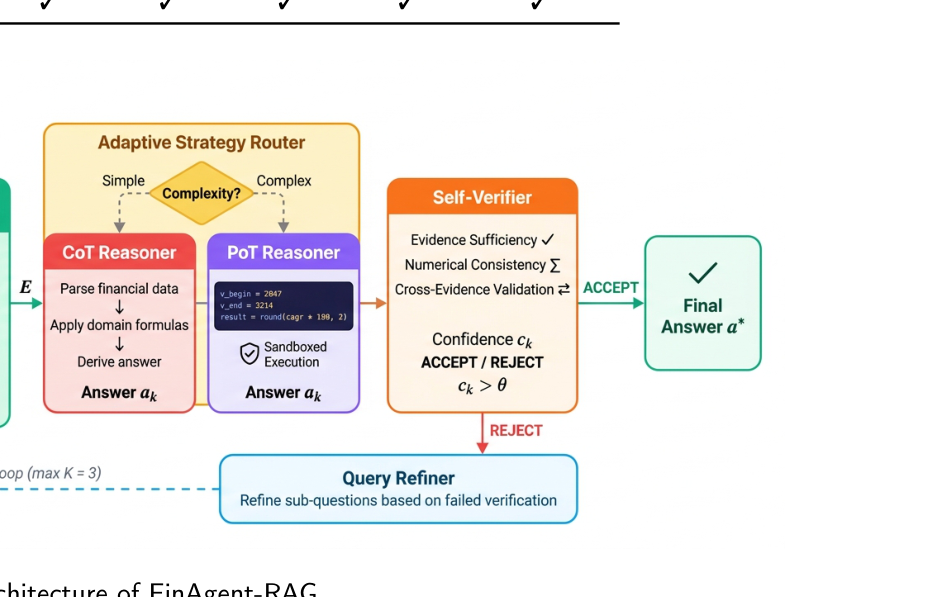 图注:FinAgent-RAG 由路由器、金融检索器、代码推理模块和自验证器组成,形成面向复杂金融问答的闭环推理流程。
图注:FinAgent-RAG 由路由器、金融检索器、代码推理模块和自验证器组成,形成面向复杂金融问答的闭环推理流程。
方法论与技术实现
检索器采用对比学习损失:
$$ \mathcal{L}_{\text{contrast}} = -\log \frac{e^{\mathrm{sim}(e_q,e_{d^+})/\tau}}{e^{\mathrm{sim}(e_q,e_{d^+})/\tau} + \sum_i e^{\mathrm{sim}(e_q,e^-_i)/\tau}} $$
最终答案接受条件由 verifier 决定:
$$ v_k = \begin{cases}\text{ACCEPT}, & v_{\text{suff}} \land v_{\text{num}} \land v_{\text{cross}} \\ \text{REJECT}, & \text{otherwise} \end{cases} $$
其中 $v_{\text{suff}}$ 表示证据充分,$v_{\text{num}}$ 表示数值过程可追溯,$v_{\text{cross}}$ 表示跨数据源口径一致。这个设计比很多只会“再搜一次”的 agent 方案成熟得多。
实验设置与结论分析
在三大金融 QA benchmark 上,FinAgent-RAG 都明显优于对照组。更重要的是,自适应路由在只带来轻微精度损失的情况下大幅降低 token 成本,这一点对真实生产系统比 leaderboard 分数还重要。
关键技术亮点分析
- 它抓住了行业问题本质:金融 QA 首先是 evidence governance 问题,其次才是生成问题。
- “代码执行替代语言心算”在高精度场景里几乎应当视为默认范式。
- 对企业落地最有价值的是 tiered architecture:不要让每个 query 都进入昂贵的 full agent loop。
From History to State: Constant-Context Skill Learning for LLM Agents
中文标题:从历史到状态:面向 LLM Agent 的固定上下文技能学习
作者:Haoyang Xie, Xinyuan Wang, Yancheng Wang, Puda Zhao, Feng Ju
机构:Arizona State University
📄 查看 ArXiv 原文
研究背景与痛点
LLM agent 的一个根本性工程瓶颈,是每走一步都在把历史轨迹、技能说明、工具上下文不断塞回 prompt,导致 token 成本暴涨,而且越长越不稳。对 personal agent 尤其糟糕:长历史既贵,又可能把隐私材料持续送去云端。
这篇论文的核心观点很强:对于重复型 workflow,真正应该保留在上下文里的不是越来越长的 history,而是一个小而稳定的 task state;至于程序性技能知识,应该迁移进权重而不是留在 prompt 里。
核心贡献
- 提出 context-to-weights 范式:把 procedure knowledge 学进 LoRA skill module。
- 用 deterministic tracker 把执行历史压缩成固定大小 state block。
- 训练时结合 SFT + RL,并利用子目标状态提供奖励而不依赖昂贵的 LLM judge。
- 在 ALFWorld、WebShop、SciWorld 上同时获得较强性能与巨大的 token 节省。
具体案例剖析
以 WebShop 为例,传统 ReAct 到第 5 步时 prompt 里通常已经堆满了搜索词、翻页历史、看过的商品与冗长说明;而本文方法只保留三类输入:任务目标、当前观测、以及 tracker 渲染出的 state block,例如:
Current phase: browse_results
Queries tried: none
Items inspected: none
这种状态表示使模型无需回读全历史,就能判断下一个动作是继续搜索、点击商品还是切换筛选器。
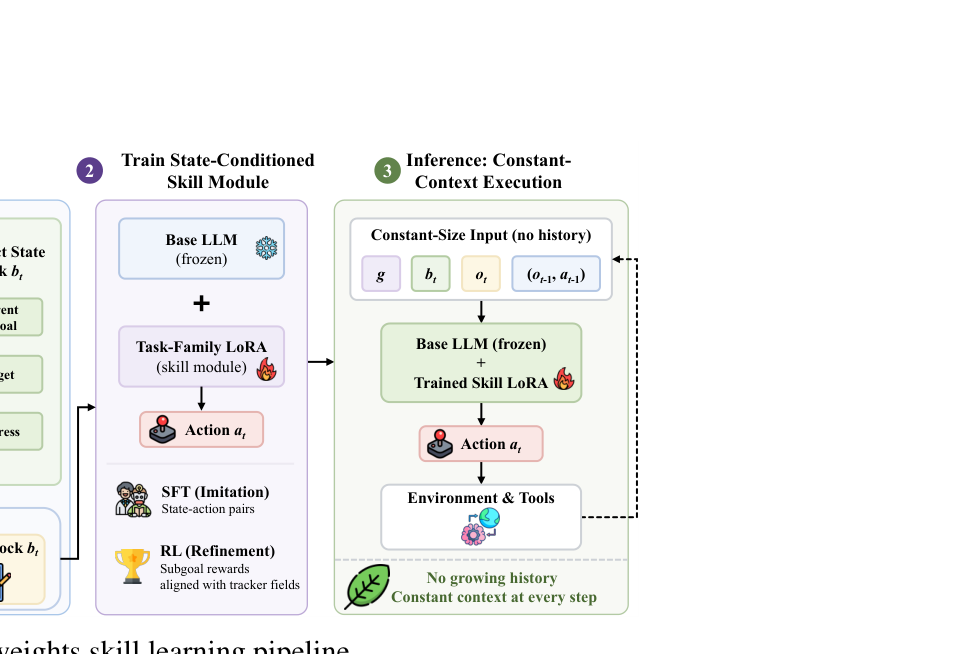 图注:论文把 agent workflow 分成“状态追踪”和“技能权重学习”两层:状态进 prompt,程序性技能进 LoRA 权重,从而实现 constant-context inference。
图注:论文把 agent workflow 分成“状态追踪”和“技能权重学习”两层:状态进 prompt,程序性技能进 LoRA 权重,从而实现 constant-context inference。
方法论与技术实现
tracker 递推更新内部状态:
$$ m_t = \mathrm{Update}_k(m_{t-1}, a_{t-1}, o_t), \quad b_t = \mathrm{Render}_k(m_t) $$
模型每步输入写成:
$$ x_t = \mathrm{Format}(g, o_t, q_t, b_t), \quad |x_t| \le B_k $$
SFT 阶段优化下一动作预测:
$$ \mathcal{L}_{SFT}^{(k)} = -\sum_{(x_t,a_t^*)\in\mathcal{D}_k} \log p_{\theta_0,\phi_k}(a_t^*\mid x_t) $$
强化学习阶段则用环境奖励与子目标进度奖励联合驱动,这种“deterministic tracker as reward scaffold”的设计非常适合真实 agent 系统。
实验设置与结论分析
论文展示了非常夸张的 token 节省:相对标准 ReAct,每步 prompt token 可下降 2–7 倍,整条 episode 甚至能省到 10–14 倍。同时性能并没有因此牺牲,反而在多个环境上达到或超过强基线。
关键技术亮点分析
- 这是 agent 领域少见真正抓住“成本结构”的工作,不只是在 benchmark 上做小修小补。
- 它为 personal agent / on-device agent 给出了一条很现实的路线:少用历史,多用状态;少堆 prompt,多学 skill。
- 对长期看,constant-context 可能会是 agent 训练从 prompt-centric 走向 state-centric 的关键一步。
Authorization Propagation in Multi-Agent AI Systems: Identity Governance as Infrastructure
中文标题:多智能体 AI 系统中的授权传播:身份治理即基础设施
作者:Krti Tallam
机构:Kamiwaza AI
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文不是典型的算法 paper,而是一篇很有分量的 system/security position paper。作者指出,业界把 agent 安全问题过度收缩成 prompt injection,是一个危险的误判。即便 prompt injection 被完美解决,多 agent 系统仍然存在一个更底层的问题:authorization propagation。
当多个非人类主体跨工具、跨数据边界协作时,权限不是静态附着在某个 API 上,而是在整个 workflow DAG 中流动、衰减、聚合和过期。传统 RBAC/ABAC/ReBAC 在这里都不够。
核心贡献
- 把 agent 安全区分为 attack vectors 与 architectural problems 两个层面。
- 形式化提出 authorization propagation 的三个核心子问题:transitive delegation、aggregation inference、temporal validity。
- 给出多智能体身份治理架构的七项结构性要求 R1–R7。
- 提出“identity governance as infrastructure”的主张:鉴权必须成为系统基础设施,而不是入口处的一次性检查。
具体案例剖析
论文用 due-diligence workflow 举例非常到位:分析师请求总结影响公司估值的责任风险,orchestrator 调 retrieval agent 抓取财务室文档与限制级备忘录,再交 synthesis agent 汇总。问题在于,agent 也许分别有权读取这些源,但未必有权把它们合成成一个跨边界输出,更未必有权向最终用户暴露“哪些敏感信息被排除了”。
作者还列举了生产环境中的非对抗性故障:session 绑定失败后悄悄回退到更宽权限、delegation 绑定名义成功但实则丢失作用域、基础设施层无法证明容器身份等。这些都不是 prompt injection,却足以导致严重越权。
方法论与技术实现
论文将系统抽象为主体、资源与工作流图,并强调聚合结果本身也可能构成新的授权对象。给定资源 $d_1,\dots,d_j$ 与合成函数 $f$:
$$ f(d_1, d_2, \dots, d_j) \to r $$
即便每个输入单独可访问,也不代表输出 $r$ 自动可访问;这正是 aggregation inference 的本质。另一方面,temporal validity 指出权限检查不能只发生在 initiation time,而必须覆盖 access-time / completion-time,甚至支持更细粒度的 revocation 机制。
实验设置与结论分析
这篇文章没有传统 benchmark,而是整合近期企业安全报告和新系统论文。价值不在于打榜,而在于给出了一个很清晰的系统设计 checklist:如果你的 multi-agent platform 还在依赖 ambient credentials、静态 service account、入口处一次性鉴权,那基本已经落后于问题本身。
关键技术亮点分析
- 它把行业注意力从“怎么防 prompt injection”拉回到“怎么设计正确的授权基础设施”。
- 对企业 agent platform 架构师来说,这篇文章的启发很强:权限应当是 workflow property,而不是 API property。
- 如果说很多 agent 论文在教系统“如何做事”,这篇是在提醒大家“谁有权做这件事、做到什么程度”。