结合LLM引导的动态动作空间与强化学习进行可合成先导化合物优化
原名: Reinforcement Learning with LLM-Guided Action Spaces for Synthesizable Lead Optimization
作者: Tao Li, Kaiyuan Hou, Tuan Vinh, Monika Raj, Zhichun Guo, Carl Yang
机构: Emory University, University of Oxford
📄 查看 ArXiv 原文
🔬 研究背景与痛点 (Background & Pain Points)
在AI驱动的药物发现(AI4Science/Drug Discovery)领域,先导化合物优化(Lead Optimization)处于极度核心的环节。在现实的药物化学流程中,专家们需要在初始“Hit”分子上进行局部结构调整(如修改官能团),以提高其药效、选择性和安全性。对于计算方法而言,这项任务面临着一对天然的矛盾:
合成可行性(Synthesizability)的困境: 强化学习(RL)、遗传算法(GA)和扩散模型往往为了刷高目标属性(Oracle scores),生成的分子在理论上得分极高,但在湿实验室(Wet-lab)中根本无法合成,缺乏可行的化学反应路径,沦为“纸上谈兵”。传统约束方案的低效性: 为了保证可合成性,现有方法(如MCTS、GFlowNets等)通常在庞大的预定义构建块(Building blocks)和反应模板库上进行穷举式图搜索。这种组合爆炸导致严重依赖 Oracle 评估的次数(Sample inefficiency)。LLM 直接生成的“幻觉”: 尽管大型语言模型(LLMs)拥有海量化学语料,但直接让 LLM 生成 SMILES 经常破坏化学物理规则(如多配位碳原子等)。即使用 Tool-Augmented 的方式给 LLM 挂载工具,LLM 也通常只擅长处理单步逆合成,而在多步优化(Multi-step optimization)的长线序列决策中表现挣扎。
因此,如何既发挥 LLM 的化学直觉压缩搜索空间,又利用 RL 强大的长期信用分配(Credit Assignment)能力,成为当前 AI 辅助制药亟待解决的挑战。
💡 核心贡献 (Core Contributions)
本文提出了一种全新的双轨制框架 MolReAct 。其核心思路是:剥离“化学合法性检验”与“长期策略规划”的职责。用一个挂载工具的重型 LLM 作为“动态环境生成器”,为轻量级的 RL 策略模型提供高度浓缩、绝对合法的动态候选动作空间(Action Space)。
构建基于 LLM 的动态反应环境(Dynamic Reaction Environment): 使用 Llama-3.3-70B 结合 ReAct 范式,在每一步通过调用专业的化学信息学工具(如官能团识别、活性位点分析),筛选匹配的反应模板,动态为当前分子提出至多10个紧凑且符合化学常理的候选反应。引入 GRPO 进行多步轨迹优化: 不再用 LLM 自身做长程决策,而是将轻量级的 Qwen-3-4B 作为 Policy Model,在 LLM 给出的合法动作空间上使用 Group Relative Policy Optimization (GRPO) 算法进行多步强化学习训练,极大提高了样本效率和长期奖励。SMILES-based 环境缓存机制: 鉴于 LLM 环境调用的高昂推理成本,文章引入了基于 SMILES 的精准缓存机制。这一创新在 GRPO 多轨探索时,大量复用已评估的中间状态,将端到端训练的推理时间削减了约 43%。SOTA 级的双重保障: 在 14 个基准任务上(包括多参数优化、重发现、蛋白质靶点结合亲和力),MolReAct 取得了最高平均 Top-10 分数。其不仅属性得分高,而且每一条优化轨迹都是由具体化学反应模板和商用积木串联而成的实际合成路径 。
🔍 具体案例剖析 (Case Study / Examples)
论文对基于特定靶点(如 DRD2、sEH、GSK3$\beta$ 和 JNK3)的优化轨迹进行了可视化,清晰地展示了框架如何精准“打补丁”:
案例 1: 靶向可溶性环氧化物水解酶 (sEH) 的优化
输入分子(Candidate): 包含基础的核心骨架结构,Oracle 得分极低(0.003),AutoDock Vina 对接亲和力为 -7.257 kcal/mol。决策反应(Action): 模型选择了一次基于 C-N 偶联(C-N coupling)反应的动作,从候选池中调用了一种特定的氨基构建块(building block)。输出分子(Optimized): 成功在边缘引入了一个芳香胺基团。这一改进巧妙地将分子延展到了靶向蛋白更深的子口袋中,使得最终 Oracle 评分飙升至 0.582,并且物理对接得分(Vina score)大幅改善至 -9.322 kcal/mol。
案例 2: JNK3 激酶的抑制剂改造
改造过程: 模型精准识别到原分子的“腈(nitrile)”基团,选择了腈向四唑转化(nitrile-to-tetrazole conversion) 的经典反应模板。化学意义: 用一个体积更大、具有更强氢键能力的杂环系统替换了紧凑的腈基。这一局部微调使得 Vina 评分从 -6.043 提升到 -6.865 kcal/mol,证明了 MolReAct 确实掌握了构效关系(SAR)直觉。
通过商用库(Enamine)对比,LLM 生成的反应构建块中有 66.1%~76.2% 是可以直接网购得到的,证明了生成路线的极高现实可行性。
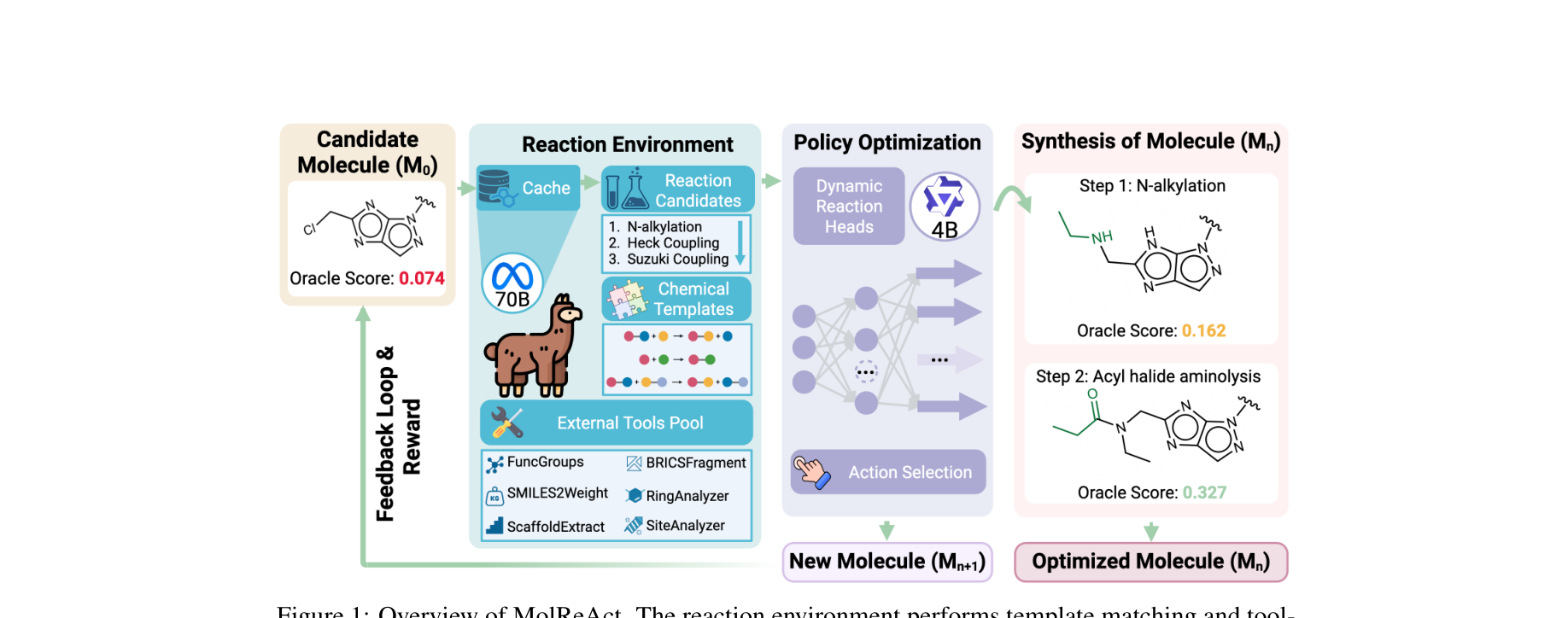
图注:MolReAct 框架全景图。左侧为动态反应环境(由缓存、大模型 Agent 和外接 RDKit 分析工具组成),负责在匹配的化学反应模板下生成至多10个合法候选产物;右侧为策略优化模块(由 Qwen 驱动的多动作头网络),在候选动作和中止动作中做 RL 序列决策。 ⚙️ 方法论与技术实现 (Methodology)
MolReAct 将先导化合物优化建模为具有可变动作空间的马尔可夫决策过程(MDP): $\mathcal{M} = (\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R})$。核心实现分为三大模块:
1. 动态的、基于工具增强 LLM 的环境构建
由于可合成空间的巨大组合性质,论文不使用传统 RL 固定长度的动作字典,而是为每个状态 $s_t$ 动态生成动作空间 $\mathcal{A}(s_t)$:
模板匹配 (Template Matching): 使用预定义的 115 种经验证的化学反应模板。通过 RDKit 对当前分子进行 SMARTS 子结构匹配,只保留匹配成功的可用模板。工具增强实例化 (Tool-Augmented LLM): 基于 ReAct 框架,给 Llama-3.3-70B 挂载 6 种化学分析工具(包括分子量计算、官能团检测 FuncGroups、支架提取 ScaffoldExtract、反应位点识别 SiteAnalyzer 等)。LLM 分析这些结构特征后,填入缺失的反应物(building blocks),生成具体的候选反应产物:
2. 基于 GRPO 的多步轨迹优化
轻量级策略模型 $\pi_\theta(a_t \mid s_t)$ 采用 Qwen-3-4B-Instruct,附加一个线性动作头。由于每个分子的候选反应在插槽中的语义不同,模型被强制要求基于输入的 Structured Prompt(含反应模板名、构建块 SMILES 等)来打分。那些无用的 action 槽位将被掩码(Logits 设为 $-\infty$)。
使用 DeepSeek-R1 同款的 GRPO 算法进行优化。对于每个初始分子,采样一组 $G$ 条轨迹,并在轨迹终端通过 Oracle 获得最终奖励 $r_T$。通过组内中心化标准化(减均值除标准差)得到优势函数 $A$。GRPO 损失函数不仅通过重要性采样比例截断防止策略更新幅度过大,还引入了与旧策略(Reference Policy)的 KL 散度约束,确保模型不崩溃:
$$ \mathcal{L}_{GRPO}(\theta) = \mathbb{E} \left[ \min(\rho_t(\theta) A, \text{clip}(\rho_t(\theta), 1-\epsilon, 1+\epsilon) A) \right] - \beta \mathbb{D}_{KL}\big(\pi_\theta(\cdot \mid s_t) \parallel \pi_{ref}(\cdot \mid s_t)\big) $$
3. SMILES 驱动的缓存机制 (Reaction Caching)
在 RL 强化阶段(尤其是 GRPO 需要大量 Rollout 的机制下),状态经常出现交叉重叠。系统使用分子的 Canonical SMILES 为键,缓存 LLM 推理生成的 action space 和状态转移结果。后续相同分子遇到状态请求时,直接触发 Cache hit 进行瞬间 O(1) 查找,彻底绕过庞大 Llama-70B 的推理。这保证了在 10000 次 Oracle 预算下训练能在 40 小时单卡上完成。
📊 实验设置与结论分析 (Experiments & Results)
实验设置: 基于从 ZINC-250K 筛选出的分子。在 Therapeutics Data Commons (TDC) 平台选取 14 个评测基准任务(包括多参数 MPO、目标分子重发现、中值优化、激酶和 GPCR 的结合活性预测以及一个基于 AutoDock Vina 物理模型的代理优化任务)。Oracle 调用上限严格限制为 10,000 次。
对比基线: 基于图/遗传算法的 GraphGA;基于反应规则和投影的 ReaSyn, SynFormer;基于 LLM 指令直接生成的 DrugAssist, LDMOL, mCLM。
核心结果:
优化天花板拔高(Top-10 Score): MolReAct 平均得分达 0.571,在 14 个任务中有 6 个第一,7 个第二,全面领先于目前所有保障可合成性的模型(最强基线 SynFormer 仅为 0.555)。在特定靶点活性(如 GSK3$\beta$ 和 JNK3)上展现了断崖式的优势。极高样本效率(Sample Efficiency / AUC10): 利用强大的策略网络引导,MolReAct 在 14 个任务中赢下 9 个的 AUC10(累积呼叫曲线面积)。这表明,有策略的 LLM 引导搜索,远快于基于 MCTS 和 GA 的随机突变探索。消融实验确认贡献: 作者分离了“单步 LLM Tool 引导效果”和“多步 GRPO 策略效果”。发现:挂载 Tool 之后的 LLM 选出的单步分子显著优于 Vanilla LLM(0.776 vs 0.574 @ DRD2);而套用 GRPO 多步决策更是比简单的贪心算法(Greedy Search)有全面碾压级的提升(0.981 vs 0.826 @ DRD2),证明了多步前瞻对于跳出局部最优至关重要。多样性未崩溃(Diversity): 传统的 GraphGA 在高分段往往发生结构坍塌(都长得一样),其内部多样性(IntDiv)在 JNK3 任务上低至 0.136。而 MolReAct 保持了极高的结构多样性(平均 0.841),与无约束的大语言模型生成多样性相当。
⭐ 关键技术亮点分析 (Takeaways for LLM Practitioners)
作为资深 LLM / RL 从业者,这篇论文在架构设计层面上为我们提供了极具价值的启示:
环境(Environment)与策略(Policy)的巧妙分离: 将大模型(70B)用作 MDP 的状态转移引擎和动作空间界定者(生成紧凑的 Legal Actions),而将小模型(4B)用作 RL 的决策代理(Actor)。这种 Heavy Environment + Light Policy 的范式,非常巧妙地解决了大模型做 RL 调参慢、难收敛的痛点,同时利用上了大模型的先验知识做剪枝。在推荐系统、工业排程等动作空间极大的场景中,这种动态 action filtering 的思路极具复用价值。GRPO 突破数学/代码象限: 以往 DeepSeek 爆火的 GRPO 主要用于具有天然绝对对错反馈的代码和数学推理(Reasoning)。本文成功将其应用于离散图构建、分子生成这种具有连续黑盒奖励信号(Oracle Property Score)的科学计算领域,证明了群体相对策略优化在平滑 Reward Landscape 时的鲁棒性。Tools 作为提示词压缩手段: 并没有让大模型生成长篇大论的 CoT,而是强行调用确定的化学工具提取属性(RingAnalyzer, BRICSFragment 等),将高维分子图结构抽象并压缩成了极简的 Structured Scratchpad。在幻觉严重的垂类任务中,通过引入精确物理/规则引擎进行 Grounding 仍是当下的最佳实践。缓存机制极大释放瓶颈: 在带有 LLM Env 的 RL 系统中,交互延迟是最大瓶颈。作者观察到马尔可夫决策中的“中间态重叠”极高(Cache hit rate达 56.4%),通过将 MDP 节点确定性哈希,直接将计算量砍半。这种系统工程上的巧思是在真实工程落地中不可或缺的。
DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL
DeepDive:通过知识图谱与多轮强化学习推进深度搜索智能体
作者: Rui Lu, Zhenyu Hou, Zihan Wang, Hanchen Zhang, Xiao Liu, Yujiang Li, Shi Feng, Jie Tang, Yuxiao Dong
机构: 清华大学,Z.AI,东北大学
📄 查看 ArXiv 原文
背景与痛点 (Background & Challenges)
随着大语言模型(LLMs)在复杂推理任务中的表现日益提升,将它们与外部浏览工具结合以解决现实世界复杂问题的 Deep Search Agents(深度搜索智能体) 成为前沿探索的热点。这类任务通常要求智能体在数以百计的在线网页中进行深度的、多跳的搜索与信息聚合(例如应对 BrowseComp 等高难度基准测试)。
然而,现有的开源模型在复杂 Deep Search 任务上远远落后于闭源系统(如 OpenAI DeepResearch),主要面临两大核心痛点:
数据维度 (Data-wise): 传统的 QA 数据集(如 HotpotQA)过于简单,目标实体往往极其清晰,难以反映真实世界中“难以寻找(hard-to-find)”和碎片化信息的检索挑战。而针对深度长视距搜索构建的人工标注成本极高,极难规模化。训练维度 (Training-wise): 即便是具备强大推理能力的模型(如 DeepSeek-R1),若缺乏针对性的训练,在调用浏览器工具时往往只会进行非常浅层的查询,无法有效地将长视距推理(Long-horizon reasoning)与深度搜索工具融合,并极易在中间步骤产生幻觉。
核心贡献 (Core Contributions)
全自动的深搜QA数据合成机制: 创新性地利用开放知识图谱(KGs),通过控制图游走与 LLM 的属性混淆(obfuscation),自动化且可控地生成大量复杂、需要长链推理与搜索的高难度 QA 对。具备冗余惩罚的多轮强化学习框架 (DeepDive): 提出了一个端到端的多轮强化学习(Multi-Turn RL)算法,设计了独特的“冗余惩罚(Redundancy Penalty)”,以抑制模型陷入无意义的重复检索,激励其采用多样化且高效的搜索策略。树立开源深搜 Agent 新标杆: 基于该方法训练的 DeepDive-32B 在 BrowseComp 数据集上取得了 15.3% 的优异表现,超越了 WebSailor、DeepSeek-R1-Browse 和 Search-o1 等诸多开源基线。同时深入验证了随着 Inference 阶段工具调用次数放宽与并行采样的增加,Agent 能力可实现明显的 Test-time Scaling。
具体案例剖析 (Case Study)
为了直观说明传统多跳 QA 和真正的 Deep Search QA 的难度差异,论文对比了 HotpotQA 与 BrowseComp 的经典场景:
[浅层多跳] HotpotQA 示例: Input: "How high is the mountain that is located east of the WorldFellowship Center?"分析: 题目中包含了绝对明确的实体("WorldFellowship Center"),模型只需直接通过搜索引擎即可快速顺藤摸瓜,检索难度极低(Definite Entity)。
[深度搜索] BrowseComp 示例 (DeepDive 应对的靶向难题): Input: "Please identify the fictional character who occasionally breaks the fourth wall with the audience, has a backstory involving help from selfless ascetics, is known for his humor, and had a TV show that aired between the 1960s and 1980s with fewer than 50 episodes."分析: 这是一个典型的“模糊实体(Blurry Entity)”查询。输入条件极度碎片化(经常打破第四面墙、背景与无私的苦行僧有关、幽默、60-80年代的电视节目且少于50集)。模型不可能一次 Query 得到答案,必须设计多轮子查询,分别验证各个条件,并在巨量网页中进行信息排除与交叉比对(Reasoning & Browse 的深度耦合)。
方法论与技术实现 (Methodology)
1. 基于知识图谱的自动化数据合成 (Automated Data Synthesis from KGs)
为了批量制造前文所述的“模糊实体”问题,作者利用了知识图谱(KGs)的客观可验证性(verifiability)和多跳结构。合成过程如下:
Random Walk 生成推理链: 从图中任选起始节点 $v_0$ 游走 $k$ 步,形成路径 $P = [v_0, v_1, \dots, v_k]$。利用 LLM 辅助决策下一步并控制节点的出度分布,保证路径既复杂又具备逻辑自洽性。引入属性混淆 (Obfuscation): 仅仅凭借节点序列仍然容易被直接搜出。作者将每个节点及其伴随属性(如日期、地点)结合,形成“富属性路径” $P_A$:提取终点的一个属性作为 Answer,使用 Frontier LLM (如 Gemini-Pro) 把 $P_A$ 中的绝对信息“模糊化”(例如将确切年份改写为年代范围),生成高度混淆的 (q, a) 对。最后,只有连当前顶尖搜索模型都无法在4次内直接搜出的 QA 才会被留作训练集。
2. 端到端多轮强化学习 (End-to-End Multi-Turn RL)
在获得了难例数据集后,DeepDive 采用基于 GRPO 算法的多轮 RL 让模型掌握边推理边搜索(Reason-and-Search)的节奏。Agent 输出的轨迹 $\mathcal{T} = [q, (c_1, a_1, o_1), \dots, a_{eos}]$ 包含了一系列思维链、操作和观察。
核心亮点:带冗余惩罚的 Reward 塑形 (Redundant Penalty)
实验设置与结论分析 (Experiments & Results)
基准评测: 在 BrowseComp、BrowseComp-ZH、XBench-DeepSearch 和 SEAL-0 上进行测试。DeepDive-32B(基于 QwQ-32B 训练)在 BrowseComp 上实现了 15.3% 的绝对优势,远超同参数级别模型及多个专门针对搜索优化的 Agent(如 Search-o1 的 2.8%,WebSailor-32B 的 10.5%)。RL 驱动深层探索: 训练过程中,模型的 Tool call 频率与任务准确率同步攀升,证明 RL 成功内化了由数据驱动的深度搜索直觉,而非生搬硬套短视策略。Ablation 实验也证明,去掉 Redundancy Penalty 会导致模型无效的 Tool Call 增加近 14%。Test-Time Scaling 现象:
Tool Call Budget 提升: 在 Inference 阶段,将模型允许的最大工具调用次数从 8 增加到 128 时,表现稳健上升。Parallel Sampling 策略创新: 在多路并行采样时,传统的多数投票(Majority Voting)常常因模型在错误路径上过早终止而得到假性共识。DeepDive 提出 “选择使用最少工具调用的答案 (Fewest Tool Calls)” ,这一策略将并行通过率从 12.0% 暴涨至 24.8%(逼近 37.6% 的理论上限),因为早期停止的答案通常代表模型具有极高的确信度。
关键技术亮点分析 (Technical Highlights)
作为 LLM 领域推进 Agent 化落地的突破性研究,DeepDive 在思路上有几个极其出彩的借鉴点:
用“图”破“冰”,解决复杂推理数据获取的困局: 长视距搜索极度缺乏训练语料。作者回归经典 Knowledge Graph,并非用作 RAG 的外挂库,而是将其视为天然的多跳推理拓扑图。通过强制混淆节点的实体与属性,完美模拟了真实人类搜索时那种“只记得某些侧面特征却叫不上具体名字”的“模糊实体”检索困境。这种合成数据直接打通了向 RL 提供极高难度正负样本的通道。为 RL 搜索注入“反直觉”的 Jaccard 惩罚项: 在 LLM 工具调用中,“重复调用同样的词去搜无效信息”是长期存在的顽疾。Jaccard 惩罚机制巧妙且轻量,逼迫模型在 RL 探索空间中放弃简单的文字复用,转而去挖掘潜在的新维度线索。实验发现,模型在训练后期自发学会了更高级的搜索引擎高级语法(如 Minus 排除法和 OR 操作符),正是这一惩罚项带来的良性突变。洞察 Test-Time 机制的偏见: 针对长链路任务,传统的 Majority Voting 往往失效,因为系统可能会在某些短视但错误的路径上大量撞车。作者洞悉到的“使用 Tool calls 最少的答案反而最准”为大规模搜索 Agent 的评估过滤与 Test-time Compute 的分配提供了一个非常有启发的后处理 heuristics。
基于信息增益的策略优化:一种简单有效的多轮搜索Agent训练方法
INFORMATION GAIN-BASED POLICY OPTIMIZATION: A SIMPLE AND EFFECTIVE APPROACH FOR MULTI-TURN SEARCH AGENTS
作者: Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, Zhenzhe Ying
机构: 蚂蚁集团 (Ant Group), 中国人民大学
📄 查看 ArXiv 原文
🔍 研究背景与痛点
近年来,通过强化学习(RL)来提升大语言模型(LLM)的智能体能力(Agentic Capabilities)成为了通向通用人工智能的必经之路,尤其是在依赖外部工具(如搜索引擎)进行长程多轮交互的场景(Agentic Search)中。当前主流的对齐范式(如 GRPO)在单轮任务上表现优异,但面对长轨迹、多轮次 的任务时,主要依赖Outcome-based Rewards(仅根据最终答案的正确性给予奖励) ,这暴露出三大致命缺陷:
优势坍塌 (Advantage Collapse): 在一个组(Group)的多个 Rollout 中,面对复杂 Query 时模型可能全错,面对简单 Query 时可能全对。这种零方差导致 Group-relative advantage 为零,无法产生有效的梯度信号,该现象在小模型(如3B)中尤为严重。缺乏细粒度信用分配 (Lack of Fine-grained Credit Assignment): 多轮场景下步步为营,后期正确的决策可能因为早期的幻觉而白费,或者中途有极高价值的搜索动作却因最终未能输出正确格式而惨遭“一刀切”的惩罚,导致模型无法区分具体哪一步做对了。样本利用率极低 (Poor Sample Efficiency): 整个漫长的长程推理和多轮工具调用轨迹,最终只产出一个标量奖励。中间极其丰富的 Dense semantic information 白白浪费,需要海量样本才能让策略收敛。
尽管业界尝试引入过程奖励(Process Reward),但现有路线要么依赖外部 Reward Model(成本高且存在不可靠性偏见),要么依赖蒙特卡洛树搜索(MCTS)进行步骤价值评估(方差大,推理成本令人望而生畏)。
💡 核心贡献
为打破基于稀疏结果奖励的瓶颈,本文提出了一种内生驱动且极具计算性价比的 RL 框架——基于信息增益的策略优化(Information Gain-Based Policy Optimization, IGPO) 。其核心贡献如下:
全新增量奖励设计: 将 Agent 与环境的多轮交互建模为“逐步获取 Ground Truth 信息”的增量过程。使用当前轮次相比上一轮次在“生成正确答案的概率(对数概率)”上的提升,作为内在的Turn-Level Process Reward 。近乎零开销的向量化实现: 提出了一种巧妙的 Custom Attention Mask 策略,通过将 Ground Truth 拼接在轨迹尾部,只需一次 Forward Pass 即可同时计算出所有轮次的 Information Gain 。相比标准的 GRPO,其训练步骤耗时仅增加了微不足道的 0.02% 。全面压制现有Baseline: 在包含 In-domain 和 OOD 的 7 个 QA Benchmark 上,IGPO 实现了显著优于 DeepResearcher 等基于 Outcome-reward 以及现有 Step-reward 算法的表现,并且在 3B 规模模型上的优势尤为惊人。
🔎 具体案例剖析 (Case Study)
为了直观展示 IGPO 如何实现细粒度的信用分配,论文给出了极其生动的案例(基于真实训练轨迹的复盘):
案例 1(奖励中间的正确行为,即使最终结果错误): 问题: Which film whose director is younger, College Lovers or The Dixie Flyer?模型行为: 第一轮查询了电影发布日期(无效方向,Info Gain = -0.80);第二轮转换思路,成功检索了两位导演的出生日期(正确动作,Info Gain = 0.42 );但第三轮模型在推理出生年份大小时出现逻辑错误,导致最终给出错误答案(Outcome Reward = 0.0)。IGPO的优势: 在传统的 GRPO 中,这条轨迹整段垮掉。但在 IGPO 中,第二轮优秀的检索行为获得了正向奖励,模型学到了“查询导演生辰”这个正确的策略,实现了超高样本利用率。案例 2(惩罚早期的错误方向,奖励后续的纠错): 问题: When is Augusta Marie Of Holstein-Gottorp's mother's birthday?模型行为: 首轮检索由于实体歧义检索了错误的百科页面,获得负向惩罚(Info Gain = -0.39 );模型并未放弃,通过多轮迭代逐渐找到了母亲的准确信息,奖励随之攀升(0.45 ➡️ 0.78),最终得出正确答案(Outcome Reward = 1.0)。IGPO的优势: 不仅引导最终成功,还精准地对早期带偏方向的低质量搜索动作予以惩罚,让策略更迅速地规避无效检索。
⚙️ 方法论与技术实现
IGPO 的设计优雅而严谨,可以无缝嵌入目前大火的 GRPO 框架。其核心推导过程包含三个关键步骤:
1. 基于信息增益的 Turn-Level Reward 构造
设 $a=(a_1, \dots, a_L)$ 为 Ground Truth 答案序列。在第 $i$ 个 Rollout 的第 $t$ 轮,模型生成正确答案的 Log-probability 定义为:
$$ \log \pi_\theta(a \mid q, o_{i, \le t}) = \frac{1}{L} \sum_{j=1}^L \log \pi_\theta(a_j \mid q, o_{i, \le t}, a_{
将当前轮次相对于上一轮次对齐 Ground Truth 的概率增量作为 Immediate Reward(即信息增益):
$$ r_{i,t}^{IG} = \text{IG}(a \mid q, o_{i,t}) = \log \pi_\theta(a \mid q, o_{i, \le t}) - \log \pi_\theta(a \mid q, o_{i, \le t-1}) $$
工程巧思: 直接计算需循环前向传播。IGPO 在 Trajectory 尾端拼接了 $T$ 个 Ground Truth 的拷贝,并设计了专用的 Attention Mask 矩阵:每个拷贝仅能 Attend 到自身对应的 Turn Prefix。只需 $1$ 次 Forward 即可算完所有轮次的 Log-prob,速度提升极其显著 。
2. Turn-Level Discounted Return 的计算
为了抹平内在增益(可能极小)和外在结果奖励(一般为1或0)的尺度差异,IGPO 对这两类 Reward 在组内(Group-wise)分别 进行 z-normalization 得到 $\tilde{r}_{i,t}$,并引入折扣因子 $\gamma$ 进行后向累加,捕捉长期依赖关系:
$$ \tilde{R}_{i,t} = \sum_{k=t}^T \gamma^{k-t} \tilde{r}_{i,k} $$
3. Surrogate Objective 优化策略
采用类似 GRPO/PPO 的 Clipped Surrogate Objective 机制,利用前文计算出的细粒度 Return 更新策略参数,并且仅对决策 Token(如 Reasoning, Tool calls, Answers)反向传播梯度:
$$ \mathcal{J}_{\text{IGPO}}(\theta) = \mathbb{E}_{\dots} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left( \frac{\pi_\theta(o_{i,t})}{\pi_{\text{old}}(o_{i,t})} \tilde{R}_{i,t}, \text{clip}(\dots) \right) - \beta \mathbb{D}_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) \right] $$
📊 实验设置与结论分析
实验配置: 基于 Qwen2.5-7B-Instruct 和 3B 版本作为基座。评测涵盖 4 个域内(In-domain,如 HotpotQA, 2Wiki)和 3 个域外数据集(OOD,如 Musique, PopQA),评估指标为 F1 Score。
核心结论速览:
一骑绝尘的 SOTA 表现: IGPO 在 7 个数据集上的平均得分为 60.2 ,远超当前热门的强基线(如 DeepResearcher 53.9,Search-r1-base 49.2),也全面碾压传统 RL 方法(如 PPO, RLOO, Reinforce++)。根治“小模型”优势坍塌症: 在 Qwen2.5-3B 上,消融实验显示,仅保留 Outcome Reward (即退化为标准 GRPO) 只有 32.3 分,加入 Information Gain 后得分狂飙至 48.9 分 (+16.6) 。这有力证实了致密奖励在拯救小模型“瞎猜全挂”时的定海神针作用。出色的 OOD 泛化与多跳推理能力: 相比 GRPO,IGPO 在 OOD 数据集上的提升甚至超过了 In-domain,在多跳(Multi-hop)问题上的提升也远大于单跳。这意味着模型学到了真正的长链推理法则,而不是单纯的死记硬背。更高的 Token 效率: 训练动态显示,随着使用 Token 数量的增加,IGPO 性能拉升极速,并且全周期维持稳定,彻底击碎了长程任务中样本利用率低下的痛点。
🌟 关键技术亮点分析
从资深算法从业者的角度来看,IGPO 的破局之处在于大道至简且极具工程落地价值 :
将 Teacher Forcing 作为无偏裁判: 当前构建 Process Reward 极易陷入 Reward Hacking(模型迎合外部奖励模型的偏好瞎写过程)。IGPO 创造性地利用模型自身的预测似然(Log-prob on Ground Truth)作为奖励,将“向答案靠拢”的微观物理量具象化。这种 Intrinsic 的监督信号不依赖外部黑盒,具有内生的抗 Hacking 属性。优雅破解雪球误差 (Snowball Error) 的数学论证: 论文附录甚至给出了严格的证明,论证了多轮推理中最终失败的下界是由每一步的信息丢失累积(雪球误差)决定的。IGPO 追求最大化各步的 Information Gain,数学等价于在遏制和逼近 Snowball Error 的积累上限,使得算法原理十分夯实。工程优化的极致: 强化学习由于采样成本高昂,常常让中小团队望而却步。作者提出的 Custom Attention Mask 将 $O(T)$ 复杂度的前向过程拍平成 $O(1)$。这种“白嫖”级的高效 Process Reward 计算方案,绝对是开源 Agent RL 训练框架(如 verl/OpenRLHF)未来必定吸纳的标配范式。
Reinforcement Learning for Long-Horizon Multi-Turn Search Agents
面向长周期多轮搜索Agent的强化学习
作者: Vivek Kalyan, Martin Andrews
机构: Red Cat Labs, Singapore 等
📄 查看 ArXiv 原文
背景与痛点 (Background & Pain Points)
在当前的LLM工程实践中,检索增强生成(RAG)已经成为解决幻觉和知识过时的标配方案。然而,主流的工业级RAG系统通常为了优化延迟(Latency)而采用“单轮检索(Single-turn RAG)”的范式,即一次性执行Keyword+Semantic搜索后直接把Top-K塞给大模型生成答案。这种朴素范式(Naïve RAG)在面对需要复杂探究、长上下文依赖的任务(如法律案例文档检索)时,表现出极大的局限性。
虽然通过Prompt Engineering赋予前沿模型(如Gemini 1.5/2.5 Pro或GPT-4o)使用工具的能力,可以让它们在一定程度上执行多轮搜索(Multi-turn search),但在长周期的交互场景中,仅靠Prompt激发的能力容易触及天花板。LLM在面对陌生工具或专有文档库时,缺乏“通过试错积累搜索策略”的能力,经常会在多次搜索无效后陷入死循环或产生幻觉。
核心贡献 (Core Contributions)
验证了RL在搜索Agent上的优越性: 基于法律领域的复杂多轮检索数据集,作者通过强化学习(RL)微调了一个14B参数的开源模型(Qwen3-14B),使其在搜索任务上的准确率达到 85%,超越了只能通过API调用的闭源SOTA模型 (如OpenAI o3的81%,Gemini 2.5 Pro的78%)。精巧的部分奖励机制(Partial Rewards): 设计了层次化的奖励塑形机制,有效解决了长周期交互任务中Reward稀疏的问题,并通过严厉惩罚“幻觉”而奖励“诚实地表示不知道(I don't know)”,使模型学会了更稳健的搜索策略。揭示了多轮交互长度(Turn Restrictions)对RL训练的影响: 证明了在训练和推理阶段,限制交互轮数会对模型性能产生巨大影响;并且,如果在RL训练时限制过严(如仅限2轮),模型由于无法在批量轨迹中获得足够多的正向反馈(Positive rollouts),GRPO算法将彻底失效。
具体案例剖析 (Case Study: Multi-turn Agent Workflow)
论文中采用的Agent交互逻辑是经典的 <think> -> <tool> -> Environment Response -> <answer> 循环。为了让读者直观理解RL训练后的模型如何执行多步探究,我们根据附录A.1的System Prompt重构一个典型的多轮法律搜索轨迹:
[用户提问] : "在2021年的SGCA判决中,法院对违约金的判定标准是什么?"
[Turn 1] - 宽泛探索 (Broad Exploration)
<think>
我需要先通过语义搜索或关键字搜索找到2021年SGCA(新加坡上诉法院)关于违约金的判决文件。
</think>
<tool>
{"name": "search_semantic", "args": {"query": "2021 SGCA liquidated damages standard", "num": 3}}
</tool>
[Environment]: 返回了 snippet 以及部分文档的ID,如 `2021_SGCA_3:judgement:introduction:p1`
[Turn 2] - 定向阅读 (Targeted Reading)
<think>
搜索结果提到了 2021_SGCA_3 案件涉及违约金的判定,但只给了摘要,我需要读取该判决书主体部分获取确切的标准。我会利用层次化ID向父节点跳跃。
</think>
<tool>
{"name": "read_document_part", "args": {"part_id": "2021_SGCA_3:judgement"}}
</tool>
[Environment]: 返回了整个案件的完整裁判段落。
[Turn 3] - 最终回答 (Final Answer Generation)
<think>
我已经掌握了足够的证据。该法院判定违约金必须是真实的预估损失,而不是惩罚性的。
</think>
<answer>
在2021年的SGCA判决中,法院判定违约金必须是对潜在损失的真实预估(genuine pre-estimate of loss),如果金额过高且属于威慑性惩罚,则该条款不可执行。
<sources>
<source>2021_SGCA_3</source>
</sources>
</answer>
解读: 这种两阶段搜索模式(广泛语义搜索 -> 定向读取完整内容)是很难仅通过Prompt就让模型稳健执行的,尤其是在格式严谨性(不能瞎编ID)和中途放弃(及时止损)的决策上,RL训练为模型提供了强大的策略直觉。
方法论与技术实现 (Methodology)
1. Agent 架构与工具集
模型在环境中共拥有三种工具:
Keyword search: 基于BM25的精确词匹配。Semantic search: 基于FAISS和all-MiniLM-L6-v2 embedding的相似度检索(返回包含段落ID和片段的Top-K)。Read document content: 根据传入的文档节点ID(XML层级结构如 A:B:C)读取全文。Agent可以主动截断ID实现向“父节点”跳转的功能。
2. 强化学习与GRPO训练设置
研究团队没有采用传统的PPO,而是采用了在数学推理领域大放异彩的 GRPO (Group Relative Policy Optimization) 。基础模型为仅 14B 参数的 Qwen3-14B ,训练时仅更新其 LoRA 权重以节约显存。为了支持长周期多轮Rollout所需的超长上下文,使用了 vLLM 结合 YaRN 将上下文窗口扩展至 128k tokens。每次训练步骤中,group_size 设为 6,产生多条轨迹供 GRPO 比较相对优势。
N轮交互的过程可用如下序列化表达:
$query \rightarrow response \rightarrow \{reformulate\ search \rightarrow response\}^{\wedge N} \rightarrow answer$
3. 巧妙的奖励函数设计 (Reward Shaping)
由于多轮检索是一项稀疏奖励任务,如果没有得到正确的答案,模型很难学习。作者设计了一套基于分段的行为约束规则(Behavioural bands) ,对中间过程(Partial Rewards)进行奖励和惩罚。这个设计对于落地应用极具参考价值:
[1.0, 2.0] : 最终答案正确且引用规范。轮次越少、搜索次数越少,得分越高(效率奖励)。[0.0, 1.0] : 战略性放弃奖励 。如果无法找到充分证据,模型主动回答“I don't know”。这被视为优于幻觉。[-1.0, 0.0] : 最终答案错误,但如果中间过程找到了正确的文档,给予 +0.1 的部分奖励分。[-2.0, -1.0] : 致命错误惩罚(如工具调用JSON格式错误、传入不存在的Document ID、参数无效等)。
在这个奖励体系下,幻觉(回答错误 [-1.0, 0.0])受到的惩罚远大于表示不知道([0.0, 1.0]) ,这迫使模型在证据不足时学会示弱,而不是胡编乱造。
实验设置与结论分析 (Experiments & Results)
1. 数据集准备
收集了5年的新加坡法院判决书,解析为保留层级结构的XML格式。通过Gemini 2.5 Pro生成问答对,经过严苛的难度与多样性过滤,最终形成 2300 个具备“Ground-truth文档+问答”的高质量评测对。
2. 核心性能对比
Model
Accuracy (%)
Avg. Turns
Naïve RAG (Gemini 2.5 Pro) 33 1.0 Qwen3-14B (Base, multi-turn) 53 3.7 Gemini 2.5 Pro 78 5.3 OpenAI o3 81 7.1 Qwen3-14B + RL (Ours) 85 6.2
结果显示,单轮朴素RAG准确率仅33%,说明任务极其依赖多步搜索。经过RL微调的14B模型,以85%的准确率越级战胜了OpenAI o3(81%)。
3. 轮数受限(Turn-restricted)的重要发现
推理阶段表现: 对于Base模型而言,限制其交互轮数为6轮或10轮,最终准确率并未继续增长(陷入了无意义的重复搜索)。但对于RL微调的模型和Gemini 2.5 Pro,它们表现出明显的复利效应:随着轮数上限放宽(如从5轮提升至10轮),准确率呈现单调递增态势。这说明Prompt-based方法缺乏长线探索的策略组合能力,而RL让模型学会了“利用更多轮次逐步逼近真相”。 训练阶段的致命限制: 如果在RL训练时强制将交互轮次限制为2轮,经过300步训练后,模型识别正确文档的准确率依然在 10-15% 徘徊(完全没有收敛)。原因在于,GRPO算法需要同Batch下有多条不同Reward的Trajectory对比 。在只有2轮的情况下,模型探索到正确文档的概率极低,导致训练批次内几乎全军覆没(没有足够多的正样本反馈信号),RL训练随之崩溃。因此,多轮能力训练必须留给Agent足够长的探索空间以发现“金子”。
关键技术亮点分析 (Key Highlights)
1. 从“教它怎么做”到“让它自己悟” :在LLM Agent开发中,传统的做法是写巨长无比的Prompt或者做SFT,这本质上是把人类搜索规律强加给模型;而这篇论文走通了通过RL对Tool-use行为进行优化的路子,模型自己通过与环境(法庭文件检索库)的Trial and Error,摸索出了最高效的搜索方式。
2. 极低成本的Verifiable Reward系统构建 :全文在RL训练中追踪了13个Metric,其中12个全都可以自动校验(Verifiable) (比如有没有触发正确ID的搜索、格式对不对、轮数是否用完等)。唯独“最终答案正误”需要动用Gemini 2.5 Pro做Judge。这种通过规则检查(格式/ID有效性)提供细粒度Reward的方式,大大降低了Agent RL的标注和计算成本,对工业界复现极具指导意义。
3. 解决“不知不觉的幻觉” :通过Reward机制设计(把瞎答错误奖励设为负,把承认不懂奖励设为正),论文用最直白的方式在强化学习层面规避了长链条Agent最头疼的“在没有证据时为了完成任务而编造事实”的问题。
基于对比动态分支采样训练多轮搜索Agent
英文标题: Training Multi-Turn Search Agent via Contrastive Dynamic Branch Sampling
作者: Yubao Zhao, Weiquan Huang, Sudong Wang, Ruochen Zhao, Chen Chen, Yao Shu, Chengwei Qin
机构: 香港科技大学(广州)、南洋理工大学
📄 查看 ArXiv 原文
一、研究背景与痛点
在强化学习(RL)赋能大语言模型(LLM)实现多轮规划和工具调用的浪潮中,长视距(long-horizon)Agentic RL 的训练目前面临着一个关键瓶颈:极度稀疏的轨迹级奖励(Trajectory-level outcome rewards)与信用分配(Credit Assignment)的模糊性 。
传统方法的低效: 常规方法如 GRPO 通常在整个轨迹结束时给出一个二元结果奖励(成功/失败),这种同质化归因无法指导模型识别长交互序列中“哪一步”做对了,“哪一步”做错了,导致梯度方差极高且经常引发训练崩溃(Training Collapse)。Tree-based 方法的计算代价: 现有试图缓解该问题的蒙特卡洛树搜索(如 Tree-GRPO,VinePPO)通过在中间节点分支展开来提供细粒度反馈。然而,这引入了高昂的计算开销,且在深层 rollouts 中同样受困于高方差,产生了大量的无效算力消耗。关键实证洞察(核心出发点): 作者通过对 SFT 后的多跳搜索 Agent 进行实证分析,发现了一个普遍规律:性能分化主要发生在决策轨迹的尾部(Tail) 。在同一个 Query 下,模型早期的搜索动作大多是正确且相似的;错误往往由于轨迹后期的“探索不足(过早结论)”或“基于检索内容的幻觉生成”引起。
这意味着,对于早期的可靠推理,没必要反复蒙特卡洛采样;我们只需要集中火力对轨迹尾部进行对比采样,就能获取信息量最大、最高效的训练监督信号。
二、核心贡献
基于上述洞察,本文提出了 BranPO(Branching Relative Policy Optimization) ,一种无需训练 Value 网络的、提供步级对比监督信号的强化学习算法。具体贡献包括:
提出 BranPO 框架: 从轨迹尾部截断并重新采样替代后缀(Suffixes),从而在固定的前缀(Prefix)上构建对比轨迹。这种方式不仅降低了长视距任务中信用分配的模糊性,还在数学上巧妙统一了 GRPO 和 DPO 的范式。引入难度感知分支采样(Difficulty-aware branch sampling): 动态分配分支计算预算。对于简单任务只做单次尾部分支,对于复杂或初始错误轨迹则递归地向后回溯分支,极大提高了探索效率和样本利用率。设计冗余步掩蔽机制(Redundant Step Masking, RSM): 有效识别并抑制 Agent 训练中容易出现的无意义重复调用工具行为,缓解了因过度采样导致模型养成验证强迫症的偏差。
三、具体案例剖析
作者分析了长视距搜索任务中失败轨迹的典型 Case,以此说明常规 Trajectory-level RL 在纠偏时的乏力,以及为何需要在尾部进行干预:
Case 1: 搜索不足导致过早下结论 (Insufficient Search) 输入: 印度产生收入最多的州的财政部长是谁?Shared Trajectory (共享前缀): 模型首先正确地搜索了“产生最高收入的州”,并在阅读结果后推理出是 Maharashtra(马哈拉施特拉邦)。接着搜索了其财政部长。Failure Suffix (错误分支): 由于检索出的维基文档包含了前任部长和现任中央部长,模型在没有更新信息的情况下,错误地输出了 2014-2015 年的前部长 Eknath Khadse。BranPO 期望的 Success Suffix (成功分支): 如果我们在决策尾部强制重新探索,模型会生成新的查询动作 <search> current finance minister of Maharashtra </search>,继而定位到正确的现任部长 Sudhir Mungantiwar。洞察: 错误不是前置查询的锅,而是最后一步缺乏确认的锅。如果用普通 GRPO,模型早期的优秀检索也会一并被判定为“负奖励”。Case 2: 冗余步骤 (Redundant Steps) 输入: 《The Confidential Clerk》的作者是谁?表现: 模型在第一步搜索 The Confidential Clerk book 后,检索文档已经明确写了 "comic verse play by T. S. Eliot"。然而,由于不自信或策略漂移,模型接着又发起两轮毫无意义的搜索(如 who wrote the confidential clerk play by t.s. eliot),最后才给出答案 T. S. Eliot。解决方案: 这种冗余虽然结果是正确的(Reward=1),但会导致动作效率极低。BranPO 的 RSM 机制 通过识别在同一共享前缀下存在步数更短的正确分支,直接将多余动作的 advantage 屏蔽为 0。
四、方法论与技术实现
BranPO 的核心思想是通过将决策树裁剪为“共享前缀+差异后缀”,实现低开销、高方差缩减的策略优化。
1. 难度感知动态采样 (Dynamic Branching)
为了控制开销,BranPO 在初始 rollout 后评估任务难度。假设生成了 $N$ 条轨迹:
如果该 prompt 下的初始 Accuracy 极高,属于简单任务,则只在最终生成步尝试替换分支;若发现回答冗长,则触发冗余检测(Redundancy Detect)。
对于低准确率(困难任务)或失败轨迹,算法从最后一个 action 往前进行递归回溯(Recursive Branching),直到采样到一个具有不同奖励结果的对比分支(Contrastive Suffixes)。这样可以确保每次消耗算力构造的树枝,都能提供高纯度差异信号。
2. 分支相对优势评估 (Branching Advantage Estimation)
对于一条带有分支的轨迹,BranPO 将奖励分解给“前缀 $B$” 和“后缀 $C$”。假设在前缀 $B_{q,n}$ 后采样出了多个分支集合 $\mathcal{C}_{q,n}$。
共享前缀 (Base Advantage): 其奖励由其后继所有分支的奖励平均值定义:
$$r_{\text{base}}^{(q,n)} = \frac{1}{|\mathcal{C}_{q,n}|}\sum_{i=1}^{|\mathcal{C}_{q,n}|}r_{\text{branch}}^{(q,n,i)}$$
随后在同个 prompt 的组内进行标准化得到 $\hat{A}_{\text{base}}^{(q,n)}$,并更新给所有前缀 Token。差异后缀 (Branch Advantage): 分支动作独立更新,利用同组内所有分支的统计量计算:
$$\hat{A}_{\text{branch}}^{(q,n,i)} = \frac{r_{\text{branch}}^{(q,n,i)} - \mu_r^{\text{branch}}}{\sigma_r^{\text{branch}}}$$
3. 数学本质揭秘:GRPO + DPO 的缝合怪
作者在附录 B 提供了一个优雅的数学推导,证明了 BranPO 的理论优越性:
对于前缀部分,BranPO 是一个低方差的 GRPO ,因为前缀汇聚了多个分支的期待奖励 $Q^{\pi_\theta}(B)$;直接偏好优化 (DPO) 类型的更新 :
$$\nabla_\theta \mathcal{L}_{\text{suffix}} \propto \nabla_\theta \log \pi(C^+ \mid B) - \nabla_\theta \log \pi(C^- \mid B)$$
通过在一个错误分支和一个成功分支间构建隐式偏好对,强行拉开其概率差。这种将“轨迹级试错”无缝转化为“步级别排序学习”的做法,解释了其样本效率暴增的根本原因。
五、实验设置与结论分析
实验配置: 基于 ASearcher 提供的局部搜索引擎,采用 Qwen2.5-7B-Instruct 和 Qwen3-4B-Instruct 作为基座(均先通过过滤后的高质量数据执行过 1 epoch SFT 冷启动)。对比方法包含 SFT、GRPO、GiGPO(仅第一阶段)以及 Tree-GRPO。
核心结果分析:
多跳 QA 性能全面碾压: 在限制最多 4 步搜索的第一阶段中,BranPO 在 HotpotQA、2WikiMultihopQA 以及未见过的 MuSiQue、Bamboogle 上不仅在 F1 分数上显著超越了 GRPO (如在 Qwen2.5-7B 的 HotpotQA 上提升至 60.9% 对比 58.6%),在 LLM-as-a-Judge 评估上也拉开了差距。相比 Tree-GRPO,BranPO 也显示出更强的性能。扩展交互上限至 8 步的稳定性: 长视距任务最怕探索崩溃。当允许最大 8 步交互时,常规 GRPO 虽然性能有所提升,但其平均搜索步数暴增,大量无用功;而 BranPO (配合 RSM 机制) 不仅将多跳任务 F1 指标继续推高 (7B 模型 Avg 达到 59.2 vs GRPO的 58.9),且平均搜索步数保持在一个更合理的低位阈值,避免了“陷入无限死循环”。真实网络泛化能力: 在难度极高的 GAIA 基准测试(带真实网页检索与摘要)上,BranPO 同样比 GRPO 高出约 4-5个百分点,证明该算法不仅仅是一个“刷榜技巧”,也能应对真实开放域的高噪声环境。训练耗时: 得益于 BranPO 的“动态截断”和“难易度分发”,其构建分支额外消耗的 Rollout 时间,被更高效稳定的收敛所抵消(不需要那么多梯度步),总 Wall-clock time 与普通 GRPO 近似持平,比全局建树的 Tree-GRPO 快得多。
六、关键技术亮点分析(从业者视角)
颠覆直觉的“尾部病理学”洞察: 当前很多研究致力于构建复杂的完整动作树或者做全局的 MCTS,但本文作者敏锐地指出:SFT 后的基座其实已经具备了基础的长程规划前置能力,它们的病灶集中在最后阶段的收尾。这种将好钢用在刀刃上的思路,极大释放了工程算力。低成本获得稠密奖励的典范: 如何绕开昂贵的 Reward Model 提供单步奖励?BranPO 给出的答案是:不要评估中间步绝对好坏,只评估“从当前状态出发,不同决策的相对收益”。这种伪装成 RL 的 DPO 机制,对缓解搜索中高方差噪音是一剂猛药。RSM (Redundant Step Masking) 解决业务痛点: 在许多企业内部的 Agent 落地场景中,模型经常会出现不自信反复检索同一个 Query,或者搜到答案后仍然继续搜的毛病。RSM 将长度惩罚与 Advantage 隔离的设计,是一个非常有实战意义的 Trick。局限与挑战: 正如作者在 Future Work 中提及,当前限制在最多 8 步左右,若是真实环境中高达 30+ 步骤的深度检索任务(如 DeepSeek-R1 式搜索),BranPO 的局部截断能否覆盖全域误差依然是个未知数,可能仍需结合更严苛的显式效率正则。