Case-Based Calibration of Adaptive Reasoning and Execution for LLM Tool Use
基于案例校准的自适应推理与LLM工具调用执行框架
作者:Renning Pang, Tian Lan, Leyuan Liu, Piao Tong, Sheng Cao, Xiaosong Zhang
机构:电子科技大学 (UESTC)
背景与痛点
工具调用(Tool Use)是当前大语言模型(LLMs)走向 Agentic 系统的核心能力。然而,现有的工具调用模型在处理异构任务时面临两大痛点:
- 统一推理策略(CoT)的低效性: 传统的强化学习(RL)或 SFT 倾向于让模型形成固定的“思考”模式。对于简单的查询,模型经常过度思考(Overthinking),导致冗长且易引发错误;而对于复杂的长程规划,推理深度又往往不够。如何动态分配推理预算(Reasoning Budget)是一个难题。
- 稀疏/粗粒度的 RL 奖励机制: 标准的 RL 往往只能给出端到端的成功与否(如 API 是否调用成功),这种粗粒度的反馈(Coarse Reward)带来了严重的信用分配问题(Credit Assignment)。模型很难搞清楚失败是因为工具选错了、Schema(参数格式)违反了约束、还是参数类型(Type Mismatch)不匹配。
核心贡献
为了解决上述问题,本文引入了基于案例推理(Case-Based Reasoning, CBR)的视角,提出了 CAST (Case-driven Adaptation for Schema-faithful Tool use) 框架。其核心逻辑是将历史执行轨迹(Trajectories)作为结构化的“经验案例”,从中提取细粒度信号来指导 GRPO 强化学习:
- 复杂度画像(Complexity Profile): 从历史案例中评估任务的难度(Hardness),进而为不同任务自适应地设定不同的推理预算基线。简单任务严惩冗长推理,复杂任务保留思考空间。
- 失败画像(Failure Profile): 针对工具调用过程中的常见结构性崩溃(如:函数名错误、键值遗漏、类型不匹配、约束冲突等),构建细粒度的、可解释的多维度 Reward,专门优化工具输出的 Schema 忠实度。
- 端到端性能与效率双升: 在 BFCLv2 和 ToolBench 上,CAST 相比标准 GRPO 不仅提升了 5.85% 的整体执行准确率,还平均降低了 26% 的推理 token 消耗(即缩短了无意义的 CoT 长度)。
具体案例剖析 (Case Study)
论文通过 Easy 和 Hard 两个具体 Case 展现了 CAST 是如何实现“自适应推理”和“Schema 忠实度”的(对应原论文 Fig. 7 & 8):
Case 1: 简单查询 (Easy Instance)
Query: "Could you check the current weather conditions in Beijing and New York City for me?"
痛点表现: 此时 GRPO 训练出的模型开始了冗长的“无用内耗”。其内部 CoT 思考了“是否会有高并发 429 报错”、“是否要加微小延迟”、“串行还是并行”等完全不需要在当前简单 API 下考虑的问题。
CAST 表现: 由于识别到该类 Case 复杂度低,模型被直接阻断了过度思考,迅速生成了极为简练的 Reasoning(仅一句规划),随后精准并发输出了两个 get_current_weather 调用。
Case 2: 复杂长序列查询 (Hard Instance)
Query: 包含计算密度(质量 50kg, 体积 10m³)、计算未来价值($5000 本金,5% 利率,10年)、苹果股价、亚马逊评分等多个并行复杂指令。
痛点表现: SFT 和 GRPO 模型在参数提取上犯了表面模式匹配的错误。例如把 Query 中的 "5%" 直接以整数 5 传给了 interest_rate 参数,导致 API 类型报错或数值溢出。
CAST 表现: 对于高复杂度 Case,CAST 保留了充足的 Reasoning Budget。模型在 CoT 中显式推理出“利率必须精确转换,5% = 0.05(小数)”,最终成功传参 (5000, 0.05, 10),避免了 Schema 和 Value 维度的崩溃。
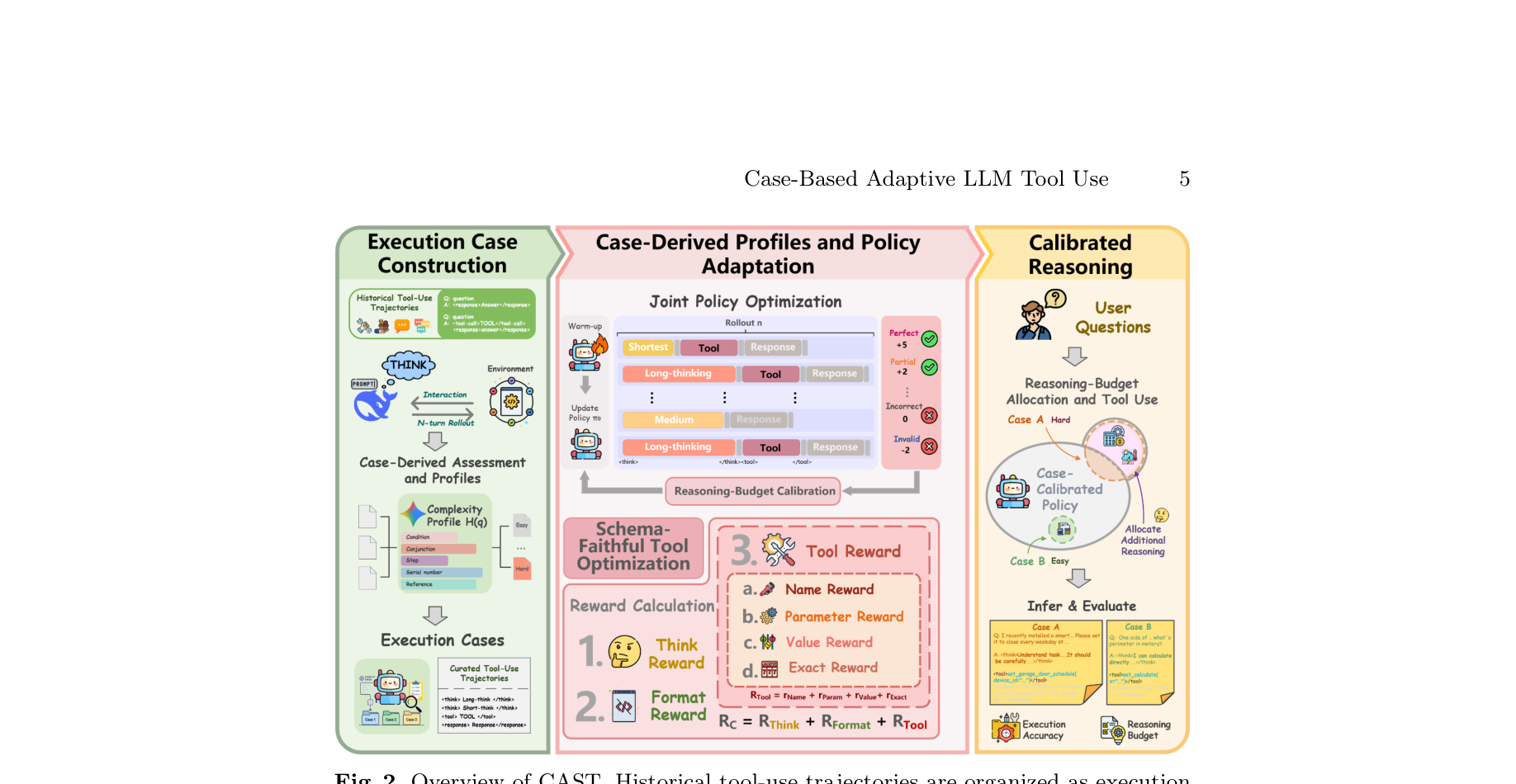
方法论与技术实现
CAST 的核心是将历史经验转译为强化学习的 Dense Reward,其训练管线包含两个极其优雅的解耦设计:
1. 复杂度画像驱动的“推理预算校准” (Reasoning-Budget Calibration)
为了让模型“难事多想,易事少想”,CAST 定义了一个难度得分 $H(q) \in [0, 1]$(借由验证器和外部强模型打分得到)。基于此得分,模型为每类难度 $d(q)$ 设定一个动态的长度基线 $L_{emp}^{d(q)}$:
$$ \rho(q, L) = \max\left(0, \frac{L}{L_{emp}^{d(q)}} - 1\right) $$
此时 $\rho(q, L)$ 表示当前生成的思考长度超标了多少。巧妙之处在于引入了一个随难度反向变化的门控权重 $\lambda(q) = 1 - H(q)$:
$$ \alpha(q, r_a, L) = \max(0, 1 - \lambda(q)\rho(q, L)) \quad (当回答正确 r_a > 0 时) $$
精髓解析: 如果题目很简单($H(q) \approx 0$),那么 $\lambda \approx 1$,长度超标 $\rho$ 会极其严重地衰减总 Reward;如果题目极难($H(q) \approx 1$),则 $\lambda \approx 0$,惩罚项失效,模型可以放心大胆地使用长 CoT 来确保正确率。这种设计通过 Reward Shaping 完美重塑了策略模型的输出长度分布。
2. 失败画像驱动的结构化奖励 (Schema-Faithful Optimization)
仅仅答案对还不够,API Schema 必须完全遵循。CAST 使用最大权值二分匹配(Maximum-weight Bipartite Matching)来对齐生成的 Tool Calls 和 Ground Truth。随后,奖励不仅是一个二元判断,而是被解构为六维向量:
$$ \mathbf{r}_{tool} = (r_{name}, r_{key}, r_{type}, r_{constraint}, r_{value}, r_{exact})^\top $$
比如:函数名对没对(Jaccard 覆盖率)?必填参数 key 有没有遗漏?参数 type 是否合法?这一机制极大缓解了 Tool Use RL 中的信用分配难题。
3. GRPO 复合奖励与课程学习优化
整体强化学习建立在 Group Relative Policy Optimization (GRPO) 框架上,其复合奖励定义为:
$$ \mathcal{R}_C = \mathcal{R}_{Think} + \mathcal{R}_{Format} + \mathcal{R}_{Tool} $$
此外,作者利用复杂度标签 $H(q)$ 组织了一套 Easy-to-Hard 的课程学习 (Curriculum Learning),实验证明这能有效防止模型在早期接触过难样本时陷入崩溃性的“无脑输出长 CoT”困境。
实验设置与结论分析
- 测试基准: BFCLv2 (Berkeley Function Calling Leaderboard v2) 和 ToolBench。涵盖单论、并行、多步及无关 API 抑制。
- 基座模型: Qwen2.5-7B/Coder-7B-Instruct, Llama-3.2-8B-Instruct 等。
- 性能表现 (Performance):
- 在 Qwen2.5-7B-Instruct 上,CAST 的整体执行准确率达到 88.43%,相比 SFT 提升 5.85 个百分点,相比标准 GRPO 提升 4.76 个百分点。
- 在 ToolBench 任务成功率上,Pass 率跃升至 80.67%。
- 代价锐减: 相比于无预算限制的基线(平均 486.2 tokens 长度),CAST 将平均思考长度压缩到了 175.4 tokens(下降约 26%~64% 视基线而定),同时准确率不降反升,实现了推理计算力的高效分配。
- 消融实验结论: 去掉 Schema Reward 会让模型在长尾工具执行中频频出错;去掉 Adaptive Budget 会让模型陷入过度思考困境;打乱课程学习(改为 Hard-to-Easy)会导致模型平均思考长度暴增到 426 tokens 且准确率触底。
关键技术亮点分析 (Takeaways for Practitioners)
- 打破“思考越长越好”的迷思: 最近 o1/R1 等模型掀起了 Scaling Test-Time Compute 的浪潮,但对于工具调用(本质是确定性的软件接口交互)而言,简单任务的冗长 CoT 会显著增加解析崩溃、幻觉编造以及 API 超时的风险。CAST 给出的按难度动态施加长度惩罚的方案,在落地 Agent 项目中极具借鉴价值。
- 将错误日志转化为 Dense Reward: Tool-use 的难点在于执行失败时模型不知道错在哪。CAST 通过预先定义的维度(name/key/type/value)构建二分图匹配计算 Reward,相当于手搓了一个极度精细的
Auto-Evaluator,这是超越单纯依靠“LLM as a Judge”给出一个抽象大分数的关键工程提升。 - RL 稳定性工程: 从 Normalized Advantage Variance 图表可以看出,由于 Reward 的方差被细粒度解耦和限制,CAST 使得 RL 训练更加平稳(方差从 0.48 降至 0.10),大幅减少了策略在“过度思考”和“盲目动作”两极之间的剧烈震荡。