SkillGenBench: Benchmarking Skill Generation Pipelines for LLM Agents
作者:Yifan Zhou, Zhentao Zhang, Ziming Cheng, Shuo Zhang, Qizhen Lan, et al.
机构:上海交通大学、西安交通大学、新加坡国立大学、QuantaAlpha、清华大学等
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文抓住了一个很被低估的问题:今天很多 LLM Agent 论文评测的是“会不会用 skill”,而不是“能不能从 repo / 文档里自动生成高质量 skill”。现实生产里,后者其实更关键,因为 Agent 真正落地时,常常面对的是零散 API 文档、工程脚本、依赖配置和隐式操作约束,而不是别人预先写好的完美工具说明。
论文认为,把 runtime problem 和 skill generation problem 混在一起评,会掩盖 skill 抽象能力本身的优劣。所以作者提出 SkillGenBench,把“技能生成管线”单独拿出来评估。
核心贡献
- 提出首个专门面向 skill generation pipeline 的 benchmark。
- 区分 task-conditioned 与 task-agnostic 两种生成场景。
- 同时覆盖 repository-grounded 与 document-grounded 两类知识源。
- 建立动态 pass@3 与六维静态诊断联合评估框架。
具体案例剖析
典型案例之一是从图像风格迁移仓库中提炼 AnimeGANv3 skill:模型若没抽取到关键的 BGR↔RGB 前后处理约束,下游 agent 虽然“调用成功”,输出图却会严重偏色。另一个案例是从 Faker 文档中蒸馏一个合成用户数据 skill,如果遗漏 fake.unique.user_name() 或 seed 固定逻辑,就会在 artifact 级验证中失败。
这类例子说明:真正难点不是“API 名字记住了没有”,而是能否把隐含工程约束压缩进一个可复用的 procedural package。
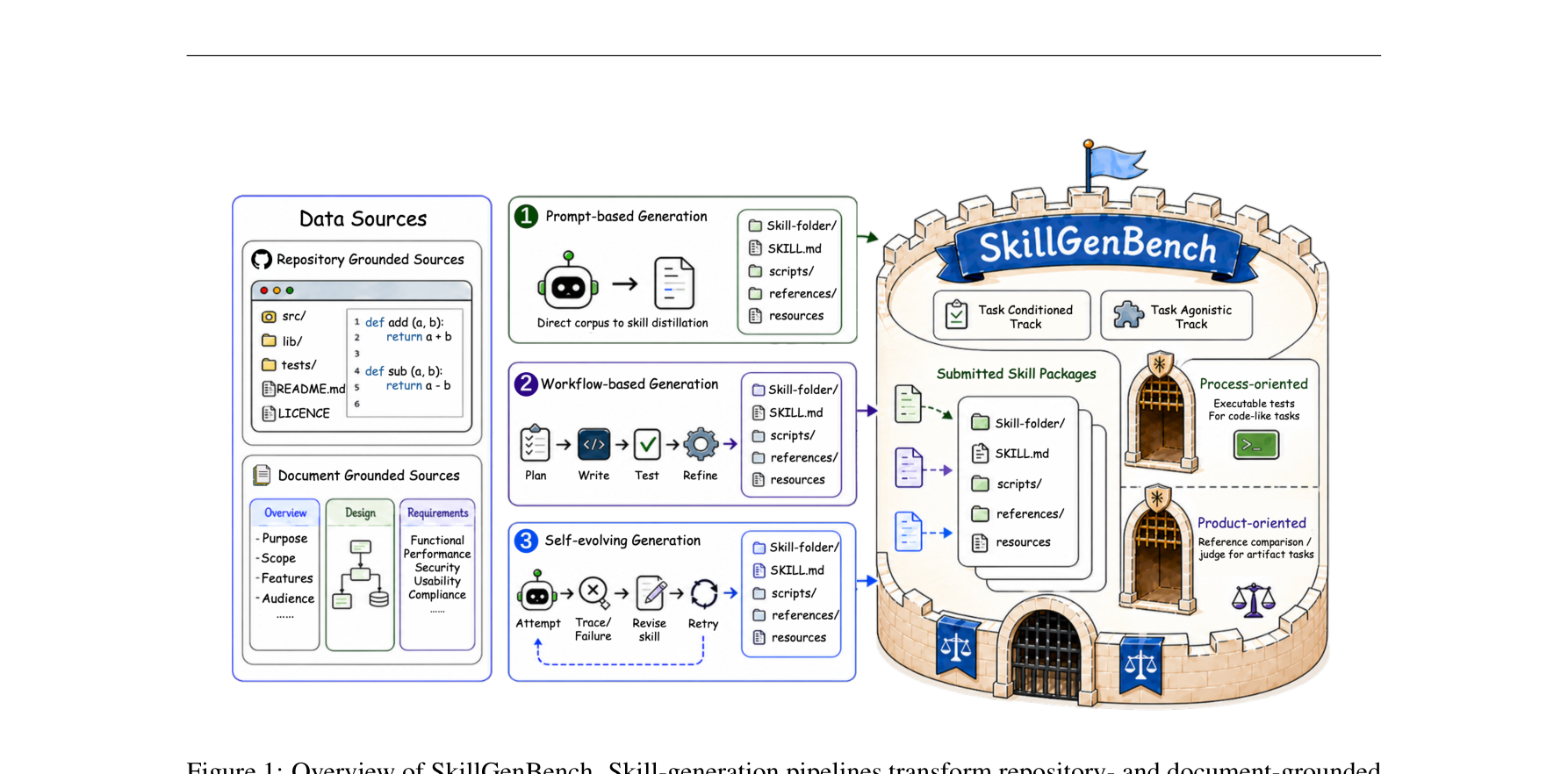 图注:SkillGenBench 将原始 repo / doc 经技能生成管线压缩成标准化 skill,再交给统一 executor 评测。
图注:SkillGenBench 将原始 repo / doc 经技能生成管线压缩成标准化 skill,再交给统一 executor 评测。方法论与技术实现
它的核心流程是:原始知识源 $
ightarrow$ 任务构造 $
ightarrow$ skill generation $
ightarrow$ blind execution。为了把评估对象聚焦在 skill 本身,作者把生成出的 SKILL.md / skill package 丢给下游 executor,在隐藏原始上下文的情况下做盲执行。评分既看 execution,也看 artifact correctness。
论文还做了静态分析,将技能包拆成 Contract、Environment、Grounding、Procedure、Constraints、Safety 六个维度做诊断。这个设计很实用,因为它能告诉你失败到底是环境没闭环、约束没保留,还是接口抽象错位。
实验设置与结论分析
结果很扎心:即便是强模型配强 pipeline,Code 类任务的 pass@3 也只在十几个百分点量级,Doc 类任务略好但依然不高。这说明从杂乱工程上下文中抽象“可执行技能”,远比大家想象得难。
另一个重要发现是 repo-grounded 明显比 doc-grounded 难,因为 repo 里的关键知识往往隐含在目录结构、依赖、调用链和脚本副作用中,而不是明明白白写在文本里。
关键技术亮点分析
- 从 prompt augmentation 转向 skill synthesis:这是 agent engineering 下一阶段必须补的能力。
- 静态高分不等于动态可执行:很多 skill“看上去像样”,但一到真实环境就崩。
- 对 LLM 从业者的启发:以后评 agent,不能只评 end-to-end 成功率,还得评中间抽象工件的质量。
Position: A Three-Layer Probabilistic Assume-Guarantee Architecture Is Structurally Required for Safe LLM Agent Deployment
作者:Saddek Bensalem 等
机构:CSX-AI、利物浦大学、奥尔登堡大学、AIT、格勒诺布尔-阿尔卑斯大学等
📄 查看 ArXiv 原文研究背景与痛点
这是一篇非常“架构论”的论文。它不讨论某个 guardrail trick,而是直接质疑:为什么我们总想用单层安全方案保护 LLM Agent?作者认为这是结构性错误。因为 agent 安全涉及语义合规、环境有效性、连续控制可行性三类不同信息,而这些信息在执行链路的不同阶段才出现,根本无法在单层里一次性验证完。
核心贡献
- 证明单层或双层防护在结构上不足以保证安全 agent 部署。
- 提出 User / Operational / Functional 三层概率假设-保证架构。
- 给出系统级安全概率组合边界。
- 总结 runtime assurance 在 LLM Agent 场景下的开放问题。
具体案例剖析
论文用护理机器人案例说明三层如何配合:上层先检查计划是否违反休息时段和隐私约束;中层在接近病房时根据传感器判断场景是否超出 ODD;底层用控制屏障函数保证不会撞人。若底层发现家具挪动导致路径失效,再把失败信号往上传,触发重新规划。
方法论与技术实现
三层分别对应不同信息集:$\mathcal{I}_U$ 关注意图与策略合规;$\mathcal{I}_O$ 关注环境状态与 ODD 约束;$\mathcal{I}_F$ 关注连续控制与实时物理安全。系统安全不再被视作单一布尔事件,而是组合概率边界:
$$\Pr(\mathrm{safe}) \ge \max(0, p_U + p_O + p_F - 2)$$
更精确时可写为链式分解 $\Pr(\mathrm{safe}) = p_U \cdot p_{O|U} \cdot p_{F|OU}$。这类表达的价值在于:它强迫系统设计者明确每层到底在保证什么、依赖什么。
实验设置与结论分析
它不是一篇 benchmark 论文,而是通过边界实例化说明系统设计原则。作者给出不同层成功率下的整体安全下界,展示任何单层增强都无法弥补另一个层面的结构缺口。这个结论对 agent safety 工程特别有用:别再迷信某一个万能护栏了。
关键技术亮点分析
- 信息驱动而非工件驱动:安全验证必须跟着信息流走。
- 从确定性证明转向概率组合:更符合 LLM Agent 的真实形态。
- 对多 Agent 的启发:未来还需要把消息来源与 provenance 纳入新的安全层。
STT-Arena: A More Realistic Environment for Tool-Using with Spatio-Temporal Dynamics
作者:Tingfeng Hui, Hao Xu, Pengyu Zhu, Hongsheng Xin, Kun Zhan, Sen Su, Chunxiao Liu, Ning Miao
机构:香港城市大学、北京邮电大学、理想汽车等
📄 查看 ArXiv 原文研究背景与痛点
很多 tool-use benchmark 其实都太“顺滑”了:环境静态,工具接口稳定,错误可预测。但真实 agent 应用不是这样。任务执行中途环境会变,旧计划会突然失效。STT-Arena 要测的正是这件事:LLM 有没有能力在时空动态变化下做 adaptive replanning,而不是仅仅会按既定 happy path 调 API。
核心贡献
- 提出覆盖九类冲突、四种可解性的时空动态 benchmark。
- 总结三类典型失败模式:Stale-State Execution、Misdiagnosis、Missing Post-Adaptation Verification。
- 提出基于迭代轨迹优化与在线 RL 的 STT-Agent-4B。
具体案例剖析
典型失败场景包括:系统状态变化后,模型不去重新查询最新状态,而是盲目猜 ID 重试;把“资格不满足”误诊成参数错误;切到备用方案后也不验证最终全局目标是否真的完成。这些错误和现实 agent 部署时常见事故高度一致。
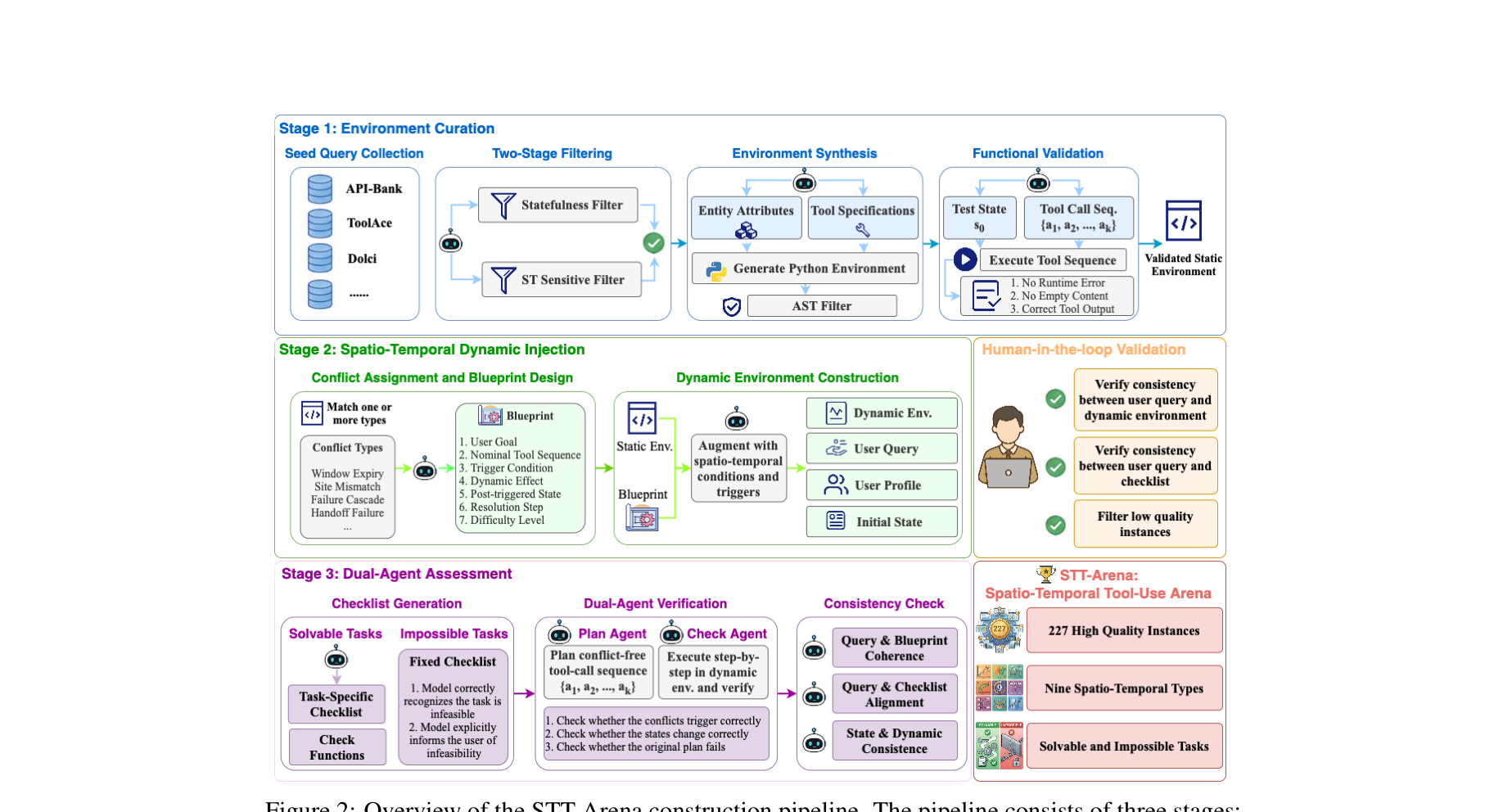 图注:STT-Arena 的数据构建流程,从静态环境筛选、动态触发器注入到双智能体验证闭环。
图注:STT-Arena 的数据构建流程,从静态环境筛选、动态触发器注入到双智能体验证闭环。方法论与技术实现
作者先从可执行环境中筛选适合的 stateful task,再注入时空触发器,最后用 plan-agent 与 check-agent 验证原计划会不会在动态环境中被打断。它的评估关注的是模型能否检测状态变化、重建计划并验证最终结果。总分本质上是不同难度段表现的加权和:
$$Overall = �lpha P_e + �eta P_m + \gamma P_h + \delta P_i$$
实验设置与结论分析
最强闭源模型总体准确率都不到 40%,说明“动态重规划”还远不是 solved problem。更有意思的是,作者用迭代式 failure-cleaning 加在线 RL 训了一个 4B 模型,居然能逼近甚至超过一些更大的通用模型。这说明 agent 场景里,高质量 recovery trajectory + verifiable RL 的价值非常高。
关键技术亮点分析
- 它测的是状态维护能力,不只是工具编排能力。
- 错误诊断是 agent intelligence 的核心组成部分。
- 对工业界的意义:如果你的 agent 要上生产,必须引入 post-adaptation verification,而不是工具成功就宣布任务完成。
LLM-Guided Communication for Cooperative Multi-Agent Reinforcement Learning
作者:Sangjun Bae, Yisak Park, Sanghyeon Lee, Seungyul Han
机构:UNIST Graduate School of Artificial Intelligence
📄 查看 ArXiv 原文研究背景与痛点
在 cooperative MARL 里,通信通常被当成“学一个 message vector 就完了”的问题,但作者指出,这样的目标太模糊。通信真正应该服务的是 state reconstruction:让每个 agent 在局部观测下尽量准确、均匀地恢复潜在全局状态。否则你可能学到了很多消息,却没有真正提升协同质量。
核心贡献
- 提出 LMAC:让 LLM 离线设计通信协议代码,而不是在线直接参与决策。
- 用 state-awareness criterion 给 LLM 提供可量化的 Reflexion 反馈。
- 引入元认知表征学习模块,提升消息的有效性与均衡性。
具体案例剖析
在星际定制任务里,拥有全局视野的 Overseer 需要把目标位置传给多个视野极差的 Banelings。LLM 第一版协议只传相对偏移,不够;第二版加入位置信息;第三版继续缓解 knowledge imbalance,最终所有 agent 都能更稳定地重建关键状态并形成协同攻击。
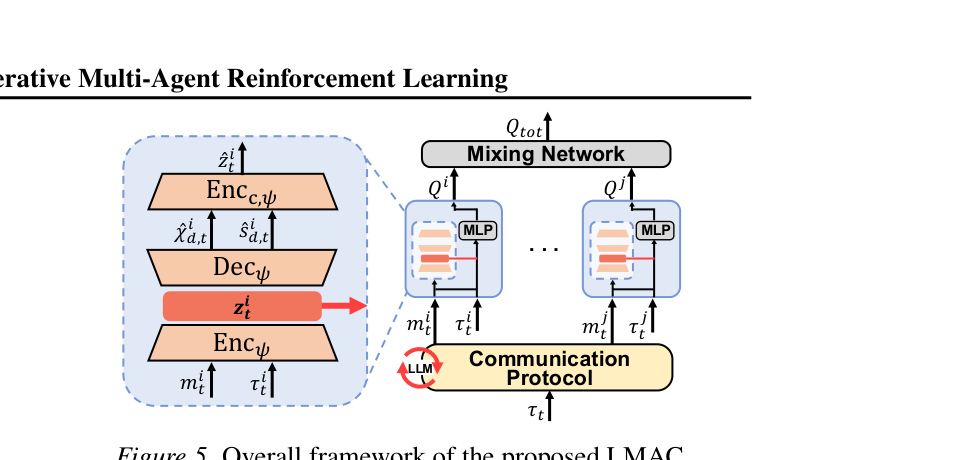 图注:LMAC 将协议设计放到离线 LLM 反思环中,在线阶段则由 RL 与表征学习模块高效执行。
图注:LMAC 将协议设计放到离线 LLM 反思环中,在线阶段则由 RL 与表征学习模块高效执行。方法论与技术实现
这篇论文最妙的点是把“LLM 会推理”转化成“LLM 会写通信协议代码”。也就是让大模型做 protocol compiler,而不是在线高频 agent。作者定义 state-awareness indicator 来量化消息对状态恢复的价值:
$$ \chi_{l,d,t}^{i} = \mathbb{I}[\|\hat{s}_{l,d,t}^{i}-s_{d,t}\|_2^2 \le �lpha] $$
随后从恢复成功率和知识不平衡度两类统计量中构造反馈,驱动 LLM 迭代修协议。在线阶段则通过 encoder-decoder 和 cycle-consistency 学一个更稳的 latent 表征,并与 TD loss 联合优化:
$$ \mathcal{L}=\mathcal{L}_{TD}+\mathcal{L}_{recon}+\lambda_{cons}\mathcal{L}_{cons} $$
实验设置与结论分析
在 SMAC、LBF、GRF 等基准上,LMAC 显著优于 TarMAC、SMS 等传统通信方法。更重要的是,它把 LLM 成本控制得非常低:离线少量 API 调用就能设计出高质量协议,在线执行完全不需要把 LLM 放进 loop。这在工程上非常现实。
关键技术亮点分析
- LLM as compiler,而非 runtime controller,这条路线很值得 Agent+RL 借鉴。
- Reflexion 反馈必须定量化,而不是只给模糊自然语言评价。
- 协议代码比隐式 message vector 更可审计、更可移植。
Beyond Inference-Time Search: Reinforcement Learning Synthesizes Reusable Solvers
作者:Soheyl Massoudi, Gabriel Apaza, Milad Habibi, Mark Fuge
机构:ETH Zürich, University of Maryland
📄 查看 ArXiv 原文研究背景与痛点
LLM 做组合优化时,很多方法仍然把推理成本留在 test time:反复采样、search、best-of-N、self-refine。作者问了一个很好的问题:能不能把这部分 reasoning cost 搬进训练,让 code LLM 直接学会为整个问题族生成 reusable solver,而不是每道题都重新搜?
核心贡献
- 提出把 solver synthesis 作为 RL 优化目标,而不是把 search 永远放在测试期。
- 在 SDS 上展示 RL 可显著缩小与 virtual best solver 的差距。
- 证明训练后的 solver synthesis policy 在成本上远优于累计 Best-of-64 搜索。
具体案例剖析
在 SDS 任务中,基础 code model 往往能“想起” Simulated Annealing 模板,但会把关键 acceptance rule 写错,导致 search 虽多却不稳。RL 后的模型则学会稳定生成 constraint-aware 的 solver 模板。换句话说,它学到的不是某题答案,而是一类问题的求解程序。
 图注:核心思想是用 RL 将求解结构内化为 reusable solver synthesis policy,而不是依赖每次推理时的搜索。
图注:核心思想是用 RL 将求解结构内化为 reusable solver synthesis policy,而不是依赖每次推理时的搜索。方法论与技术实现
作者用 GRPO 微调 Qwen2.5-Coder-14B-Instruct,让模型输出 solver 程序,并依据程序执行后的 objective + feasibility 给奖励。训练目标可以理解为:
$$ \max_{ heta}\; \mathbb{E}_{x\sim \mathcal{D}} [R(\mathrm{execute}(\pi_{ heta}(x)))] $$
本质上,这是把 search amortization 做到了模型参数里。相比 best-of-N inference,它追求的是“程序级可复用能力”。
实验设置与结论分析
在 SDS 上,Best-of-64 采样和代码审计都显示基础模型难以稳定写对 solver;而 RL 后策略几乎总能产出约束感知的退火模板,离最优求解器差距明显缩小,且后续执行/搜索成本大幅下降。附加的 Job Shop Scheduling 结果也表明这种范式有一定迁移性,但当前仍依赖 domain-specific scaffold。
关键技术亮点分析
- 这是“把推理预算搬进训练”的典型范例。
- Program as policy:代码工件就是显式策略,便于审计和复用。
- 对 Agent 的启发:很多高频重复任务,也许更该学习 reusable solver / skill,而不是永远在线 tree search。