Scaling Retrieval-Augmented Reasoning with Parallel Search and Explicit Merging
通过并行搜索和显式合并扩展检索增强推理
👨🔬 作者:Jiabei Liu, Wenyu Mao, Junfei Tan, Chunxu Shen, Lingling Yi, Jiancan Wu, Xiang Wang
🏢 机构:中国科学技术大学 (USTC),腾讯微信技术架构部
🔗 链接:📄 查看 ArXiv 原文
🔍 研究背景与痛点
大语言模型 (LLMs) 在知识密集型任务中通常依赖于静态内部知识。虽然检索增强生成 (RAG) 缓解了这一问题,但在处理复杂问题时,单次检索往往不够,这催生了深度搜索智能体 (Deep Search Agents) 的发展(如基于 ReAct 范式的多步检索推理)。然而,现有的深度搜索框架在具体实践中暴露出了两个核心瓶颈:
- 检索的信噪比 (SNR) 极低:现有方法在每个推理步骤通常只生成单个查询 (Single Query)。面对多跳或者包含多个实体/子问题的复杂任务,单查询只能获取局部信息。如果生成的 query 存在歧义或与语料库存在词汇不匹配,还会召回大量不相关噪声,导致整个推理上下文的信噪比急剧下降,从而引发模型产生幻觉或陷入无意义的循环搜索。
- 细粒度中间过程监督的缺失:最近基于强化学习 (RL) 的 Agent 训练(如 Search-R1)通常依赖于结果级奖励 (Outcome-level Rewards),即仅通过最终答案的正误来更新策略。这种稀疏奖励难以给“是否检索了足够信息”、“是否有效去除了噪音”等中间行为 (Intermediate behaviors) 提供准确的指导。
💡 核心贡献
为了打破传统串行单查询的限制,本文提出了一种基于强化学习的创新框架——MultiSearch。其核心贡献如下:
- 引入并行多查询检索 (Multi-Query Retrieval) 与显式合并 (Explicit Merging) 机制:在每个推理步骤并发生成多个视角的 query 以扩大信息覆盖面,随后通过显式的“整合”动作来过滤噪声,大幅提升送入下一步推理的上下文 SNR。
- 设计多过程奖励模型 (Multi-process Reward Design):除了最终答案准确性外,专门设计了针对多查询行为和信息整合行为的过程奖励,从而为智能体提供了针对性的中间步骤监督信号。
- 采用去耦多目标强化学习 (GDPO):摒弃了传统的标量求和奖励,采用组内奖励去耦归一化策略优化 (GDPO) 进行模型训练,避免了单一简单奖励(如查询次数)主导整个策略更新。在 7 个 QA 基准测试中均达到了 SOTA。
🔎 具体案例剖析 (Case Study)
以测试集中一个经典的复杂多跳推理问题为例,观察 MultiSearch 与 Baseline (Search-R1) 行为的区别:
❓ 问题:波特兰国际机场 (Portland International Airport) 和杰拉尔德·R·福特国际机场 (Gerald R. Ford International Airport) 是否都位于俄勒冈州 (Oregon)?(Ground Truth: No.)
❌ Search-R1 (Baseline):
<think> 需要确定这两个机场是不是都在 Oregon。
<search> [单查询]: Are Portland International Airport and Gerald R. Ford International Airport both located in Oregon?
<info> 召回的文档仅命中了 "Portland International Airport is the largest airport in Oregon..." 且未提及福特机场的真实位置。
<think> 根据提供的信息,我得出结论两个机场都在 Oregon。(模型被片面信息误导产生幻觉)
<Answer> Yes. (错误)
✅ MultiSearch (Ours):
<think> 首先,我们需要分别查出这两个机场的位置,然后再检查它们是否都在 Oregon。
<search> [并行多查询]: "where is Portland International Airport", "where is airport Gerald R. Ford International Airport", "are Portland... located in Oregon"
<info> 分别召回了描述 Portland 在 Oregon,以及 Ford 机场在密歇根州大急流城 (Michigan) 的确切文档。
<merge> [显式合并降噪]: From the retrieved documents, we can see that Portland International Airport is in Oregon and Gerald R. Ford International Airport is in Michigan. The two airports are not in the same state.
<Answer> No. (正确)
💡 分析:在这个案例中,单查询很难同时命中包含两个不同实体地址的网页;而 MultiSearch 通过多视角搜索完美获取了充分的拼图,并通过 <merge> 块将冗长的多篇原始文档提炼成了一句高价值的短摘要,彻底阻断了噪音对最终判决的干扰。
⚙️ 方法论与技术实现
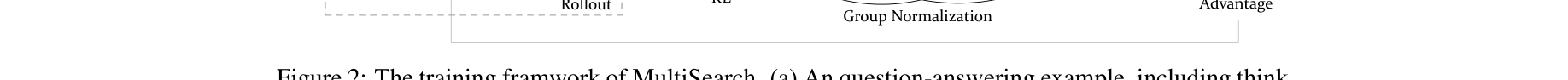
1. 基于 Multi-Query 的生成轨迹构造 (Rollout Generation)
在传统的 <think> -> <search> -> <info> 范式基础上,MultiSearch 为 Agent 赋予了三种查询扩展策略:重述 (Rephrasing)、概念扩展 (Concept expansion) 和 问题分解 (Question decomposition)。在每个检索步骤中,Agent 被指导同时生成 3 个不同的 queries 进行并行检索。随后,Agent 会阅读这些并行召回的冗长文档,并将其提纯整合到 <merge>...</merge> 标签内。
2. 多维度奖励建模 (Reward Modeling)
为了让 RL 能够有效驱动这种复杂流程,框架设计了三组独立的 Reward:
- 答案奖励 ($r_{ans}$): 计算最终预测答案与真实答案之间的词级 F1 score。$r_{ans} = \frac{2n_{int}}{n_{pred} + n_{truth}}$,比纯粹的 EM (Exact Match) 能提供更连续的梯度。
- 多查询奖励 ($r_{query}$): 如果当前 step Agent 能够生成大于 2 个 query,则奖励 0.1,以激励其探索更广阔的信息面。
- 合并奖励 ($r_{merge}$): 检查所有
<merge>块内的提取文本。如果 Ground Truth 答案出现在这些 merge 内容中,则奖励 0.1。这迫使 Agent 学会在降噪的同时绝不漏掉关键的答案依据。
注:过程奖励 ($r_{query}$, $r_{merge}$) 是附带条件的,只有当最终答案 $r_{ans} > 0$ 时才会给入,从而保证模型不会为了“刷中间分”而牺牲最终正确性。
3. 基于 GDPO 的强化学习 (Group reward-Decoupled Normalization Policy Optimization)
如果直接使用 GRPO 对奖励进行简单的相加 $\sum r_k$,容易出现多查询奖励过快收敛并支配损失函数的问题。MultiSearch 采用了 GDPO 算法,对每一种 Reward $k \in \{\text{ans, query, merge}\}$ 单独在其所在的 Group $G$ 内计算均值和方差,并进行独立标准化:
$$A_{i,j,t}^k = \frac{r_{i,j,t}^k - \text{mean}(r_t^k)}{\text{std}(r_t^k)}$$
然后将标准化后的各类 Advantage 加权求和,计算最终的优化目标。这种 Decoupled 设计保留了细粒度奖励的独特信号,使得策略更新更加鲁棒。
📊 实验设置与结论分析
- 实验基座:基于 Qwen2.5-3B 和 7B,分别测试了 Base 和 Instruct 版本。外部知识库使用 Wikipedia 2018 dump。联合使用单跳数据集 (NQ) 和多跳数据集 (HotpotQA) 进行 RL 训练。
- 性能全面领先 (Main Results):在测试涵盖的 7 个单/多跳 QA 数据集中,MultiSearch-Base (3B 达到 42.2%,7B 达到 44.5%) 全面超越现有的 Search-o1, ReSearch, AutoRefine 等开源 SOTA。在 Musique 等极端多跳推理集上,更是取得了接近翻倍的提升。
- 高信噪比带来更高效率:定量评估表明,经过 explicit merge 操作后,中间文本的 SNR 实现了阶梯式的上升。由于每一跳获取的信息更加准确和完备,MultiSearch 整体的 Search Steps(搜索轮次)反而明显下降,证明高质量的并行检索可以替代低效的“盲目试错式”反复检索。
- Base vs. Instruct:一个有趣的发现是,基座模型 (Base) 在 MultiSearch 框架下的最终表现优于指令微调模型 (Instruct)。作者推测,SFT 虽然增强了初始跟随能力,但也可能破坏了模型在新多步推理任务空间内的探索泛化能力。
🌟 关键技术亮点分析
作为资深 LLM 实践者,这篇论文带来的最核心启发在于对 Agent Context Pipeline 的精细化控制。以往做 RAG 或 Agent,很容易陷入 Context 污染的泥潭——随着检索步数增加,Prompt 中积压了大量无用、矛盾的召回文本,最终导致 LLM Attention 崩溃。MultiSearch 提出的 “Explore-then-Merge” 范式,本质上是让模型在每一轮充当了自己的 “信息降噪压缩器” (Information Compressor)。
此外,在多目标 RL 的工程实践上,本文证明了简单将各个 Process reward 相加送给 GRPO 会导致严重的失衡(即模型学会了作弊,疯狂多搜骗取 $r_{query}$,却不管正误)。利用 GDPO 的独立 Advantage 归一化 技术是本文的一个重要工程闪光点,为后续设计更复杂的 Agent 激励对齐机制提供了非常有价值的参考。结合多查询并发,这是一套能够实际在生产环境中显著提升 Search Agent 上限的工业级解法。