OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
OpenSeeker-v2:用高信息量与高难度轨迹突破搜索智能体能力边界
作者:Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang, Xinyu Zhu, Yuzhu Cai, Siheng Chen
机构:上海交通大学
📄 查看 ArXiv 原文
研究背景与痛点
Deep Search 正在成为前沿 LLM Agent 的核心能力,但工业界常把 Search Agent 的训练做成超重 pipeline:持续预训练(CPT)→ SFT → RL,严重依赖私有数据、算力和工具生态。对学术界而言,真正的门槛并不一定是“算法不够花”,而是拿不到足够难、足够长程、足够真实的搜索轨迹数据。
这篇论文直指一个关键问题:如果把训练重点从“更复杂的训练算法”切换到“更难更优质的数据”,能否只靠 SFT 就做出接近甚至超越工业系统的 Search Agent?
核心贡献
- 提出 OpenSeeker-v2,核心思想是 Data-Centric Search Agent Training:不用复杂 RL,只用极高质量的长轨迹 SFT 数据。
- 通过扩大知识图谱搜索空间、扩展工具集、过滤低步数样本,构造出 10.6k 条高难度 ReAct 轨迹,平均长度达到 64.67 步。
- 在 BrowseComp、BrowseComp-ZH、Humanity’s Last Exam、xbench 等基准上,OpenSeeker-v2-30B 超过多种同级别甚至更大规模系统。
具体案例剖析
输入任务:“对比近三年关于长上下文管理的论文,哪两种机制在显存降低与 PPL 保持之间权衡最好?并列出代表作。”
普通浅层 Agent 输出:只会搜索 1-2 次,读几篇综述或博客后直接下结论,通常会漏掉关键 ablation、不同论文指标口径不一致的问题。
OpenSeeker-v2 风格轨迹:先检索候选论文列表,再逐篇抽取机制名;随后对每种机制分别做二跳和三跳检索,追表格、追补充材料、追复现实验或 benchmark;最后汇总成跨论文比较答案。这个 case 的本质不是“会不会搜”,而是能不能在几十步里持续维持问题分解、证据追踪和局部修正。
方法论与技术实现
论文把重点全部放在数据合成和样本筛选上。若记原始轨迹集合为 \(\mathcal{D}_{raw}\),轨迹长度为 \(T(\tau)\),则最终训练集可写为:
$$\mathcal{D}_{v2} = \{(q,\tau) \in \mathcal{D}_{raw} \mid T(\tau) \ge T_{min}\}$$
核心三步是:
- 扩大图搜索空间:让问题天然需要 multi-hop 证据聚合。
- 扩展工具动作空间:让轨迹包含更丰富的检索、阅读、整合动作。
- 严筛短轨迹:直接剔除几步内就能搞定的“伪难题”。
从工程视角看,这相当于把“Agent 能力”向前折叠到数据中:不是让模型后期靠 RL 学习忍耐和长视野,而是在 SFT 时就让它反复模仿长时程搜索策略。
实验设置与结论分析
模型基座为 Qwen3-30B-A3B-Thinking-2507,256k 上下文,只做纯 SFT。结果上,BrowseComp 达到 46.0%,HLE 达到 34.6%,同时在 xbench 和中文 BrowseComp-ZH 上也取得强势表现。
最值得注意的是,它不仅胜过若干同级模型,还在部分基准上压过更大的工业系统。这说明对 Search Agent 来说,高难度长轨迹数据的价值可能大于额外的后训练复杂度。
关键技术亮点分析
- “数据质量 > 训练花活”:对 Search Agent 尤其成立。
- 长轨迹是能力塑形器:模型学到的不是单步检索,而是 sustained reasoning。
- 对开源社区极友好:这条路线比全套 CPT+RL 更容易复现和扩展。
ELVIS: Ensemble-Calibrated Latent Imagination for Long-Horizon Visual MPC
ELVIS:面向长视野视觉模型预测控制的集成校准潜在想象
作者:Yurui Du, Pinhao Song, Yutong Hu, Renaud Detry
机构:KU Leuven, Flanders Make
📄 查看 ArXiv 原文
研究背景与痛点
视觉控制里的 model-based RL 很强,但一旦在线规划视野变长,误差会快速累积;再叠加遮挡、局部可观测、未来多模态分支,传统 latent MPC 很容易翻车。短视野能稳,但不够聪明;长视野更强,却常常建立在不可靠的 imagined rollout 上。
核心贡献
- 提出 ELVIS,用 ensemble critic + UCB 做不确定性感知,动态控制长视野规划的有效深度。
- 使用 GMM-MPPI 代替单高斯 MPPI,避免多模态未来下的 mode averaging。
- 把同一套 uncertainty-aware return 同时用于 actor-critic 学习和 MPC 规划,实现 train-test 对齐。
具体案例剖析
Case: 机器人喷砂场景。真实相机会因为粉尘产生持续遮挡,控制器需要在看不清的情况下仍维持均匀喷涂。
基线输出: TD-MPC2 依赖 frame stacking,遮挡一来就丢状态;DreamerV3 有记忆,但缺少强在线规划,纠偏不足。
ELVIS 输出: 一边用 RSSM 保持记忆,一边通过 ensemble critic 判断未来 imagined trajectory 是否可靠;一旦 UCB 显示不确定性暴涨,就缩短 look-ahead,转向更保守的 bootstrap 估计。结果在真实部署里显著降低表面粗糙度。
方法论与技术实现
设环境检查点集合为 \(\mathcal{C}=\{c_1,\dots,c_M\}\),无目标探索轨迹为 \(\tau_{EXP}\),则 ECC 定义为:
$$\mathrm{ECC}(\tau_{EXP})=\frac{1}{M}\sum_{i=1}^M \mathbb{1}[c_i\in\tau_{EXP}]$$
训练时把探索 rollout 的奖励直接设为 \(R_{EXP}=ECC(\tau_{EXP})\),再与任务成功奖励交替输入 GRPO。推理时分两段:
- 先执行 \(N\) 步无目标探索;
- 把探索轨迹总结成环境知识 \(\mathcal{K}\),再执行正式任务策略 \(\pi_{ACT}(\cdot|H_t,g,\mathcal{K})\)。
实验设置与结论分析
在 ALFWorld、ScienceWorld、TextCraft 上,作者发现一个很扎心的现象:只做 task-only RL 后,模型的探索能力反而下降。交替式训练则同时提高 ECC 和下游任务成功率,尤其在环境扰动、规则变动、物体位置变化等分布外条件下更稳。
关键技术亮点分析
- 把探索从副作用升级为显式训练目标。
- 可验证奖励很关键:避免 LLM-as-a-judge 带来的幻觉和 reward hacking。
- 对真实网页/GUI agent 很有启发:先安全探路,再执行任务,能显著降低失败率。
Harnessing LLM Agents with Skill Programs
HASP:用可执行技能程序驱动 LLM Agent
作者:Hongjun Liu, Yifei Ming, Shafiq Joty, Chen Zhao
机构:New York University, Salesforce AI Research
📄 查看 ArXiv 原文
研究背景与痛点
Agent 社区一直在讲“从过去经验里提炼 skill”。但很多 skill 最终只是几段自然语言建议,放进 prompt 里当软约束。问题是:模型既可能忘,也可能在关键时刻不执行。对于 web search、代码、数学这类多步任务,真正缺的不是“知道原则”,而是能不能在具体失败状态上被强制纠偏。
核心贡献
- 提出 HASP,把 skill 升级为可执行 Program Functions(PFs),直接在 agent loop 中拦截和修正动作。
- PF 支持两类干预:
MODIFY_ACTION 与 INJECT_CONTEXT。
- PF 不只在 inference-time 生效,还能生成结构化监督信号,用于 post-training 和自我演化技能库。
具体案例剖析
输入问题: 一个多跳 web-search 推理题,需要先找到中间实体,再追最终答案。
普通 ReAct 输出: 上来就把所有约束糊成一个超长 query,搜索失败后继续无效搜索,最后在证据不足时直接给幻觉答案。
HASP 输出: 当检测到 retrieval failure 时,PF 自动把长 query 改写成更稳健的短 query;当识别出是多跳问题时,PF 注入“先找中间实体”的结构化提示;当 agent 想过早 FINAL 时,PF 强制改成继续阅读证据文档。最终答案不再靠运气,而是靠显式干预链路拿到。
方法论与技术实现
每个 PF 至少包含两个接口:
should_activate(state, action)intervene(state, action)
PF 干预后还会产出细粒度训练信号,例如 timing、modality、correctness、outcome。可把单步评分写成:
$$A_t=\lambda_t t_t+\lambda_m m_t+\lambda_q q_t+\lambda_o o_t$$
整条轨迹得分再用于 SFT、拒绝采样或 on-policy distillation,把外部 skill 逐步内化到模型参数里。若要让技能库持续演化,还必须通过执行校验和 teacher 审核,避免坏 skill 污染系统。
实验设置与结论分析
在 web-search、数学、代码任务上,单靠 inference-time PF 就能显著拉开和 prompt-only 方法的差距;若再结合 post-training,效果进一步提升。一个很关键的结论是:如果取消执行验证和 teacher review,skill evolution 很快会把系统带崩。
关键技术亮点分析
- 从 Alignment by Prompt 走向 Alignment by Code。
- 程序化技能更可审计、更可复用。
- 对长期运行 Agent 极有现实意义:skill library 如果没有准入机制,本质上就是往系统里持续加毒。
LLM-Guided Communication for Cooperative Multi-Agent Reinforcement Learning
LMAC:由 LLM 指导通信协议的协作多智能体强化学习
作者:Sangjun Bae, Yisak Park, Sanghyeon Lee, Seungyul Han
机构:UNIST 等
📄 查看 ArXiv 原文
研究背景与痛点
MARL 里通信是缓解部分可观测性的关键,但旧方法大多只在“消息怎么传”上做文章:广播会冗余,agent-wise attention 也未必抓到真正影响协作的全局状态信息。真正难的是:如何让多个智能体通过有限通信,尽量一致而准确地恢复潜在环境状态。
核心贡献
- 提出 LMAC:用 LLM 离线生成通信协议代码,而不是在线调用 LLM 参与每一步决策。
- 通过状态恢复质量和智能体间知识不平衡两个反馈信号,迭代 refinement 通信协议。
- 在 RL 训练阶段再叠加元认知 latent module,让智能体不仅重建状态,还能估计自己“是否真的知道”。
具体案例剖析
Case: StarCraft 场景中,一个 Overseer 看得到敌人,多个 Baneling 自身视野不够,需要协同包抄。
初始协议输出: Overseer 只发敌人的相对坐标偏移,Baneling 仍无法恢复敌人的绝对位置。
迭代后输出: 协议逐步加入移动历史、坐标锚点、可视队友 ID 等关键信息,让不同 Baneling 对敌方位置形成更一致的重建,最终完成同步攻击。这个例子很好地说明:LLM 在这里不是做决策,而是在“写通信机制”。
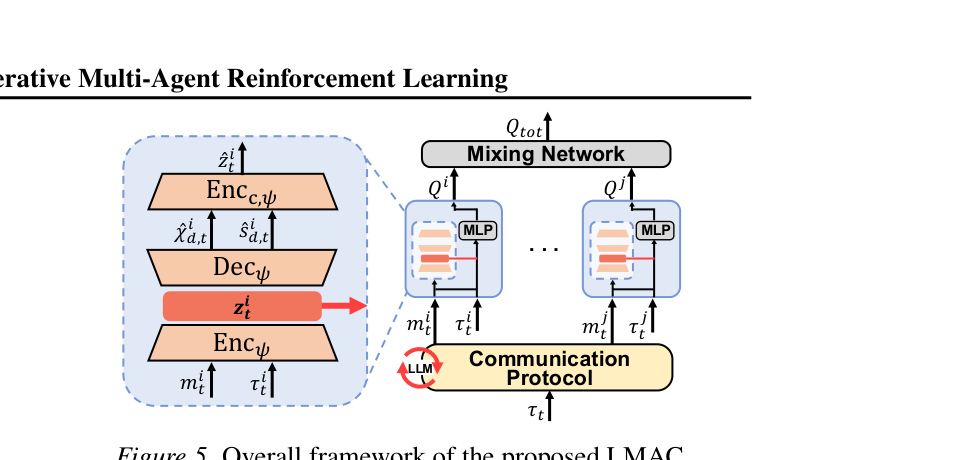 图注:LMAC 上半部分是离线 LLM 代码生成/修订闭环,下半部分是在线 CTDE 训练,其中 latent module 负责状态重建与元认知可靠性预测。
图注:LMAC 上半部分是离线 LLM 代码生成/修订闭环,下半部分是在线 CTDE 训练,其中 latent module 负责状态重建与元认知可靠性预测。
方法论与技术实现
作者先训练辅助状态解码器,再定义状态感知指标(SAI):
$$\chi_{l,d,t}^{i,(k)} = \mathbb{I}\left[\|\hat{s}_{l,d,t}^{i}-s_{d,t}\|_2^2 \le \alpha\right]$$
用它从两个方向给 LLM 反馈:
- Recovery Enhancement:哪些关键状态还恢复不出来;
- Imbalance Mitigation:不同 agent 对状态的掌握是否严重不均衡。
在线训练时,再让 latent 表征同时承担状态重建与元认知判断,联合优化 TD loss、reconstruction loss 和 consistency loss。
实验设置与结论分析
在 SMAC-Comm、LBF、GRF、SMACv2 上,LMAC 都显著优于多类通信基线。最有意思的是:由于协议是离线生成的,线上几乎没有额外 LLM 成本,但效果却非常接近甚至逼近一些拥有更强状态信息的上限系统。
关键技术亮点分析
- 聪明地绕开 in-the-loop LLM 成本。
- 把 RL 数值反馈翻译成 LLM 能利用的协议修订信号。
- 元认知模块很有启发:不仅传信息,还要传“我对这条信息有多确定”。