Harnessing LLM Agents with Skill Programs
用技能程序(Skill Programs)驾驭 LLM 智能体
作者:Hongjun Liu, Yifei Ming, Shafiq Joty, Chen Zhao
机构:New York University (NYU), Salesforce AI Research
🔍 研究背景与核心痛点
近年来,具备多步推理和工具调用能力的 LLM Agents 在解决复杂长视距(long-horizon)任务上取得了显著进展。然而,在实际运行(Rollout)中,随着环境变化和反馈的累积,很多智能体容易陷入重复的失败模式:例如未经充分信息检索就过早终止(Premature Finalization)、对中间结果过度自信、或者在无用的搜索词上陷入死循环。
为了解决这些问题,目前的常见做法是总结历史失败经验,将其作为“文本技能(Textual Skills)”注入到系统提示词(Prompt)中,例如告诉模型“请在得出结论前验证证据”。但这种方法的痛点极其明显:
- 文本建议过于柔性(Advisory Guidance): 文本只能告诉模型“原则上该怎么做”,却无法精确控制“何时触发”以及“如何强制改变接下来的行为”。
- 弱控制力(Weak Policy Control): 在复杂状态下,模型很容易忽略 Prompt 中的长篇大论,继续重复之前的错误行为。
简而言之,目前业界的“经验复用”多停留在自然语言层面,存在“认知(知道该怎么做)与执行(能否切实改变 Action Space)脱节”的鸿沟。
💡 核心贡献
本文提出了一种全新的框架 HASP (Harnessing LLM Agents with Skill Programs),将智能体的历史经验从“被动文本建议”升级为“可执行的程序函数 (Program Functions, PFs)”。其核心突破在于:
- 将技能转化为“状态-动作”的可执行干预函数: 技能不再是一段提示词,而是一段代码(PF)。它能根据当前状态决定是否触发,并在模型输出错误 Action 前直接拦截、修改 Action,或向上下文中强行注入纠正信息。
- 高度模块化的 Agent Harness: 提出了一个“智能体安全带/外挂控制层 (Harness)”机制。该机制可以即插即用,纯 Inference-time 就能大幅提升能力;也可以在 Post-training 阶段提供结构化的监督信号;更能支持安全的“自我进化 (Self-improving)”。
- 可控的技能库演进闭环: 摒弃了毫无限制的自我反思,HASP 要求模型针对失败案例编写出包含执行逻辑和接口的 PF 代码,且必须通过严格的代码沙盒编译测试(Executable Validation)及教师模型评审(Teacher Review)后,才能进入技能库,根除了技能污染。
🔎 具体案例剖析 (Case Study)
为了直观感受 PF 的强制干预能力,论文展示了在 MuSiQue(多跳实体解析数据集)上的一个真实轨迹对比:
问题: 找出 2005 年 John 死后,某位去世的著名 Walton 家族成员的丈夫是谁?
- Baseline Agent (失败轨迹):
[Step 0]搜出了一堆关于 Walton 家族的冗长信息。没有阅读文档就盲猜答案。[Step 1]去搜 "Alice Walton death date",发现她还活着。[Step 2]再次搜一模一样的 "Alice Walton death date"(陷入死循环)。[Step 3]强行输出错误答案FINAL("Bruce Walton")(模型幻觉)。
- HASP Agent (成功轨迹):
[Step 0]模型本打算直接搜索全句,此时 PFdecompose_complex_question被触发,它执行了INJECT_CONTEXT,在观测结果后强制追加了一段系统级警告:“这是个多跳问题,请先拆解寻找中间实体”。[Step 1]模型受此引导,重新规划,成功搜出中间实体 Helen Walton 并得知她死于 2007 年。[Step 2]模型试图过早得出结论:PROPOSED ACTION: FINAL("Sam Walton")。此时 PFinsufficient_exploration检测到action_type=FINAL但read_count=0,立即被触发!执行MODIFY_ACTION,将模型的动作强制拦截并篡改为READ(doc_0)。[Step 3]模型阅读文档后,最终确信并合规输出最终答案,成功完成推理链。
在这个案例中,PF 就像一个严格的监工,直接拦截并覆写了致命的错误决策(过早 Final 和未充分拆解),这是传统的 Prompt Engineering 根本无法做到的。

⚙️ 方法论与技术实现
1. Program Functions (PFs) 结构设计
在 HASP 中,每个技能被定义为一个确定性的 Python 模块,包含两个核心接口:
should_activate(step_context, action_type, arg) $\rightarrow$ bool:一个判定逻辑,决定当前状态下该技能是否应当触发(例如判断当前是否是SEARCH动作且搜索词过短)。intervene(step_context, action_type, arg, teacher=None) $\rightarrow$ Intervention:具体的干预操作,返回的操作类型可以是修改动作(MODIFY_ACTION),或者是注入上下文(INJECT_CONTEXT)。
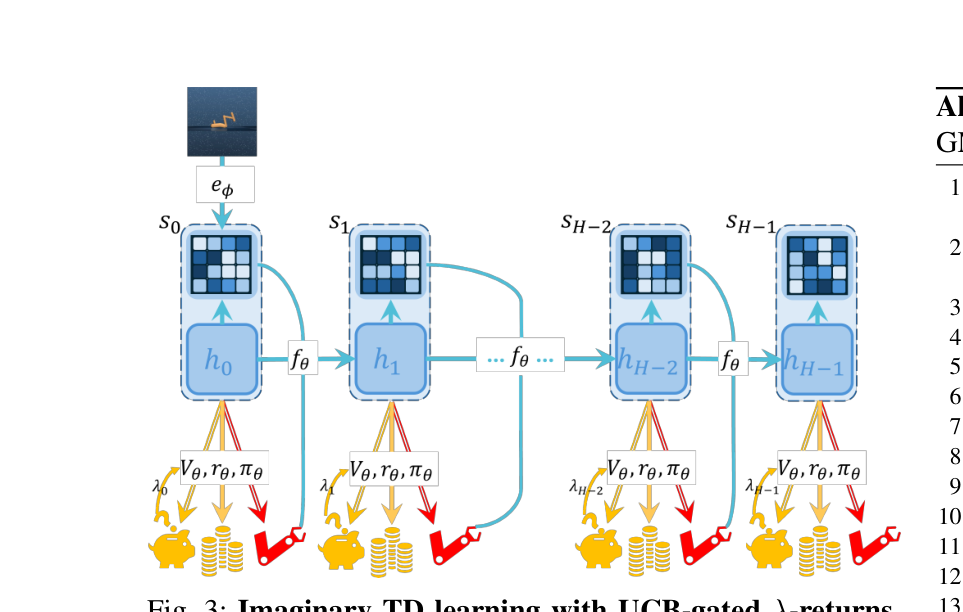
2. 推理阶段的 Agent Harness
在时刻 $t$,基础策略(Base Policy)提议一个动作 $a_t^{\text{orig}} \sim \pi_\theta(\cdot \mid s_t)$。接着,外置的 Harness 控制层检索相关的 PF。如果触发条件满足,PF 会计算并输出纠正后的最终执行动作 $\tilde{a}_t$ 以及需要注入的纠正上下文 $c_t$。模型最终执行并记录的是被 PF “修正”后的轨迹记录:$e_t = (s_t, a_t^{\text{orig}}, \tilde{a}_t, c_t, \kappa_t, \Delta_t)$。
3. Post-Training: 通过 PF 信号进行策略内化
仅仅在 Inference 时纠正还不够,我们需要让模型内化这些能力。HASP 为每次干预设计了四维监督信号聚合向量 $\mathbf{z}_t = (t_t, m_t, q_t, o_t)$,分别代表:干预时机(Timing)、干预模式(Mode)、局部正确性(Correctness)和最终结果(Outcome)。聚合得分记为:
$$ A_t = \lambda_t t_t + \lambda_m m_t + \lambda_q q_t + \lambda_o o_t $$
作者验证了三种后训练方法,其中 PF-guided Rejection Sampling (RS) 效果最稳定:对采样的轨迹使用全局成功率与中间 PF 打分的组合得分进行过滤,留下最符合“正确 PF 逻辑”的轨迹去 Fine-tune 学生模型($\mathcal{L}_{\text{SFT}} = - \sum_t w_t \log \pi_\theta(\tilde{a}_t \mid s_t)$)。这使得模型在不依赖外部探索的条件下迅速学到了高效行为策略。
4. 技能库自我进化 (Self-Improving Evolution)
HASP 提供了一个严格的闭环用于技能挖掘:
- 发现与提议: LLM 对当前 Checkpoint 遗留的失败轨迹进行分析(聚类),如果发现共性错误,则生成一个新的 PF 候选代码片段。
- Executable Validation (执行门控): 对该 PF 运行抽象语法树解析、接口匹配,并在 9 种 Mock 的上下文状态下进行沙盒空跑,一旦崩溃直接丢弃。
- Teacher Review (评审门控): 由 Teacher Model 根据 Concept, Trigger, Intervention, Executability, Validation 五个维度进行打分($Q_{\text{skill}} \ge 0.60$ 才准入)。
📊 实验设置与结论分析
论文在 Web-Search Reasoning (HotpotQA, 2Wiki, MuSiQue), Math Reasoning (AIME24, AMC23, GameOf24) 和 Coding (HumanEval, MBPP, BigCodeBench) 上使用 Qwen2.5-7B-Instruct 进行了全面评测。
- 纯 Inference-time 的降维打击: 在 Web-search 任务上,纯基础模型(Multi-loop RA-Agent)准确率为 31.2%。仅仅将 Prompt-Only Skills 替换为 HASP PF-only intervention,准确率直接飙升至 51.0%;如果加入辅助 Teacher 选择 PF,可达 56.2%。这证明了主动式拦截远胜于被动式 Prompting。
- Post-training 策略内化极具性价比: 在固定 PF 库下,仅仅通过 PF-guided Rejection Sampling,模型无需庞大的 RL 开销即可将 Web-search 能力进一步提升至 59.3%,On-policy Distillation 甚至达到 62.5%(大幅超越 Search-R1 等传统 RL 基线)。
- 安全进化: 在引入 Self-improving 闭环后(HASP-Evolve + RS),系统在 Web-search 达到 60.3%,在 Math Reasoning 达到 45.4%(比纯 SFT 提升 16.3 个点),在 Code 生成上达到 69.9% Pass@1。
Ablation 洞察: 作者发现如果关闭“Executable Validation”和“Teacher Review”两个门控,让技能库无脑堆积(Evolution, no filtering),效果会断崖式暴跌(从 60.3% 降到 36.3%)。这证实了“内存污染(Memory Pollution)”是自我进化系统最致命的弱点,严格的编译通过和多维审核是构建高质量技能库的前提。
🌟 关键技术亮点分析
- 将“慢思考 (System 2)”下沉为代码守卫 (Code Guardrails): 过往的 Agent 研究过度依赖 LLM 自身的隐式反思能力(如 Reflexion)。HASP 的哲学是:那些确定的规则(比如“还没检索过文档就不许抛出答案”、“搜索词不能超过20个词”)没必要次次靠 LLM 自发思考,直接用 Python 规则和正则表达式作为外置拦截器,能极大收敛探索空间,消除低级幻觉。
- 绕过了纯 RL 探索的稀疏奖励陷阱: 在复杂工具调用和多跳推理中,RL 常常因为找不到正确路径而崩溃。HASP 把高难度的 Exploration 转化为了“提议(Proposal) + 拦截纠正(Intervention)”范式,PF 生成的高质量 Correction 直接化为了 SFT/RS 的密集正向标签,这种 Elicitation(能力激发)比盲目的 PPO 探索高效得多。
- Agent Engineering 的模块化典范: 该研究的工程实现极其优雅。同样的机制既能在 Inference 时作为拦截网兜底(提升部署期业务可用性),又能在闲时作为打分器构建对齐数据集供下一次 SFT 迭代。对于正苦恼于 Agent 落地产出不稳定、易死循环的从业团队来说,HASP 提供了一条清晰的落地参考路线。