MOSS: Self-Evolution through Source-Level Rewriting in Autonomous Agent Systems
MOSS:通过源码级重写实现自主智能体系统的自我进化
作者:Qianshu Cai, Yonggang Zhang, Xianzhang Jia, Wei Xue, Jun Song, Xinmei Tian, Yike Guo
机构:中国科学技术大学(USTC)、香港科技大学(HKUST)、香港浸会大学
📄 查看 ArXiv 原文
研究背景与痛点
这篇论文直击一个很现实的问题:现在的 LLM Agent 系统大多只能改 prompt、改 memory、改 workflow,但改不到真正决定行为边界的 harness / runtime code。结果就是,线上系统会一遍遍重复相同失败模式,直到人工修代码重新部署。
作者指出,现有 self-evolving agent 大多停留在“文本可变工件(text-mutable artifacts)”层面,无法触达路由逻辑、hook 顺序、状态机不变量、会话调度等源码级控制平面。这意味着很多结构性 bug 根本不是靠 prompt patch 能解决的。
核心贡献
- 提出 Source-Level Adaptation:让 Agent 不只改文本,还能改自己的系统源码。
- 给出生产级闭环系统 MOSS:从失败捕获、定位、规划、代码修改、试运行到热更新上线全部打通。
- 强调工程安全边界:host-daemon、trial workers、plan/code review gate、health check、rollback。
具体案例剖析
论文展示了一个很有说服力的真实案例:OpenClaw 类系统在并发工具调用后出现输出揉杂,导致 SLA 审计 / 工单追踪类任务频繁漏项。MOSS 从失败 trace 中定位到 mediator 分支逻辑缺陷,随后由外部 coding agent 提交源码补丁,在 hook 链和结果整理逻辑中补上缺失分支,并自动补测。
这次修复不是“优化提示词”,而是直接修改了核心代码路径。最终 4 个代表任务的平均分从 0.2526 提升到 0.6100,说明源码级自进化对复杂 agent 系统有实打实的杠杆效应。
 图注:MOSS 的宿主侧拓扑。网关容器负责对话与进化入口,host-daemon 负责编排,coding agent 负责代码变更,trial workers 负责隔离验证。
图注:MOSS 的宿主侧拓扑。网关容器负责对话与进化入口,host-daemon 负责编排,coding agent 负责代码变更,trial workers 负责隔离验证。
方法论与技术实现
MOSS 把一次“自我进化”拆成严格门控的 7 阶段流水线:Locate → Plan → Plan-Review → Implement → Code-Review → Task-Evaluate → Verdict。这比把所有上下文一次性塞给模型更稳,因为每个阶段都可以专门做质量控制。
它最关键的工程设计是 host-daemon + ephemeral trial workers。也就是说,代码修改先在隔离 worker 里跑真实验证,通过后才做就地热更新(in-place container swap),同时保留会话状态和 memory 卷,异常时还能 rollback。
对从业者来说,这篇论文的真正价值不是“Agent 会修自己”这句口号,而是给出了一个可信的生产安全框架:先隔离、再验证、后切换,而不是让模型直接在线上自我改写。
实验设置与结论分析
实验底座是 DeepSeek V3.2 驱动的 OpenClaw 系统,评测器是独立的 claweval。结果说明:一旦问题根源在 harness / orchestration,而不是单轮 reasoning,prompt-level tricks 很难补救。
这篇论文等于把“agent optimization”的视角从 prompt / memory 推到了 runtime / infrastructure。对做多 Agent 编排、工具调用和长生命周期系统的人来说,非常值得细读。
关键技术亮点分析
- 把 agent 自我进化从“文本层”推进到“控制平面层”。
- 把 LLM 代码修改能力和真正的 DevOps 安全机制结合起来。
- 对工业界尤其重要:它证明最有价值的改进点常常不在 prompt,而在 harness。
Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Spreadsheet-RL:用强化学习提升大模型在真实电子表格任务上的 Agent 能力
作者:Banghao Chi, Yining Xie, Mingyuan Wu 等
机构:UIUC,Meta
📄 查看 ArXiv 原文
研究背景与痛点
Spreadsheet 是企业真实工作流里最常见、也最难自动化的环境之一。问题不只是“看表格”,而是要在多 sheet、多公式、多格式依赖的状态空间里做长序列编辑。这和网页 agent、terminal agent 很像:都属于高耦合、易级联出错的交互环境。
作者指出,现有方案太依赖 GPT-4o 级别的通用 prompting,而 RL 微调又面临三大难点:缺少高质量 initial-final 数据、缺少 step-level SFT 轨迹、真实 Excel 执行和验证极慢,不适合直接做大规模 rollout。
核心贡献
- 构建 Spreadsheet Data Agent,从在线论坛自动合成初始表格—目标表格对。
- 提出 Spreadsheet Gym 和 native spreadsheet harness,把表格操作抽象成更稳定的 tool space。
- 设计异步 reward / recalculation 基础设施,使 GRPO 能真正跑在真实 Excel 风格环境上。
- 把 Qwen3-4B 在 SpreadsheetBench 上的 Pass@1 从 12.0% 拉到 23.4%。
具体案例剖析
论文给出的典型轨迹是“Inspect-Modify-Verify”三段式:先检查 Sheet1!B1 和 Sheet2!B1 是否匹配,再读取 Sheet2!D1,最后把值写回 Sheet1!D1,并保存后验证。
强化学习前,模型经常直接猜、或者一错再错;强化学习后,模型更倾向于先 inspect 再 modify,再通过 recalculation / readback 做自校验。这个改变很关键——它说明 RL 学到的不是某个固定脚本,而是一种更像熟练 Excel 用户的交互策略。
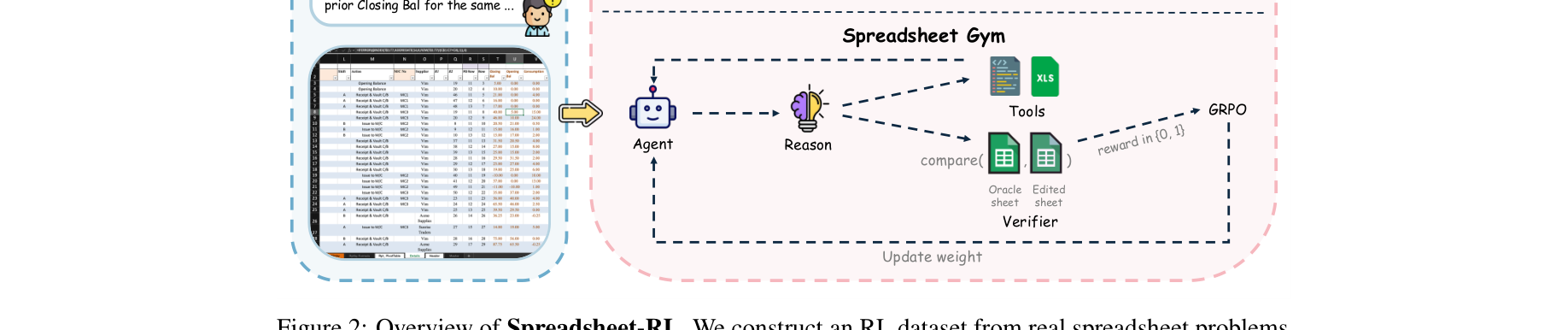 图注:Spreadsheet-RL 全链路:数据合成、Spreadsheet Gym 交互、Oracle 对比打分,以及基于 GRPO 的强化学习更新。
图注:Spreadsheet-RL 全链路:数据合成、Spreadsheet Gym 交互、Oracle 对比打分,以及基于 GRPO 的强化学习更新。
方法论与技术实现
这套系统最聪明的地方,在于把开放式代码空间压缩成了一套 spreadsheet-native 工具集合,如 inspect_range、find_cells、fill_formula、recalculate_and_read。这样一来,搜索空间变窄了,但仍保留了真实环境语义。
最终 reward 是 outcome-based:
$$
\mathcal{R}(o)=
\begin{cases}
0, & \text{if no valid output}\\
\mathrm{allcellsmatch}(D_{pred}, D_O), & \text{otherwise}
\end{cases}
$$
也就是只看最终表格状态是否和 Oracle 一致。
优化算法采用 GRPO,其直观理解是:对同题多 rollout 做组内比较,鼓励相对更优的行为轨迹。论文最有借鉴意义的地方不是公式本身,而是 异步执行架构:Excel 重算、文件系统隔离、reward verifier 全都独立出来,避免 GPU 等着桌面软件慢吞吞地执行。
实验设置与结论分析
主结果非常亮眼:Base model 只有 12.0%,加上 native harness 到 15.6%,加 full tools 到 19.3%,再做 Spreadsheet-RL 后到 23.4%。也就是说,环境抽象 + RL 微调是叠加收益,而不是二选一。
更重要的是 OOD 泛化:在 Domain-Spreadsheet 这类更贴近金融、供应链等场景的数据上,性能也从 8.4% 提升到 17.2%。这说明模型学到的是通用表格操作策略,而不只是背题。
关键技术亮点分析
- 是典型的“环境设计决定 RL 上限”的论文。
- 展示了 outcome-only RL 在复杂软件环境里仍然可行,前提是 action space 设计得足够好。
- 对所有做 GUI / Office / enterprise workflow agent 的团队都很有参考价值。
SEARCH-E1: Self-Distillation Drives Self-Evolution in Search-Augmented Reasoning
Search-E1:自我蒸馏驱动搜索增强推理的自我进化
作者:Zihan Liang, Yufei Ma, Ben Chen, Zhipeng Qian 等
机构:匿名提交版本,未在首页明确给出
📄 查看 ArXiv 原文
研究背景与痛点
Search-augmented reasoning agent 现在常用 outcome-level RL 去训:答案对就奖励,错就不给。但这种方法在多跳检索里有个经典问题:credit assignment 太粗。一条轨迹前半段搜索策略很烂,后半段侥幸答对,也会整体被奖励;反过来也一样。
为了解这个问题,许多工作引入外部 teacher、过程奖励模型、MCTS 或大量人工 shaping,训练链路很复杂。Search-E1 的关键问题是:能不能只靠模型自己生成的轨迹,做出更细粒度的过程监督?
核心贡献
- 提出 Search-E1:把 vanilla GRPO 和 offline self-distillation 交替进行。
- 核心机制是 OFSD(Offline Self-Distillation):用同一题里的优轨迹当 privileged context,去蒸馏差轨迹。
- 在 7 个 QA 基准上把 Qwen2.5-3B 推到平均 0.440 EM,超过不少更复杂的方法。
具体案例剖析
假设问题是“《Inception》的导演是谁?他出生于哪一年?” 模型会采样多条轨迹。优轨迹可能两次搜索就完成:先查导演,再查出生年份;差轨迹可能先查电影剧情、演员名单,绕很多圈后仍失败。
Search-E1 会把优轨迹当 reference,把差轨迹当 student input。然后让 teacher 在“看过 reference”的条件下,对 student 这条差轨迹逐 token 给出分布约束。这样模型学到的不是“最终答对”,而是“哪一步搜索已经走偏了”。
方法论与技术实现
Search-E1 分两步:第一步先用原生 GRPO 做探索;第二步在线下做 OFSD,把同题 rollout 中最优轨迹提炼成 teacher 视角。关键损失可以写成截断版 token-level forward KL:
$$
\mathcal{L}_{\mathrm{OFSD}} = \frac{1}{|\mathcal{R}_\tau|}\sum_{p\in\mathcal{R}_\tau}\sum_v \min\left(P_p^{tch}(v)\log\frac{P_p^{tch}(v)}{P_p^{stu}(v)}, \tau_{clip}\right)
$$
直观理解:teacher 不是外部更大模型,而是“看过好轨迹的同一个模型”。这非常优雅,因为它把自进化建立在 同题对比信号 上,而不是额外买一个更强的 judge / teacher。
实验设置与结论分析
论文基于 Qwen2.5-3B-Instruct,在 NQ + HotpotQA 上训练,用维基检索器支撑外部搜索。结果显示,相比 outcome-only 基线和一些 process-supervision 方法,Search-E1 在多跳任务上尤其强,像 Bamboogle、2Wiki 这类任务提升更明显。
这说明:当 agent 任务本质上是多步决策时,单纯给最终 reward 远远不够,关键是让模型理解“哪一步策略更像 expert path”。
关键技术亮点分析
- 用“更优轨迹”代替“更强 teacher”,非常省而且漂亮。
- offline 设计让在线 RL 主循环保持简洁,不增加 rollout 负担。
- 对 search agent、browser agent、tool-use RL 都有明显可迁移价值。
Agentic CLEAR: Automating Multi-Level Evaluation of LLM Agents
Agentic CLEAR:LLM Agent 的多层级自动评估与诊断框架
作者:Asaf Yehudai, Lilach Eden, Michal Shmueli-Scheuer
机构:IBM Research
📄 查看 ArXiv 原文
研究背景与痛点
Agent 能力上去了,评估却还停留在很粗糙的阶段。很多 observability 平台能记录 trace,却很难自动回答几个真正关键的问题:系统到底常犯什么错?是 planner 节点错、executor 节点错,还是整个 workflow 设计错?这些问题不靠大量人工排日志很难搞清楚。
另外,静态 error taxonomy 往往过于僵硬。真实 agent 系统,尤其是高度定制的企业系统,错误类型会不断演化。预先写死 rubric 并不现实。
核心贡献
- 提出 多粒度评估框架:system-level、node-level、trace-level 三层联动。
- 不依赖静态 taxonomy,可自动归纳高频错误模式与根因。
- 兼容 OpenTelemetry / LangFuse 等现有可观测性栈,工程落地性很强。
具体案例剖析
论文里很有代表性的点,是它能在不同 benchmark 上自动长出不同 insight:比如在 GAIA 里指出“多源交叉验证不足”,在 SWE-bench 里指出“猴子补丁式修复、回归覆盖不足”,在 AppWorld 里指出“污染购物车、误丢附件”等领域特有错误。
更重要的是 node-level 诊断。比如一个多 Agent 系统任务失败,不再只是给出“任务失败”,而是继续往下指:TaskDecompositionAgent 在分解任务时存在能力幻觉,APICodePlannerAgent 缺少 pagination 逻辑。这就非常接近工程团队真正想要的 debugging 入口。
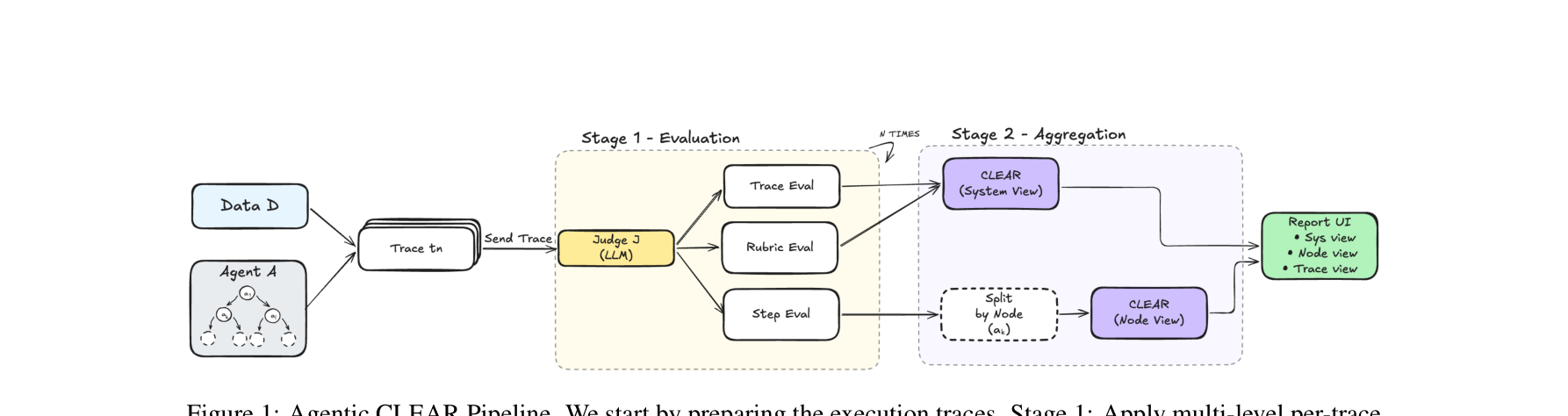 图注:Agentic CLEAR 两阶段 pipeline:先对 step / trace / rubric 做 LLM 评估,再通过 CLEAR 聚合成 node-level 与 system-level insight。
图注:Agentic CLEAR 两阶段 pipeline:先对 step / trace / rubric 做 LLM 评估,再通过 CLEAR 聚合成 node-level 与 system-level insight。
方法论与技术实现
它的整体 pipeline 可以理解成两层:第一层是 per-trace judge,第二层是 cross-trace aggregation。先让 judge 对步骤、整条轨迹、任务专属 rubric 分别做评价;再把大量自然语言 feedback 聚类、摘要,生成系统性 insight。
如果简单写成形式化视角,就是:给定数据集 $\mathcal{D}=\{x_n\}_{n=1}^N$,系统执行得到轨迹集合 $\mathcal{T}=\{t_n\}_{n=1}^N$,再通过 judge $\mathcal{J}$ 和聚合器把 instance-level feedback 变成 system-level diagnosis。
它真正厉害的地方在于:不是只做打分,而是把评估结果整理成工程上可执行的 bug list。这个能力对 agent infra 团队很值钱,因为你不缺 trace,你缺的是“从 trace 到结论”的自动化桥梁。
实验设置与结论分析
论文在 SWE-Bench Verified Mini、GAIA、AppWorld、τ²-Bench 等多套 benchmark 上测试,并比较了不同 judge 模型。结果显示,trace-level 评分对最终成功率有不错的预测能力;而更强的 judge(如 GPT-5)能给出显著更深、也更 actionable 的错误描述。
对从业者来说,这篇论文最大的意义在于:它把“可观测性”往前推进了一步——从 logging 走到了 diagnosis。
关键技术亮点分析
- 真正把 LLM-as-a-judge 用在多层级 agent diagnosis 上,而不只是打一个总分。
- 对复杂多节点系统尤其有价值,因为它能拆 root cause。
- 很像未来 agent IDE / agent APM 的雏形。
TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
TerminalWorld:在真实终端任务上评测 Agent 的数据引擎与基准
作者:Zhaoyang Chu, Jiarui Hu, Xingyu Jiang, Pengyu Zou, Han Li, Chao Peng, Peter O’Hearn, Earl T. Barr, Mark Harman, Federica Sarro, He Ye
机构:UCL、南京大学、腾讯
📄 查看 ArXiv 原文
研究背景与痛点
Terminal agent 现在很热,但 benchmark 很多都不够真实:要么是专家手工编的题,偏 puzzle;要么是静态环境,和真实开发者在 shell 里做事的方式差距很大。论文的核心主张很简单也很强:不要发明终端题,应该从真实人类终端录像里反推 benchmark。
这点很重要,因为真实终端任务有大量长尾分布:依赖安装、环境清理、文件转换、网络抓包、容器构建、系统工具拼接等等。这些题靠人工设计很难保持真实感和覆盖度。
核心贡献
- 提出 TERMINALWORLD data engine:把真实 Asciinema 录屏转成可执行 benchmark。
- 从 80,870 个终端录像中提炼出大规模任务集,最终形成 1,530 个可验证任务以及 200 个 VERIFIED 核心集。
- 强调 outcome-oriented 测试,而不是要求 Agent 复刻人类命令路径。
- 发现真实终端环境中的“效率悖论”:token / 轮数越多,未必越强,往往反而意味着陷入错误探索。
具体案例剖析
论文里的一个经典例子是抓取 pcap 里的 HTTP Basic Auth。人类录像可能用 ettercap,Agent 却用 tshark + Python 脚本,也能完成任务。TerminalWorld 不会因为“命令不一样”就判失败,它只验证最终状态是否满足要求。
这说明一个关键事实:真正强的 agent benchmark 应该评估 目标达成,而不是评估“像不像人类按过的按钮”。这一点对 shell / browser / software agent 都很关键。
方法论与技术实现
整条 pipeline 大致是:先从 Asciinema 收集真实录屏,过滤掉含 PII、强交互 TUI 或无法复现的内容;再让 LLM 从 transcript 中抽取目标导向的任务描述和干净的参考解;然后自动构造 Docker 环境;最后根据执行前后状态差异生成 tests。
论文中最漂亮的工程点是测试生成的三重校准:AllPassing Trial、Nop Trial、Partial Trial。你可以把它理解成对测试脚本做充分性和必要性检查,避免 benchmark 变成“空跑也过”或“正确解也过不了”。
若形式化表示环境状态变化,可写成:执行参考脚本后得到状态差分 $\Delta S = S_{after} - S_{before}$,测试用例的目标就是验证 agent 最终是否重现关键状态差分。
实验设置与结论分析
在 TERMINALWORLD-VERIFIED 上,即便是最强闭源模型,通过率也没有到“接近解决”那种程度。论文更有意思的发现是:成功率和 token / 交互轮数呈明显负相关。这意味着现实终端环境里,瞎试越多往往越危险。
另一个重要结论是,模型在人工专家 benchmark 上的分数,与它在真实终端环境里的表现相关性很弱。这直接提醒大家:不要被漂亮的 benchmark leaderboard 迷惑,真实环境泛化才是硬指标。
关键技术亮点分析
- 给 terminal agent 社区提供了一个更接近真实世界的 benchmark 生成范式。
- 提出基于 state delta 的测试生成思想,通用于很多 software agent 场景。
- 对做 codex / claude code / shell agent 的团队,几乎是必读。