Self-Induced Outcome Potential: Turn-Level Credit Assignment for Agents without Verifiers
自发结果势能:无验证器Agent的回合级信用分配
作者:Senkang Hu, Yong Dai, Xudong Han, Zhengru Fang, Yuzhi Zhao, Sam Tak Wu Kwong, Yuguang Fang
机构:香港城市大学,牛津大学,复旦大学,萨塞克斯大学,华中科技大学,岭南大学等
📄 查看 ArXiv 原文
🔍 研究背景与痛点 (Background & Pain Points)
随着 OpenAI o1 和 DeepSeek-R1 的问世,大模型(LLM)正从静态的单次生成向包含长程推理(Long-horizon Reasoning)和外部交互(如搜索、工具调用)的 Agent 范式演进。在强化学习(RL)微调阶段,这种范式转变暴露出一个核心痛点:信用分配问题(Credit Assignment)。
- 结果级奖励(Outcome-level Reward)的稀疏性:当前主流 RL 训练只在轨迹末尾给奖励,难以定位中间哪一步检索或工具调用导致成败。
- 过程监督昂贵:现有回合级奖励塑造方法通常依赖 Gold Answer 或 task-specific verifier,在开放式 Agent 任务里往往不可得。
- 无标签 RL 粒度不足:像语义熵、自一致性等 label-free 方法多停留在 trajectory 级别,不能精细做到 turn-level credit assignment。
本文提出 SIOP (Self-Induced Outcome Potential),目标是在没有人工标签和外部验证器的情况下,仅利用模型自身输出分布,为多轮 Agent 提供精细的过程奖励。
💡 核心贡献 (Core Contributions)
- 提出无验证器回合级信用分配范式:把最终答案的语义聚类看作潜在未来状态。
- 设计 Self-Induced Outcome Potential,通过经验频率与证据可靠度校准构建势函数。
- 改造 GRPO 广播机制,使优势只分配给当前回合生成 Token。
- 给出理论退化分析与 7 个搜索增强 QA 基准上的强实验结果。
📖 具体案例剖析 (Case Study)
问题:“When is Zeinab Jammeh’s husband’s birthday?”
- Turn 1:错误检索导致正确语义簇概率从 0.147 降到 0.019,得到负奖励 $r_1=-1.45$。
- Turn 2:修正检索为 “Yahya Jammeh date of birth”,支持度回升,得到 $r_2=+0.20$。
- Turn 3:输出答案 “May 25, 1965”,最终支持度大幅提升,得到 $r_3=+2.79$。
这个例子说明,SIOP 可以在没有人工过程标签时,直接惩罚误导性检索并奖励有价值的探索。
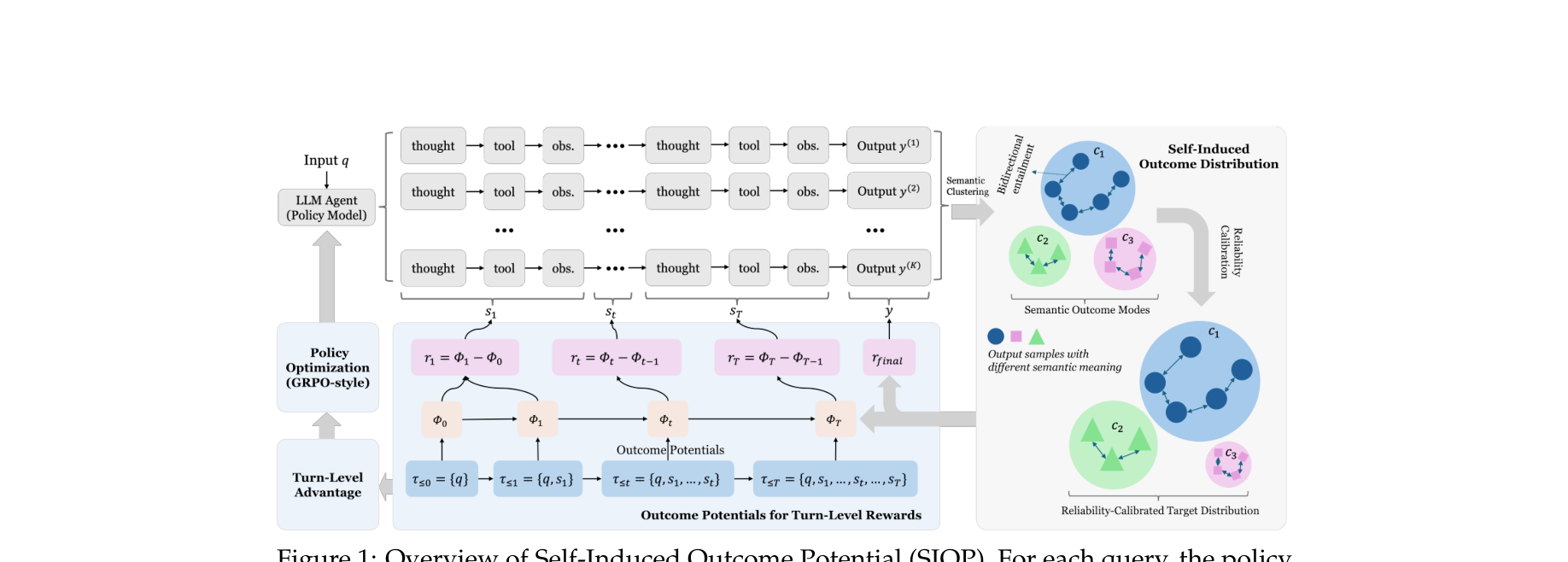 图注:SIOP 方法架构概览。先对多条 rollouts 的最终答案做语义聚类,再结合证据可靠度构造目标分布,最后把“前缀对命中语义簇的支持度变化”转成 turn-level 奖励。
图注:SIOP 方法架构概览。先对多条 rollouts 的最终答案做语义聚类,再结合证据可靠度构造目标分布,最后把“前缀对命中语义簇的支持度变化”转成 turn-level 奖励。⚙️ 方法论与技术实现 (Methodology)
核心流程包含:语义结果模式构建、可靠度校准、势能差过程奖励、Turn-conditioned policy optimization 四部分。
校准后的目标分布为:$$ q_\theta(c \mid q)=\frac{m(c \mid q)\exp(u_\theta(c,q))}{\sum_{c'} m(c' \mid q)\exp(u_\theta(c',q))} $$
过程奖励定义为:$$ r_{t,\text{proc}}^{(k)} = \Phi_\theta(\tau_{\le t}^{(k)}, c(k)) - \Phi_\theta(\tau_{\le t-1}^{(k)}, c(k)) $$
相比全轨迹优势广播,SIOP 只把当前 turn 的优势赋给当前 turn 的 token,显著降低噪声。
📊 实验设置与结论分析
覆盖 NQ、TriviaQA、HotpotQA、2Wiki、MuSiQue、Bamboogle、PopQA 7 个搜索增强 QA 基准,基座模型为 Qwen3-4B/8B。
- EM/F1 显著超越无验证器基线 TTRL、EMPO。
- 在多跳任务如 2Wiki、HotpotQA 上提升尤为明显。
- 在不使用 Gold Answer 的前提下,性能已逼近甚至局部追平带 Gold 的 outcome-level GRPO。
🌟 关键技术亮点分析
- 把“输出聚类”转化为 RL 状态空间,给零标签 Agentic RL 提供了新范式。
- 势能函数设计具备 telescoping 性质,理论漂亮且不易 reward hacking。
- 通过证据校准抑制“错误共识”。
- 工程上只额外引入轻量 NLI/聚类负担,具备落地价值。
TopoCurate: Modeling Interaction Topology for Tool-Use Agent Training
TopoCurate:为工具使用智能体训练构建交互拓扑模型
作者:Jinluan Yang, Yuxin Liu, Zhengyu Chen, Chengcheng Han, Yueqing Sun, Qi Gu, Hui Su, Xunliang Cai, Fei Wu, Kun Kuang
机构:浙江大学,美团
📄 查看 ArXiv 原文
🔍 研究背景与痛点
传统 tool-use agent 训练严重依赖 outcome-based filtering:SFT 只挑成功轨迹,RL 只看任务通过率。作者指出这会产生“结果等价错觉”:成功轨迹里可能充满冗余、死循环或脆弱捷径,导致模型学到的是低鲁棒性的行为。
💡 核心贡献
- 引入 semantic quotient topology,把同任务多条轨迹压成统一状态图。
- 为 SFT 定义 Reflective Recovery、Semantic Efficiency、Distributional Diversity 三类拓扑指标。
- 为 RL 定义 Error Branch Ratio 与 Strategic Heterogeneity,挑选更有梯度价值的任务。
- 在 Tau2 Bench 与 BFCLv3 上显著超越强基线。
🛠️ 具体案例剖析
论文展示了订单修改任务中的两条成功轨迹:一条高效完成定位订单、计算差价、确认礼品卡并提交;另一条则多次插入无必要的状态确认和用户复述。标准 outcome filtering 认为两者都“成功”,但 TopoCurate 会利用拓扑最短路与恢复模式,优先保留前者、降低后者权重。
⚙️ 方法论与技术实现
通过语义相似度把等价 action-observation state 合并入同一图节点,定义节点成功潜力 $\Phi(v)$。SFT 阶段用恢复性、效率、多样性重加权成功轨迹;RL 阶段用结构性失败分支和策略异质性提升梯度信噪比。
Error Branch Ratio 示例:$$V_{struct}(\mathcal{T}) = \frac{1}{|\mathcal{B}|}\sum_{v\in\mathcal{B}}\frac{|\{u\in children(v):\Phi(u)<\epsilon_{fail}\}|}{|children(v)|}$$
📊 实验设置与结论分析
- 在 Tau2 测试中,TopoCurate-SFT 明显优于 APIGen-MT 与 Simia-Tau。
- 相同初始化下,拓扑任务筛选 RL 比均匀采样收敛更快、最终 reward 更高。
- Reflective Recovery 与 Diversity 是最关键的两类信号。
🌟 关键技术亮点分析
- 从“结果对不对”升级到“过程好不好”。
- 把理论上的 KL/自然梯度分析和工程上的数据选择真正打通。
- 提供了 data-centric agent training 的很强范式。
AT²PO: Agentic Turn-based Policy Optimization via Tree Search
基于树搜索的智能体回合级策略优化
作者机构:Tencent Inc, 中山大学, 深圳北理莫斯科大学
📄 查看 ArXiv 原文
💡 研究背景与痛点
- 探索多样性受限:固定 rollout 预算下,现有扩展策略不够聪明。
- 信用分配稀疏:结果奖励往往只在多轮交互结束时出现。
- 优化粒度错位:传统 GRPO/PPO 把整个交互展平成 token 序列,而 agent 自然结构是 turn-based。
🚀 核心贡献
- 熵导向树扩展:优先扩展高不确定性节点。
- 回合级信用分配:用树拓扑把叶子奖励向上回传。
- ATPO:把 importance sampling 与 clipping 锚定在 turn 级别,而不是 token 或整序列级别。
🔍 具体案例剖析
HotpotQA 多跳案例里,Agent 先搜 Kasper Schmeichel 的父亲,定位到 Peter Schmeichel,再搜索其 1992 年 IFFHS 奖项,最终输出 “World's Best Goalkeeper”。AT²PO 能把最终正确奖励精确回传到两次关键 search turn,而不是粗糙广播给全轨迹所有 token。
⚙️ 方法论与技术实现
节点策略熵近似为:$$ H_{\pi_\theta}(n) \approx \frac{1}{|y^k|} \sum_{y_t \in y^k} -\log \pi_\theta(y_t|x,y^{树上的节点价值通过叶子奖励自底向上回溯。ATPO 再按 turn 计算重要性采样比率与 clipping,兼顾 token 级求导与 turn 级 trust region。
📊 实验设置与结论分析
- 在多跳 QA 上平均 EM 明显优于 GRPO、DAPO、GSPO、Tree-GRPO。
- 越是长 horizon、多 turn 的任务,提升越明显。
- 训练过程中的 turn entropy 更稳定,不容易早期熵坍塌。
🌟 关键技术亮点分析
- 明确指出 agentic RL 不该再用“平坦 token”视角优化。
- 树搜索用于训练阶段的 directed exploration 很有现实意义。
- 文中对 retokenization drift 的工程分析非常值钱。
VSearcher: Long-Horizon Multimodal Search Agent via Reinforcement Learning
VSearcher:基于强化学习的长程多模态搜索智能体
作者:Ruiyang Zhang, Qianguo Sun, Chao Song, Yiyan Qi, Zhedong Zheng
机构:University of Macau, IDEA
📄 查看 ArXiv 原文
🔍 研究背景与痛点
当前强 Agent 进展主要聚焦 text-only LLM,而现实世界的大量检索任务天然是 multimodal 的。多模态模型虽然有视觉能力,但缺乏长程工具调用训练,仍被困在静态知识边界内。
💡 核心贡献
- 提出 Iterative Injection 数据合成流,自动构造多模态长程搜索题。
- 采用 RFT + GRPO 的系统化 post-training 流程。
- 构建高难度 MM-SearchExam 基准。
- VSearcher 在多个多模态搜索基准上击败多种开源甚至闭源模型。
🕵️ 具体案例剖析
艺术品分类案例中,Agent 先用 image search 识别图片中的 “Cage d'oiseau”,再多轮 text search 验证它与 Duchamp 的 Bicycle Wheel 是否同属 installation art,最终输出 Yes。整个过程体现了视觉识别 -> 文本检索 -> 深度验证的多模态长链推理。
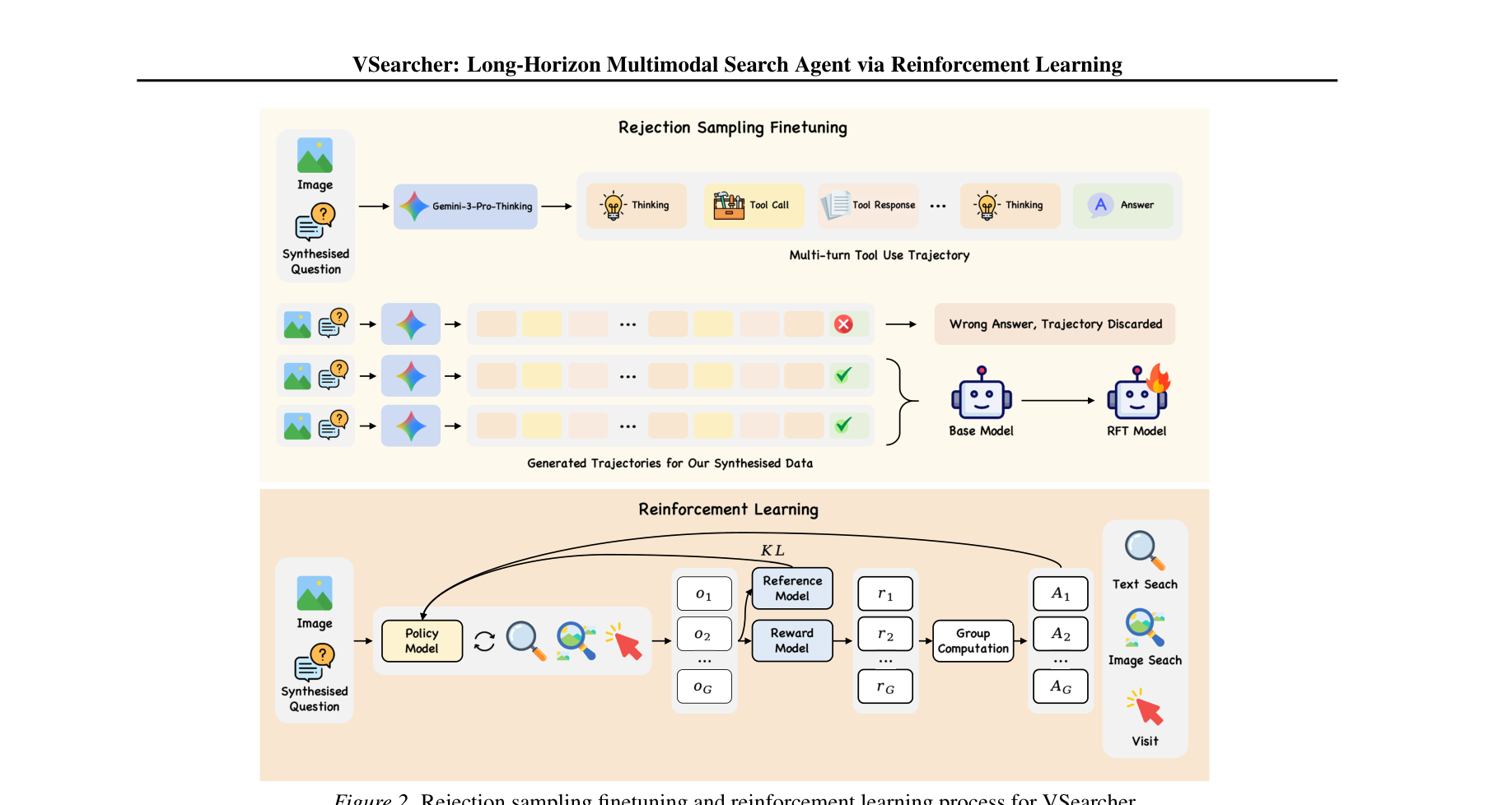 图注:VSearcher 的两阶段后训练框架:先做 rejection sampling finetuning,再在真实 Web 环境中进行 GRPO 强化学习。
图注:VSearcher 的两阶段后训练框架:先做 rejection sampling finetuning,再在真实 Web 环境中进行 GRPO 强化学习。⚙️ 方法论与技术实现
通过 Wikidata/Wikipedia 进行实体隐藏、冷门信息注入和图片注入,构造必须依赖外部搜索的难题。教师模型在真实 Web 工具环境中生成高质量轨迹,经 RFT 注入基础 agent 能力;随后在真实工具链上做 GRPO,奖励设计保持极稀疏、格式检查极严格。
SFT 损失:$$ \mathcal{L}_{SFT} = -\frac{1}{N} \sum_{i=1}^{N} \sum_{t=1}^{T_i} \log \pi_\theta(o_{i,t} \mid o_{i,
📊 实验设置与结论分析
- 在 MMSearch、BrowseComp-VL、MM-BrowseComp 等基准上表现极强。
- MM-SearchExam 难度很高,但 VSearcher 依然取得明显领先。
- RL 后 visit 工具调用显著增加,说明模型学会“深入网页读证据”,而不只是停留在 snippet 层。
🚀 关键技术亮点分析
- 真实 Web 驱动的 RL 比静态沙盒更能逼出鲁棒策略。
- Iterative Injection 是很漂亮的数据飞轮方案。
- 严格格式控制对 Agentic RL 收敛非常关键。
KARL: Knowledge Agents via Reinforcement Learning
KARL:通过强化学习构建的知识智能体
作者 / 机构:Databricks AI Research
📄 查看 ArXiv 原文
🔍 研究背景与核心痛点
企业级 grounded reasoning 依赖未见过的私有知识库。现有评测不全面、训练数据稀缺,而 online RL 在复杂模型与推理基础设施上工程代价极高。
💡 核心贡献
- 提出 KARLBench,多能力异构搜索基准。
- 设计 Agentic Synthesis,让 Agent 自己探索语料并合成高质量 grounded QA/trajectory。
- 提出 OAPL,大批量离线 off-policy RL 框架。
- 在成本、延迟、质量上取得极强 Pareto 表现。
🔬 具体案例剖析
在 BrowseComp-Plus 案例中,基础模型要么过早放弃,要么陷入无限验证;KARL 学会在证据足够时进行 probabilistic commitment,既保持搜索韧性,也能及时收束。另一个 TREC-Biogen 案例则展示了它如何从“癫痫发作可能导致骨折”这一线索出发,动态调整 query 深挖隐藏原因。
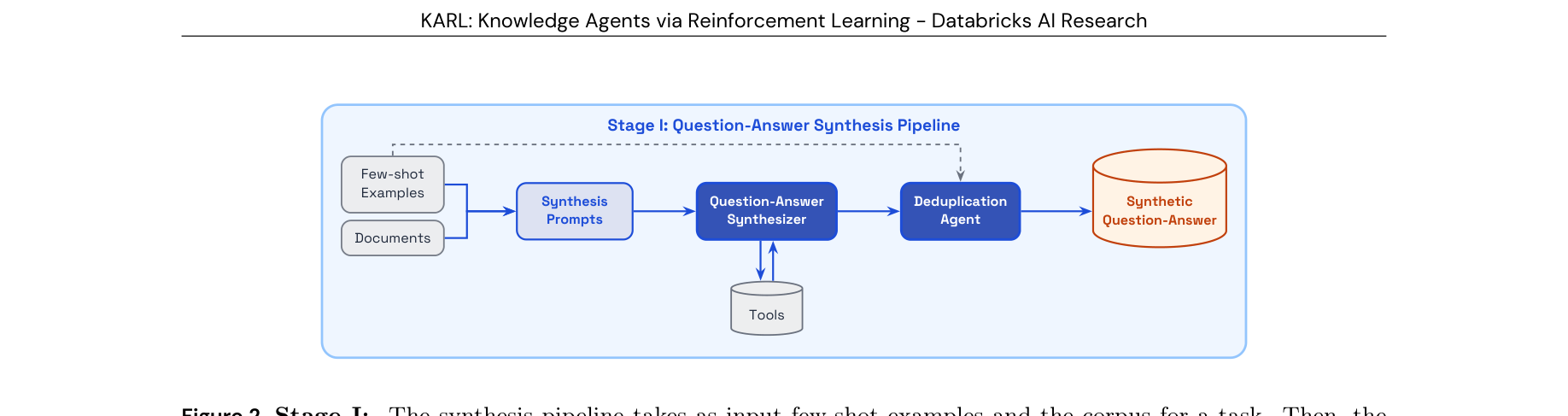 图注:KARL 的 Agentic Synthesis 第一阶段:智能体主动探索知识库、提出 grounded QA,并通过去重与过滤形成高质量 RL 训练数据。
图注:KARL 的 Agentic Synthesis 第一阶段:智能体主动探索知识库、提出 grounded QA,并通过去重与过滤形成高质量 RL 训练数据。⚙️ 方法论与技术实现
Agentic Synthesis 包含 QA 生成与 solution synthesis/filtering 两阶段。OAPL 则直接在旧策略样本上做最小二乘回归,天然容忍 off-policy。
其核心目标:$$\min_{\pi} \sum_x \sum_{i=1}^G \left( \beta \ln \frac{\pi(y_i|x)}{\pi_{\text{ref}}(y_i|x)} - \left(r(x,y_i)-\hat{V}^*(x)\right) \right)^2$$
同时,作者把 context compression 本身也纳入 Agent 动作空间,通过最终 reward 端到端训练模型的“记忆压缩”策略。
📊 实验设置与结论分析
- Multi-task RL 相比 SFT 蒸馏在 OOD 任务上更有泛化力。
- 借助 Parallel Thinking / VGS 等 TTC 手段,KARL 进一步逼近甚至持平顶级闭源模型。
- 即使并行采样,查询成本和延迟仍显著优于高价闭源对手。
🌟 关键技术亮点分析
- 给出 RL 不只是 sharpening,而是真能学到新搜索策略的强证据。
- OAPL 为工业界提供了 online RL 的高性价比替代方案。
- 把 memory/compression 也内化进 Agent 决策,方向很前沿。