SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks
SWEET-RL:在协作推理任务上训练多轮 LLM Agent
作者:Yifei Zhou, Song Jiang, Yuandong Tian, Jason Weston, Sergey Levine, Sainbayar Sukhbaatar, Xian Li
机构:FAIR at Meta, UC Berkeley
📄 查看 ArXiv 原文
研究背景与痛点
多轮 Agent 任务最大的难点不是单步回复质量,而是长链路信用分配。传统 PPO/DPO 在多轮交互中很难判断哪一轮真正推动了最终成功,训练信号高方差、泛化差,且现有评测环境往往工程过重。
核心贡献
- 提出 ColBench:低成本但具备真实协作味道的多轮 Agent benchmark。
- 提出 SWEET-RL:利用训练时特权信息做 step-wise advantage 学习,绕开难训的 value head。
- 证明 8B 级模型经多轮 RL 后可逼近甚至打平部分闭源强模型在协作推理任务上的表现。
具体案例剖析
在后端编程任务里,普通模型会在需求不完整时“自信脑补”边界条件,最终单测不过;SWEET-RL 训练后的 Agent 会持续追问关键条件,例如比例阈值、特殊输入分支、证件约束,再在信息充分后给出代码,因此通过率显著提升。
方法论与技术实现
核心思想是让 Critic 在训练时看到参考答案/目标图像等特权信息 c,从而更准确地估计每一轮动作的好坏,而不是硬拟合全局 value。
其优势学习采用 Bradley-Terry 风格目标:$$ \mathcal{J}_A(\theta)=-\log\sigma\Big(\sum_t \beta A_\theta(o_t^+,a_t^+,c)-\sum_t \beta A_\theta(o_t^-,a_t^-,c)\Big) $$
更关键的是,作者不再外挂 regression head,而是直接复用语言模型 head 的对数概率残差去表征 advantage,这样更贴合 LLM 预训练分布。
实验设置与结论分析
在 ColBench 上,SWEET-RL 相比多轮 DPO 在后端编程与前端设计任务上都取得稳定提升;对 8B 模型而言,增幅足以追平或超越部分更大规模或闭源基线。
关键技术亮点分析
- 把“特权信息”当作训练期信用分配工具,而不是测试期依赖。
- 用 LM head 替代 value head,极大改善泛化。
- 给多轮 Agent RL 提供了低成本、可扩展的评测与训练闭环。
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
Agentic LLM 强化学习全景综述
作者:Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, 等
机构:Oxford、上海 AI Lab、NUS、UIUC 等
📄 查看 ArXiv 原文
研究背景与痛点
传统 RLHF / DPO 实际上只是在单轮文本生成上对齐静态偏好,而真正的 Agent 要面对动态环境、部分可观测状态、结构化动作和延迟奖励。两者不是小修小补的差异,而是从退化单步 MDP 到完整 POMDP 的范式迁移。
核心贡献
- 系统区分 PBRFT 与 Agentic RL 的理论边界。
- 从能力视角与任务视角梳理 Agentic RL 版图。
- 汇总开源环境、训练框架、安全问题与 scaling law 争议。
具体案例剖析
论文用 Deep Research、形式化数学、具身环境等案例说明:RL 不只是提升回答风格,而是在塑造“何时搜索、何时回溯、何时调用工具、何时验证”的策略结构。
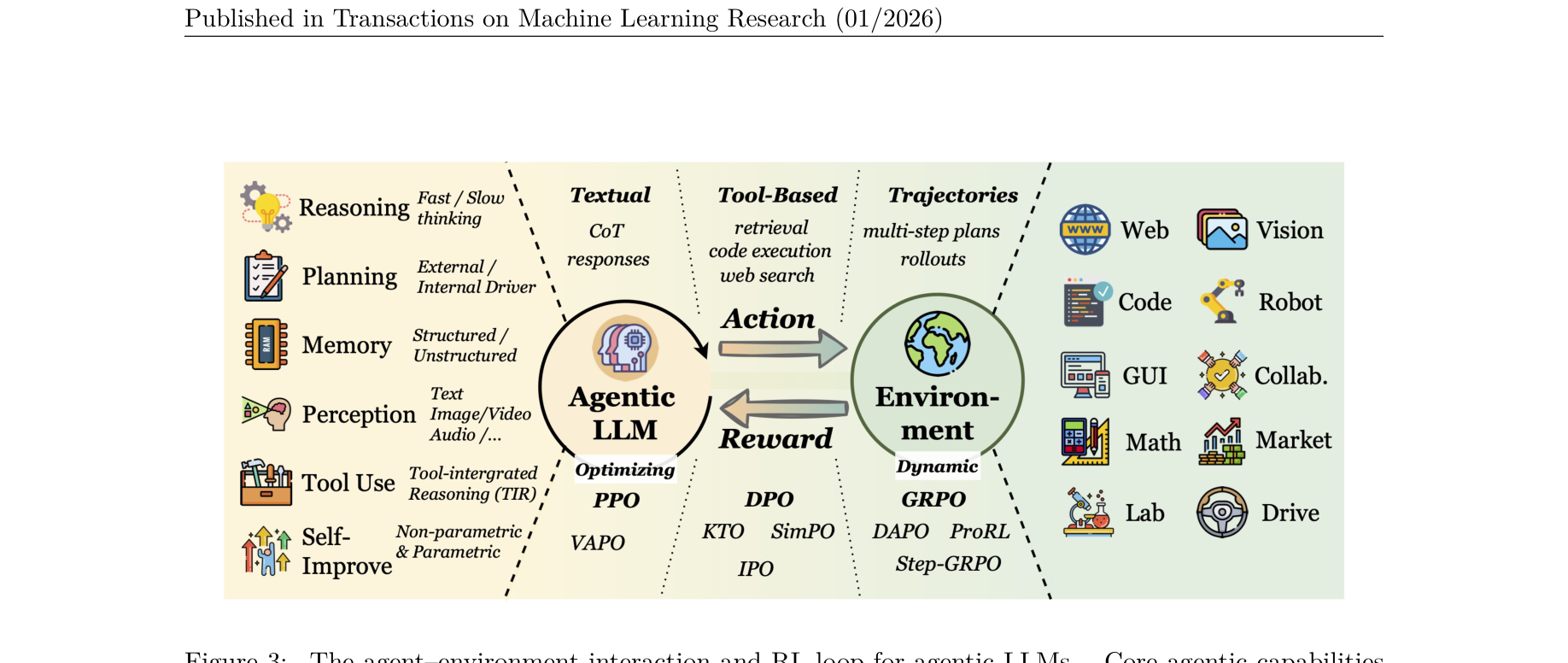 图注:Agent 与环境交互闭环。模型的推理、工具、记忆等能力在外部环境反馈与奖励信号中被共同塑形。
图注:Agent 与环境交互闭环。模型的推理、工具、记忆等能力在外部环境反馈与奖励信号中被共同塑形。
方法论与技术实现
论文把 Agentic RL 定义为在动态环境中的长期累积奖励优化:$$ J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}\left[\sum_{t=0}^{T-1}\gamma^t \mathcal{R}(s_t,a_t)\right] $$
动作空间不再只是自然语言 token,还包含结构化工具调用与环境操作。因此 RL 训练必须同时处理推理 token 与外部 action 的联合信用分配问题。
实验设置与结论分析
作为综述,重点不在单一实验,而在证明各类前沿工作已在搜索、代码、GUI、具身和数学场景中形成清晰脉络:验证奖励、过程奖励、异步环境与 GRPO/PPO 变体是当前主线。
关键技术亮点分析
- 明确了 Agentic RL 与传统对齐的本质差异。
- 说明 RL 在 Agent 中的价值是“策略学习”,不只是输出重排。
- 把安全、reward hacking 与新能力争议一起放进统一框架中讨论。
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
AgentGym-RL:多轮 RL 驱动的长程决策 LLM Agent
作者:Zhiheng Xi, Jixuan Huang, Chenyang Liao, et al.
机构:复旦大学、字节 Seed、上海创新学院
📄 查看 ArXiv 原文
研究背景与痛点
单轮 RL 已经能提高推理,但长程外部交互任务会带来新的难题:轨迹更长、回报更稀疏、探索更容易崩。直接把交互轮数拉满,经常导致模型在早期陷入无意义尝试。
核心贡献
- 提出 AgentGym-RL 统一框架,打通环境、agent、训练模块。
- 提出 ScalingInter-RL:先短交互学会“利用”,再逐步放开 horizon 做“探索”。
- 在多类真实环境中显著提升开源模型表现,部分指标超过闭源强模型。
具体案例剖析
在网页导航任务中,普通模型容易在点错链接后卡死循环;经过训练的 Agent 会主动回退、重新搜索、调整策略。在具身任务中,它也更擅长战略性回溯,而不是无效打转。
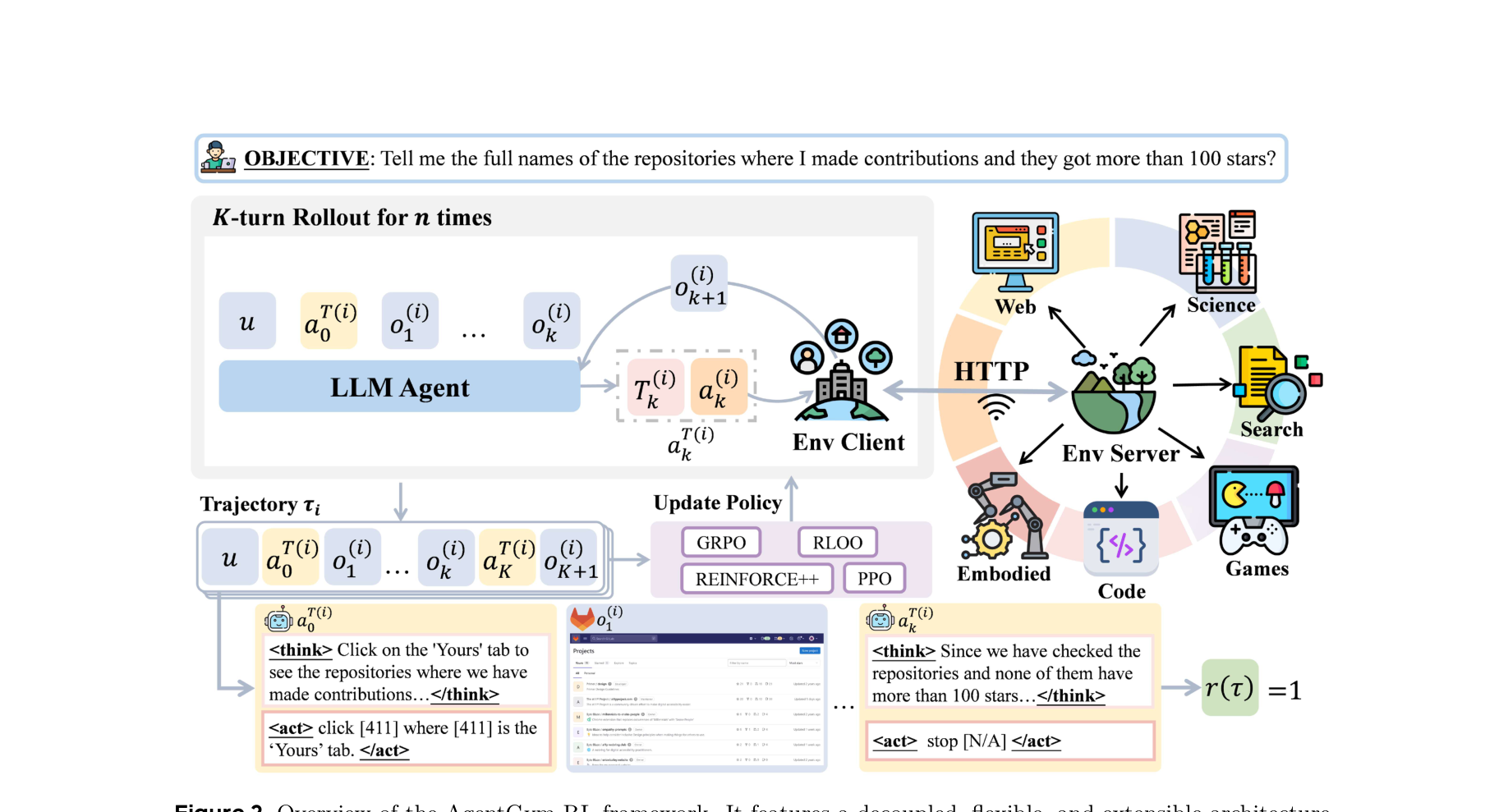 图注:AgentGym-RL 把环境客户端、LLM Agent 与训练引擎解耦,支持多环境统一 rollout 与多种在线 RL 算法。
图注:AgentGym-RL 把环境客户端、LLM Agent 与训练引擎解耦,支持多环境统一 rollout 与多种在线 RL 算法。
方法论与技术实现
作者将任务建模为 POMDP,并用逐步增加交互上限的课程式训练降低 early-stage 崩溃风险。目标形式仍是最大化期望回报:$$ J(\theta)=\mathbb{E}_{\tau\sim\pi_\theta}[r(\tau)] $$
ScalingInter-RL 的关键在于:早期小 horizon 强迫模型先学会高价值短链行为;当这些基础能力稳定后,再增加交互预算,释放更深层探索能力。
实验设置与结论分析
在 WebArena、TextCraft、BabyAI、SciWorld 等场景中,该方法相较固定长交互训练更稳定,最终回报更高,且 GRPO 在长轨迹下显著优于 REINFORCE++。
关键技术亮点分析
- 把“test-time compute scaling”扩展为“external interaction scaling”。
- 用课程式交互长度控制缓解 credit assignment 和探索崩溃。
- 提供了可复用的多环境 Agent RL 开源基建。
AGENTRL: Scaling Agentic Reinforcement Learning with a Multi-Turn, Multi-Task Framework
AgentRL:多轮多任务 Agentic RL 扩展框架
作者:Hanchen Zhang, Xiao Liu, et al.
机构:清华大学, Z.AI
📄 查看 ArXiv 原文
研究背景与痛点
一旦从单任务走向多任务、多环境、多轮交互,RL 系统不只面临算法挑战,还会遇到异步 rollout、环境调度、梯度干扰和探索坍塌等工程与优化双重瓶颈。
核心贡献
- 提出异步生成-训练架构,提高多轮任务下的吞吐。
- 引入 Cross-Policy Sampling,用历史策略池扩展探索而不破坏语言合法性。
- 引入 Task Advantage Normalization,稳定多任务联合训练。
具体案例剖析
在知识图谱任务中,单一模型可能卡在“会推理但不调用工具”或“敢调工具但参数乱填”的局部失败模式。交叉策略采样允许不同策略片段在同一轨迹中接力,形成单一策略难以达到的成功路径。
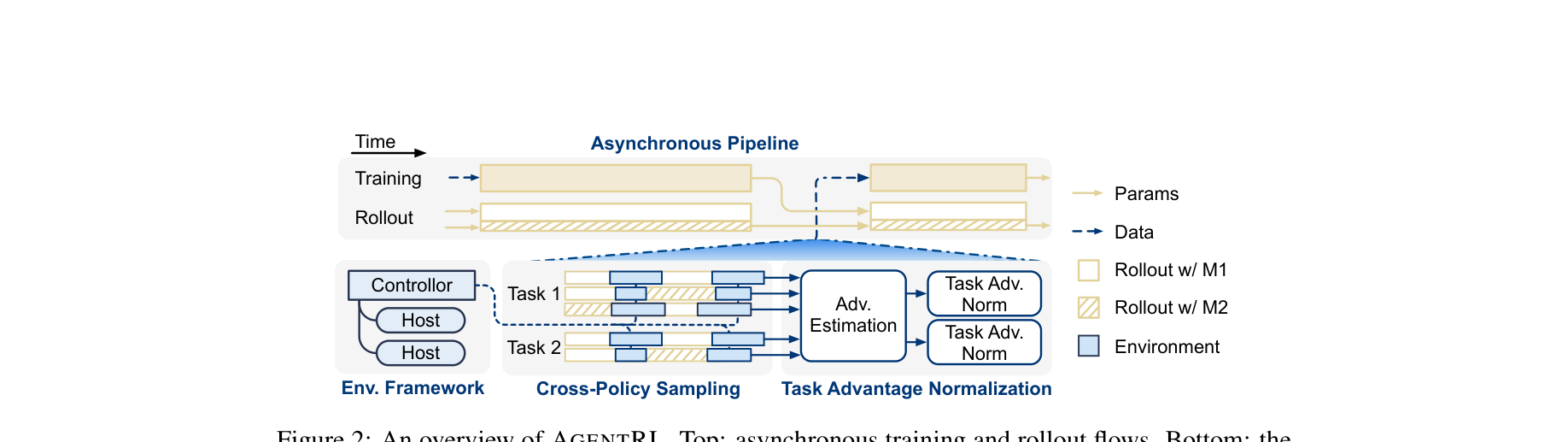 图注:AgentRL 整体架构:异步 rollout / training、集中式环境控制,以及 cross-policy sampling 与 task-wise normalization 两个关键算法模块。
图注:AgentRL 整体架构:异步 rollout / training、集中式环境控制,以及 cross-policy sampling 与 task-wise normalization 两个关键算法模块。
方法论与技术实现
交叉策略采样可写作:$$ a^{c,(t)} \sim \mathrm{random}(\mathcal{M})(\cdot\mid s^{(t)}) $$ 其中 \(\mathcal{M}\) 是由历史 checkpoint 或多个策略构成的模型池。
任务级 advantage 归一化则在每个任务内部做零均值单位方差标准化:$$ \tilde{A}_{i}=\frac{A_i-\mu_i}{\sigma_i} $$ 这样能显著降低多任务梯度量纲不一致带来的训练震荡。
实验设置与结论分析
在 AgentBench-FC 多环境评测中,AgentRL 对 Qwen 系列模型带来大幅提升,多任务统一模型能逼近甚至达到“多个专家模型取最优”的组合效果。
关键技术亮点分析
- 把探索噪声从“token 级随机性”升级为“策略级多样性”。
- 说明多任务 RL 的核心不只是 mix data,而是处理 advantage 的量纲与分布。
- 异步架构对 Agent RL 的系统意义非常接近 vLLM 对推理服务的意义。
EARL: Efficient Agentic Reinforcement Learning Systems for Large Language Models
EARL:高效 Agentic RL 系统设计
作者:Zheyue Tan, Mustapha Abdullahi, Tuo Shi, Huining Yuan, Zelai Xu, Chao Yu, Boxun Li, Bo Zhao
机构:Aalto University, Tsinghua University, Infinigence-AI
📄 查看 ArXiv 原文
研究背景与痛点
Agentic RL 在系统层的主要痛点是上下文长度爆炸和中间张量传输瓶颈。长轨迹会把 KV cache 和中间状态拉到极端规模,导致 OOM、低吞吐和中心化调度拥堵。
核心贡献
- 提出动态并行选择器,根据上下文长度动态切换 TP 配置。
- 提出去中心化 data dispatcher,用 all-to-all 直连替代 gather-scatter。
- 证明无需靠硬截断也能稳定支撑大规模 Agentic RL 训练。
具体案例剖析
论文用井字棋等多轮任务展示:一旦上下文触碰硬上限,粗暴截断会把低质量轨迹送回经验池,形成负反馈飞轮,最终把回报曲线拉崩。问题根源不是算法不会,而是系统承载不住。
方法论与技术实现
EARL 的关键不是发明新 RL 损失,而是根据序列长度与系统负载动态选择并行配置,使 tokens-per-GPU-per-second 最大化。吞吐提升可写作:$$ \mathrm{Speedup}(a,b)=\frac{TGS(b)-TGS(a)}{TGS(a)}\times 100\% $$
另一关键点是识别哪些中间张量不需要全局聚合,直接进行点对点或 all-to-all 布局感知分发,从而大幅降低大规模训练时的数据传输时间。
实验设置与结论分析
在 128 张 H100 的实验中,EARL 在长上下文设置下显著降低 OOM 风险,并把关键传输阶段的延迟压缩到原来的十分之一量级。
关键技术亮点分析
- 指出 Agentic RL 的瓶颈常常不是 reward,而是系统架构。
- 动态并行比静态配置更符合 RL 训练中上下文持续增长的现实。
- 通信拓扑优化对超大规模 Agent RL 至关重要。