LiveBrowseComp: 搜索智能体是在真正搜索,还是仅仅在验证他们已知的知识?
LiveBrowseComp: Are Search Agents Searching, or Just Verifying What They Already Know?
作者:HuiMing Fan, Xiao Wang, Zheng Chu, Qianyu Wang, Zhuoyao Wang, Ming Liu, Bing Qin, XingYu
机构:哈尔滨工业大学 (HIT),小红书
🔍 研究背景与痛点 (Background & Problem Statement)
随着大语言模型(LLMs)从单纯的文本生成器向自主智能体(Autonomous Agents)演进,像 OpenAI Deep Research 和 Gemini Deep Research 这样的“搜索智能体(Search Agents)”正成为核心应用。与之并行,评测基准也从单轮问答(如 TriviaQA)发展到了复杂的多步网页浏览基准(如 BrowseComp、DeepSearchQA)。当前前沿模型在这些静态搜索基准上取得了极高的分数。
然而,本文提出了一个极为尖锐且根本的问题:这些高分是否证明智能体具备了真正的“搜索与发现”能力?还是它们仅仅在利用搜索引擎来验证其通过预训练已经记住的参数化知识(Parametric Knowledge)?
作者团队通过一系列精巧的诊断实验(Pilot Study)揭示了一个严峻的失败模式——内在知识依赖(Intrinsic Knowledge Dependence, IKD):
- 闭卷作答即高分: 在剥夺所有搜索工具的情况下,某些前沿模型(如 MiniMax M2.5)在 BrowseComp 上的“闭卷(Closed-book)”准确率高达 44.5%。这意味着基准中近一半的问题早已在其参数记忆中。
- 屏蔽证据导致崩溃: 如果保留搜索环境,但人为移除所有包含正确答案的支撑文档(Evidence-blocked),模型的表现甚至低于闭卷作答。这说明搜索并没有帮它们发现新知识,反而把它们带偏了。
- 假设驱动而非证据驱动: 轨迹分析显示,超过一半的搜索 Query 源于模型自身的内部假设,而非基于检索到的线索;更糟的是,即使检索到了关键证据,模型也有约 70% 的概率未能利用它来修正答案。
综上,静态基准严重混淆了“模型已经知道什么”与“模型能发现什么”,变相奖励了基于记忆的“猜测-验证”行为,而非真正的证据驱动搜索。
💡 核心贡献 (Core Contributions)
- 首次系统性揭露搜索智能体的 IKD 现象: 提出了包括闭卷覆盖率(Closed-book coverage)、证据屏蔽搜索(Evidence-blocked search)和轨迹溯源(Trajectory grounding)在内的诊断框架,量化了当前模型对参数化知识的严重依赖。
- 提出 LiveBrowseComp 动态评测基准: 设计了一个全新的深度搜索基准,包含 335 个由人类专家构建的多步推理问题。所有问题的线索均锚定于构建前 90天内 发生的、且经过严格长尾过滤(非全球性突发热点)的事件,彻底阻断了模型的参数化记忆捷径。
- 揭示真实搜索能力梯队,重塑模型榜单: 在 LiveBrowseComp 上,所有评估模型的闭卷准确率骤降至 2% 以下(IKD 被有效消除)。在启用搜索后,模型得分相较于 BrowseComp 暴跌 25-40 分,且模型排名发生了剧烈洗牌,证明了静态榜单无法真实预测模型在未知领域的探索能力。
🔎 具体案例剖析 (Case Study)
LiveBrowseComp 的核心设计理念是:将多步推理(Multi-hop Reasoning)与时间锚点(Temporal Anchor)相交织。以下是论文中的一个典型构建案例(对应原论文 Table 2):
Question: "In 2026, a CVE vulnerability has been publicly disclosed. It is a flaw affecting server interfaces, targeting files with specific filename prefixes... In addition, a vulnerability with a CVSS 3.x score 0.7 points higher than that of the server interface vulnerability was once found in an email marketing management tool. Attackers can launch attacks via two PHP files with highly similar names, and this vulnerability is of the same type as the server interface vulnerability. Could you please tell me in which year the vulnerability of this email marketing management tool occurred?"
Answer: 2020
案例解析:在这个问题中,蓝色的线索(2026年的某个特定CVE漏洞)是时间锚点(Temporal Anchor),它发生在模型训练数据截止日期之后(最近90天内)。
- 智能体无法依靠内部知识猜出这个2026年的CVE是什么,必须通过真实的动态搜索来定位该漏洞,并提取其 CVSS 3.x 分数。
- 随后,智能体必须执行数值推理(CVSS分数 + 0.7)。
- 最后,利用计算出的新分数、漏洞类型以及“电子邮件营销管理工具”、“两个PHP文件”等线索发起二次搜索,定位历史固定知识(2020年的目标漏洞)。
这种设计精妙地保留了长程浏览和多跳推理的难度,同时通过一个强时间约束卡死了“闭卷作弊”的可能。
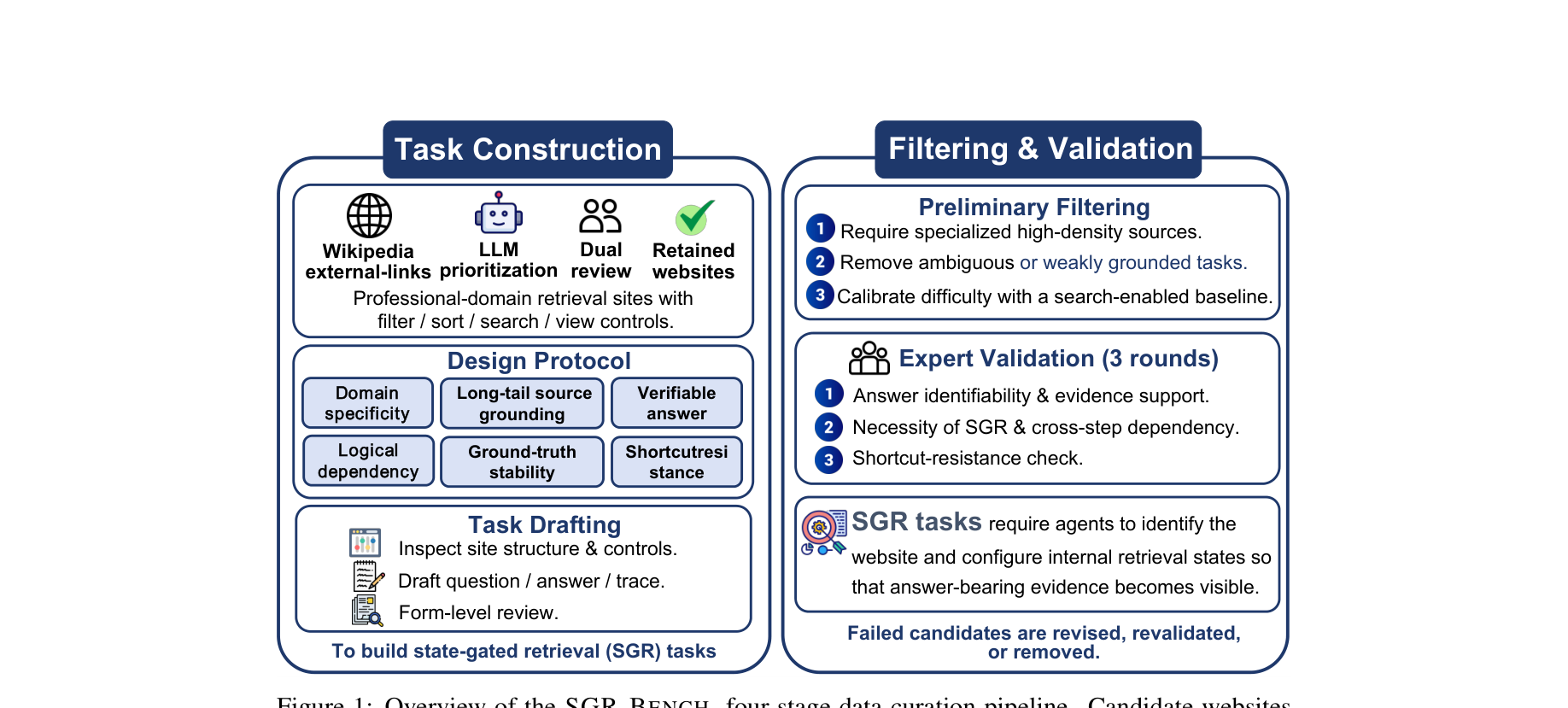
⚙️ 方法论与技术实现 (Methodology & Implementation)
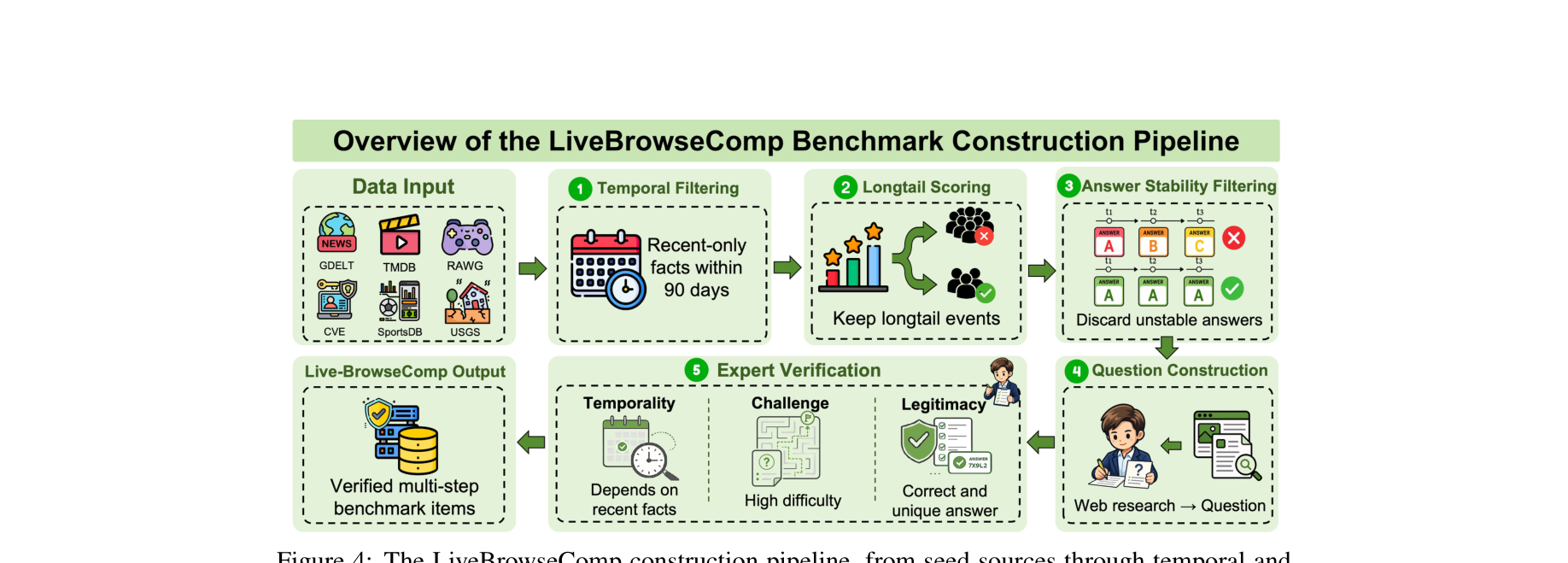
LiveBrowseComp 的构建并未依赖容易产生幻觉的 LLM 自动生成,而是采用了一套极其严格的人类专家参与+机器过滤的五阶段流水线:
- Data Input (数据源多样性): 接入6个持续更新的结构化事实来源的 API:GDELT、TMDB、RAWG、CVE/NVD、SportsDB、USGS。
- Stage 1: Temporal Filtering: 强制过滤掉所有发生时间早于构建前 90 天的事件。
- Stage 2: Long-tail Filtering: 过滤高曝光主流事件,阻断模型参数记忆捷径。
- Stage 3: Answer Stability: 剔除在窗口期内会变动的数据,确保唯一答案。
- Stage 4-5: Question Construction & Peer Review: 由人工构建多跳问题并做时效与难度复核。
此外,作者还构建了稠密检索环境进行证据屏蔽实验,严谨地验证 IKD 现象。
📊 实验设置与结论分析 (Experiments & Analysis)
作者在 LiveBrowseComp 上评估了 11 款前沿模型。所有模型统一使用 Agent Scaffold、最大 256k tokens 上下文和 250 步探索预算。
- 性能断崖式下降: 从静态基准 BrowseComp 迁移到 LiveBrowseComp 后,得分普遍暴跌 25-40 分。
- 闭卷泡沫被戳破: 在 LiveBrowseComp 上,所有模型的闭卷准确率都低于 2%。
- 行为模式改变: 短轮数“搜一下确认”模式消失,分布转向更长的探索式搜索轨迹。
- 人类基线稳定: 人类在两个基准上的耗时与成功率近似一致,说明困难主要来自模型失去记忆捷径,而不是问题本身更难。
🌟 关键技术亮点分析 (Key Technical Highlights)
- 评测范式升级: 必须把“参数化知识覆盖率”纳入搜索智能体评测视角,而不只是做字面去污。
- 对 Agent RL/SFT 的启示: 当前训练流程可能过度奖励模型自信,而没有充分奖励“依据新证据改写假设”的行为。
- 高成本但高可信: 相比 LLM 自动生成 benchmark,这套人工重构+动态时效约束的范式更像真正的 frontier benchmark。