MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning
中文标题:MemSearcher:通过端到端强化学习训练大模型进行推理、搜索与记忆管理
核心作者:Qianhao Yuan, Jie Lou, Zichao Li 等
核心机构:中国科学院软件研究所(ISCAS)、小红书(Xiaohongshu Inc)、中国科学院大学
研究背景与痛点
目前,基于大语言模型(LLM)的搜索智能体(Search Agents)在知识获取和多跳推理任务中展现出强大的能力。相比于传统的RAG系统,这些Agents以 ReAct(Reason + Act)为代表范式,能够自主决定何时调用搜索引擎以及如何整合外部信息。然而,随着交互轮数的增加,ReAct 范式暴露出致命瓶颈:
- 上下文长度的线性灾难: ReAct 将所有的历史 Thoughts、Actions、Observations(通常是大量的网页片段)直接拼接到当前上下文中。这导致计算成本(FLOPs)和 GPU 显存(KV Cache)开销随轮数呈现 $O(n^2)$ 级暴增。
- “迷失在中间”与信息噪音: 检索到的外部文档往往夹杂大量与当前问题无关的噪音。冗长且嘈杂的上下文会严重削弱 LLM 提取关键信息的推理能力(即“Lost in the Middle”现象)。
核心贡献
- 提出 MemSearcher 架构: 摒弃了 ReAct 机械拼接历史的做法,利用骨干 LLM 作为“记忆管理器”(Memory Manager),在每轮交互中迭代并维持一个极度紧凑的记忆文本,仅保留对回答问题有价值的浓缩信息,使上下文长度保持常数级别。
- 引入 Multi-Context GRPO 算法: 由于 MemSearcher 每一轮所基于的 LLM Context 各不相同(记忆被不断覆写),传统的 RL 算法难以直接优化。作者提出了多上下文的 Group Relative Policy Optimization (GRPO),将轨迹级别的奖励(Trajectory-level Advantages)广播给每个独立的回合,实现了完全端到端的 RL 训练。
- 显著的性能与效率跨级击杀: 仅有 3B 和 7B 参数的 MemSearcher 模型,在 NQ、HotpotQA 等复杂基准测试中不仅完胜同级竞争者,甚至超越了体积大得多的 ReSearch-32B 模型,同时将单轮回合推理的计算复杂度从 $O(n)$ 降维至 $O(1)$。
具体案例剖析 (Case Study)
论文中展示了一个复杂的多跳信息搜集过程,问题为:“What was the form of the language that the last name Sylvester comes from, used in the era of Rotrude's father, later known as?(Sylvester 姓氏来源语言在 Rotrude 父亲——即后来的神圣罗马帝国皇帝——那个时代的形式是什么?)”
MemSearcher 的交互流如下:
- Turn 1: 模型决定先查 Sylvester 的语言来源。获取维基信息后,提取出核心知识:
<memory> Sylvester 这个姓氏来源于拉丁语(Latin)。</memory> - Turn 2: 模型根据记忆,意识到需要查 Rotrude 的父亲是谁。搜索后发现父亲是 Charlemagne(查理曼大帝)。此时模型将新旧知识融合,更新记忆:
<memory> Sylvester 来源于拉丁语。Rotrude 的父亲是 Charlemagne。</memory> - Turn 3-4: 模型进一步搜索 Charlemagne 后来的头衔(神圣罗马帝国皇帝)以及他所处时代的拉丁语形式。搜索结果返回了 Medieval Latin。
- Turn 5 (最终解答): 模型直接读取最新的记忆流,推断出当时使用的是 Medieval Latin(中世纪拉丁语),并以此直接输出最终答案。
剖析: 在整个过程中,MemSearcher 的输入始终只有“初始问题”和“上一轮浓缩的 Memory”,无论交互多少轮,被舍弃的网页原文噪音都被清理掉了,记忆始终保持在极短的字数内,思路极其清晰。
方法论与技术实现
1. Agent 迭代记忆整合模型 (Iterative Memory Integration)
在传统的 ReAct 中,第 $i$ 轮的 LLM 输入为 $c_i = (q, t_1, a_1, o_1, \dots, t_{i-1}, a_{i-1}, o_{i-1})$,输入呈线性增长。而在 MemSearcher 中,输入被精简为:
$$c_i = (q, m_{i-1})$$
其中 $q$ 是用户查询,$m_{i-1}$ 是上一轮的浓缩记忆(被 <memory> 包裹)。模型基于此生成思考 $t_i$ 和工具调用 $a_i$。在执行搜索得到庞杂的网页反馈 $o_i$ 后,LLM 读取 $o_i$ 并融合 $m_{i-1}$ 中仍然有用的信息,覆写生成新的紧凑记忆 $m_i$,彻底抛弃原始的网页片段。
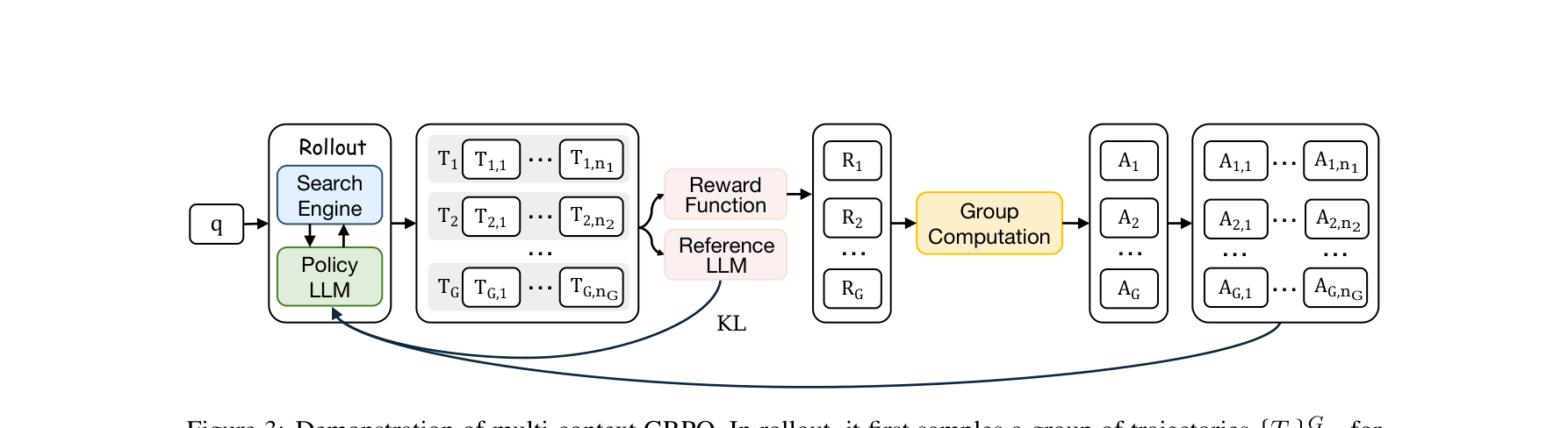
2. Multi-Context GRPO 强化学习
由于 MemSearcher 的设计机制,轨迹(Trajectory)跨越多个回合,而且每一回合的 LLM 感受野(Context)被主动切断且各不相同。为了能够端到端地优化这种模式,作者对 DeepSeek 提出的 GRPO 算法进行了变体改造:
- 首先,对每个查询 $q$ 采样 $G$ 条轨迹。每条轨迹 $T_i$ 包含 $n_i$ 轮次,最终计算轨迹级别的总体奖励 $R_i$。
- 利用组内的均值和标准差计算相对优势(Advantage)$A_i$:
$$A_i = \frac{R_i - \text{mean}(\{R_1, R_2, \cdots, R_G\})}{\text{std}(\{R_1, R_2, \cdots, R_G\})}$$ - 然后,关键步骤是 Advantage 传播:假设该轨迹优势为 $A_i$,则将其平均分配给该轨迹下包含的所有切断状态轮次,即 $A_{i,j} = A_i$。
- 最终优化目标对每个独立轮次最大化策略梯度,并在生成的 Token 上施加 KL 惩罚,过滤掉从搜索引擎抓取的 Token 掩码计算,使得模型稳定收敛于最优“提取和遗忘”策略。
3. 奖励函数设计 (Reward Modeling)
采用了双重硬编码奖励机制:格式奖励(检查 XML tag的正确性,以及 \boxed{} 的存在)与回答奖励(利用 F1 Score 计算 \boxed{} 内部内容与 Ground Truth 的重合度)。这确保了不需要训练专门的 Reward Model 即可驱动 RL 飞轮。
实验设置与结论分析
- 基线对比 (Performance): 作者在基于 Qwen2.5-Instruct 初始化的模型上进行了实验。在 NQ, HotpotQA, TriviaQA 等七个经典复杂 QA 验证集上,MemSearcher 3B 的均分 (43.8) 竟高于其他基线方法的 7B 模型,而 MemSearcher 7B 达到了 48.9 分,超过了基于 32B 参数量的 ReSearch 模型。
- 计算效率 (Efficiency): 追踪 LLM 推理的 Context 消耗发现,相比于 ReAct 系列随轮数急剧飙升至上万 Token,MemSearcher 的平均 Context 消耗始终横向平稳维持在 4K 以内。这意味着在处理包含 10 轮以上的复杂检索任务时,MemSearcher 对计算资源的占用只有同侪的几分之一。
- 消融实验:为什么不能只用 SFT? 文中揭示,如果只用监督微调(SFT)而不是 RL 去训练 Agent 管理记忆,性能会大幅滑坡(以 3B 为例,均分从 43.8 暴降至 28.5)。这说明“保留什么、丢弃什么”这种动态的记忆管理行为,很难通过显式标注的蒸馏数据完美呈现,只能通过 RL 的最终目标回传(探索利用)来内化。
- 记忆长度的影响: 强制截断记忆区长度的消融显示,1024 Token 是一个理想的甜点区。给出的容量太少(如 256)会使模型丢失复杂多跳信息;太多则导致自我冗余并稀释注意力。
关键技术亮点分析
对于 LLM Agent 从业者来说,这篇论文指出了一个极其务实的优化方向:从无脑拼接走向显式的状态更新。
- 从 RNN 汲取灵感的 Prompt Engineering: MemSearcher 相当于在 Prompt 层级手搓了一个 RNN / LSTM 的隐藏状态更新机制。模型不再被动阅读全文,而是主动承担“信息压缩机”的角色。这一范式让超长多跳任务脱离了对无限长 Context 模型的依赖,将内存成本降为 $O(1)$。
- 有效解决环境状态非马尔可夫性的 RL 训练: 通常将一整个交互流切断成各个单独 Context 会让 RL 难以进行(Credit Assignment 问题)。Multi-Context GRPO 通过最朴素的 Trajectory-level 组归一化并进行回合间的 Advantage 平均广播,证明了在生成式任务中,这种简单暴力的优势分配足以驱动 LLM 学会极其复杂的记忆擦写策略。这对未来其他多阶段、分步骤解耦的 Agent 训练有着巨大的参考价值。