Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
通过混合On-Policy与Off-Policy优化的探索型记忆增强LLM Agent
作者:Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, Yuqing Yang
机构:Microsoft Research, KAIST
研究背景与痛点 (Background & Pain Points)
近年来,将强化学习(RL)与大型语言模型(LLM)结合,使Agent能够基于环境反馈自我进化(如 GRPO 算法)已成为重要范式。然而,在复杂的多步具身推理(Embodied Reasoning)任务中,当前基于 RL 训练的 LLM Agent 面临着一个致命瓶颈:探索(Exploration)能力严重不足。
具体而言,面临以下痛点:
- 过度依赖先验知识的“剥削(Exploitation)”:当环境需要发现新状态或规则时(例如需要去别的房间找特定物品),模型往往局限于其预训练的先验分布中“打转”,导致在线 RL 过早收敛到次优解。
- 非参数化记忆的局限性:尽管近期一些研究(如 Reflexion)引入了外部记忆(Long-term memory),让 Agent 通过查阅过往失败的记录来避坑。但这属于非参数化(Non-parametric)更新,模型参数一旦固定,其探索空间往往很快枯竭,难以实现模型内生泛化能力的持续、长期进化。
核心贡献 (Core Contributions)
微软研究院提出了 EMPO² (Exploratory Memory-Augmented On- and Off-Policy Optimization),一种统一的混合强化学习框架,成功打破了“外部提示工程”与“内部参数优化”的次元壁。其主要贡献包括:
- 双重更新机制(Dual-Update Paradigm):将参数化的 RL 策略优化与非参数化的自我反思记忆(Tips)结合。Agent 既能利用记忆作为探索的“脚手架”,又能通过参数更新将这些知识内化。
- 混合 On- / Off-Policy 优化:创新性地设计了混合更新策略。在使用带有记忆的轨迹进行参数更新时,部分数据通过 Off-Policy 的方式去掉了 Prompt 中的记忆部分。这相当于一种奖励引导的知识蒸馏(Reward-guided Knowledge Distillation),迫使无记忆的基础策略去拟合有记忆时的优质探索轨迹。
- 卓越的探索效率与泛化能力:在需要极强探索的 ScienceWorld 和 WebShop 基准测试中,相较于强大的 GRPO 基线,分别实现了 128.6% 和 11.3% 的巨大性能提升。同时,在跨任务 OOD(Out-of-distribution)测试中,展现了极具潜力的 Few-shot 适应能力。
具体案例剖析 (Case Study / Examples)
以下展示在 ScienceWorld 的 <power-component> 任务中,EMPO² 是如何通过记忆增强打破“行为死锁”的:
任务要求: 找到红灯泡,建立电路并点亮它。Agent 初始出生在“走廊(Hallway)”。
[无记忆的 GRPO Agent 行为 - 陷入死循环]
Observation: 房间是走廊,你看到了门、画等。
Action: focus on red bulb (试图聚焦红灯泡)
结果: 任务失败。因为当前房间根本没有红灯泡,由于没有记忆,Agent在后续多次 Rollout 训练中,像无头苍蝇一样重复这条失败指令,分数彻底停滞。
[EMPO² 借助自我生成的 Tips 破局]
在之前的 Trial 中,Agent 同样失败了,但它在当前回合结束时生成了一条总结并存入 Memory Buffer:
"Focus on red light bulb but cannot find it in the hallway... Eventually you got the score -100.0/100."
新的 Rollout (带有记忆增强的 Prompting):
Tips: 检索到了上述失败经验。
Action: go to workshop (前往工作室寻找)
结果: 成功转移房间并在新房间找到了红灯泡,跳出了局部最优,开始进行有意义的探索,随后这些优质轨迹被用于进一步优化策略模型。
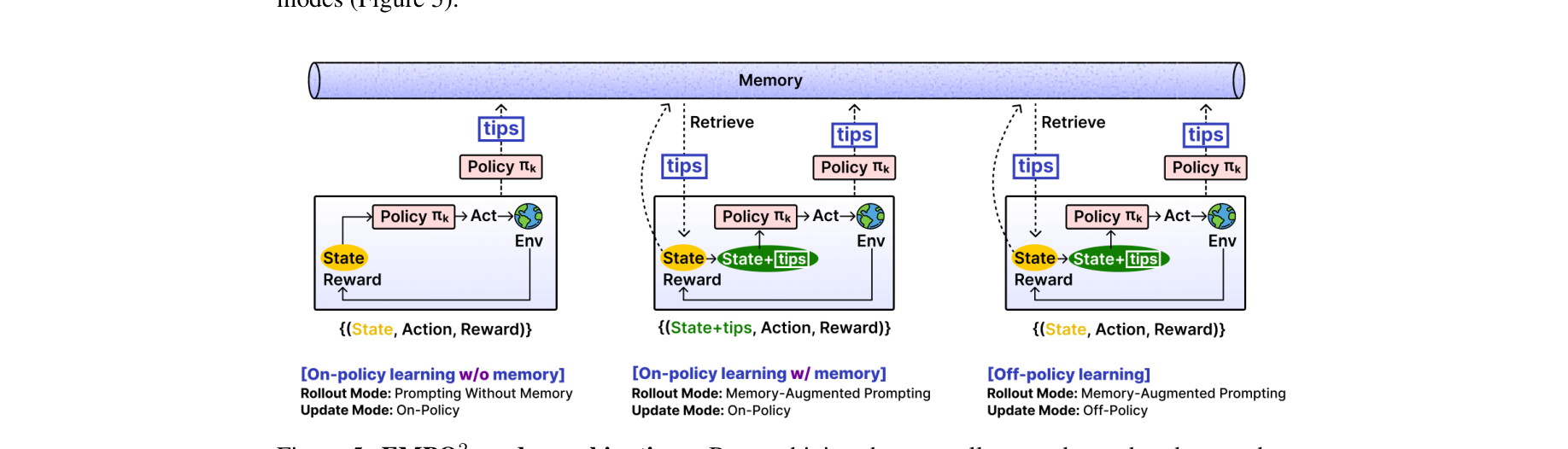
方法论与技术实现 (Methodology)
EMPO² 的核心在于将 Rollout 和 Update 阶段进行解耦,通过不同的条件组合实现“基于记忆的探索”和“剥离记忆的内化”。
1. 采样阶段 (Rollout Modes)
在每次交互生成数据时,Agent 依概率 $p$ 选择是否使用外挂记忆:
- 无记忆采样 (Prompting Without Memory, $1-p$):仅根据当前状态 $s_t$ 和任务 $u$ 采样动作 $a_{t+1} \sim \pi_\theta(\cdot | s_t, u)$。
- 记忆增强采样 (Memory-Augmented Prompting, $p$):通过 Cosine 相似度检索出与当前 $s_t$ 相关的自我反思 Tips(表示为 $\text{tips}_t$)。策略模型基于状态、任务和 Tips 共同条件进行动作采样:$a_{t+1} \sim \pi_\theta(\cdot | s_t, u, \text{tips}_t)$。
2. 更新阶段 (Update Modes) 与知识内化
通过“无记忆采样”获取的轨迹,按标准的 GRPO 直接更新。而通过“记忆增强采样”获取的轨迹,则分为两种情况进行强化学习更新:
- On-Policy Updates (概率 $1-q$):新策略 $\pi_\theta$ 的计算依然保留 $\text{tips}_t$ 条件,重要性采样比率 $\rho_\theta$ 完全对齐。这确保了训练的稳定性。
- Off-Policy Updates (概率 $q$) ⚠️ 核心亮点:用于采样的老策略 $\pi_{\theta_{old}}$ 看到了 Tips,但我们在计算新策略 $\pi_\theta$ 的 Log Probability 时,强制将其中的 $\text{tips}_t$ 去掉(Mask out)。
此时的似然函数变为:$\ell_t^{\text{no-tips}} = \log \pi_\theta(a_t | s_t, u)$。
机制解析: 具有高优势值($A > 0$)的探索动作是被 Tips 引导出来的,但梯度更新强迫当前模型在“没有看到 Tips”的情况下去提高这些高光动作的概率。这等价于利用 RL 优势函数的教师-学生知识蒸馏(Reward-guided Knowledge Distillation),最终模型将摆脱对外部记忆的依赖,原生掌握探索能力。
3. 稳定 Off-Policy 训练的 Masking 机制
由于 Off-Policy 强行去掉了 Tips 导致的分布偏移,极易造成重要性采样比率(Likelihood ratios)无界爆发。为此,作者设计了一个低概率截断的 Masking 机制:当某个 Token 在无提示条件下的生成概率低于阈值 $\delta$ 时,丢弃其 Advantage 带来的梯度更新:
$$ \mathbb{E} \left[ \frac{1}{NT} \sum_{i=1}^N \sum_{t=1}^T \min \left( \rho_\theta^{(i,t)} A(a_t^{(i)}), \text{clip}\left(\rho_\theta^{(i,t)}, 1-\epsilon, 1+\epsilon\right) A(a_t^{(i)}) \right) \cdot \mathbf{1}_{\pi_\theta(a_t^{(i)} | s_t^{(i)}, u) \geq \delta} - \beta D_{\text{KL}}(\dots) \right] $$
此外,为了鼓励长期探索,EMPO² 还结合了基于状态新颖性的内在奖励(Intrinsic Rewards, $r_{\text{intrinsic}} = 1/n$),防止策略早期坍塌到单一的行为模式上。
实验设置与结论分析 (Experiments)
实验配置:基座模型采用 Qwen2.5-7B-Instruct,训练框架基于 verl 进行多步 (multi-step) 和离线损失 (off-policy loss) 计算的改造。对比 Baseline 包括 Naive (直接推理), Reflexion (非参数化记忆 RL), Retrospex (离线 RL), GRPO 及 GiGPO (在线 RL)。
- ScienceWorld 表现:在 19 个跨学科实验任务中,Qwen2.5 基准得分为 -61.3,标准 GRPO 得分为 33.2,而 EMPO² 惊人地达到了 75.9,相较于 GRPO 的提升超过了两倍,甚至在 7 个最初为负分的任务中满分通关。
- WebShop 表现:在一个极其依赖步骤关联的网页端购物环境中,EMPO² (88.3) 同样击败了强在线 RL 算法 GiGPO (86.2) 和 GRPO (79.3)。
- OOD 新任务泛化 (Zero/Few-Shot):这是令人兴奋的一点。将仅在一个任务上训练过的 EMPO² 模型,不更新权重直接放在全新任务上。起初性能平平(Step 0),但当开放其记忆模块并允许其在环境中 Trial & Error 几轮后,其分数呈爆发式增长(10 个 step 内平均提升 136%),证明模型学会了“如何利用记忆去探索”这种高阶的 Meta-ability。
关键技术亮点分析 (Highlights)
- 真正的 Agent 闭环“自主进化”:目前大量的 LLM 训练依赖 GPT-4 生成的 Golden Trajectories 进行 SFT(如 RLAIF 范式)。EMPO² 里的 Tips 完完全全是小模型在不断碰壁中(Trial-and-error)自己总结的,再通过混合 RL 内化,展现了纯净的自我进化(Self-improvement)能力,极具 Scaling 潜力。
- RL中对 Memory 的巧妙抽象(外挂变内生):在 RAG 或 Agent 框架中,“外挂记忆”常常只停留在 Prompt Engineering 层面,治标不治本。EMPO² 的
Off-policy distillation是一步妙棋。把“拿着作弊小抄做对的题目”,转化为了“模型自身的内化肌肉记忆”,使得最终部署时不再需要繁重的 RAG 或长 Prompt,推理效率极高。 - 有效抑制长文本 RL 容易引发的梯度崩溃:Off-policy 在 LLM 中之所以难搞,就在于一两个出入极大的 Token 会让 $\frac{\pi_{new}}{\pi_{old}}$ 爆炸,导致梯度 NaN。EMPO² 在 PPO 的 Clip 上再次加了一层 Hard Mask($\mathbf{1}_{\pi_\theta \geq \delta}$),对工业界做复杂 RL 调优提供了一个极其宝贵的稳定 Trick 方案。