Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning
无需“好答案”也能鼓励“好过程”:面向LLM Agent规划的强化学习
作者: Zhiwei Li, Yong Hu, Wenqing Wang
机构: WeChat, Tencent Inc. (微信/腾讯), Peking University (北京大学)
📄 查看 ArXiv 原文
研究背景与痛点
在当前大语言模型(LLM)Agent 的工作流中,核心能力主要拆分为两个阶段:规划(Planning) (即调用外部工具收集信息的阶段)和总结(Summarization) (即综合信息生成最终回复的阶段)。目前业内主流的 Agent 强化学习训练范式(如最近开源的各类复杂推理模型)通常采用**端到端(End-to-End)的多目标优化**,即将“最终答案的正确性”作为奖励(Reward),同时更新 Planning 和 Summary 策略。
然而,这种高度耦合的端到端范式在工业真实业务场景落地时,面临两个极为棘手的痛点:
痛点一:极度缺乏有效奖励信号(Reward Hacking 与不可验证数据)。 在工业界,拥有确定性“标准答案”(Verifiable data)的查询占比通常极低(约1%),绝大多数(99%)是开放性或难以验证真伪的请求。直接使用 LLM 对这些“不可验证”的最终结果进行打分作为 Reward 极易引发 Reward Hacking(奖励作弊),导致策略劣化。痛点二:信用分配困难(Credit Assignment Difficulty)与优化目标冲突。 在端到端 RL 中,一条轨迹的 Reward 由最后的 Summary 决定。如果 Agent 在中间步骤执行了完美的工具调用(Good Process),但最后由于基座能力的限制导致总结写错了,整个轨迹就会被惩罚;反之,错误的调用碰巧蒙对了答案则会被奖励。这严重阻碍了核心“规划能力”的梯度收敛。
核心贡献
为了解决上述工业界应用难题,微信/腾讯团队提出了一种创新框架:带有工具调用奖励的强化学习 (RLTR, Reinforcement Learning with Tool-use Rewards) ,其核心思想是“重过程,轻结果”。
解耦训练,单目标优化: 彻底打破端到端范式,将 Planner 与 Summarizer 解耦,使得强化学习只专注于优化核心的 Planner(规划模块),有效解决了梯度冲突和信用分配问题。创新奖励机制:工具调用完整性 (Tool-use Completeness): 抛弃对最终回答(Final Answer)的依赖。基于一个洞察:“判断一件事有没有去做,比判断这件事做没做对要容易得多”。该框架设计了专注于评估动作序列完整性的 Reward,不仅信号更加稠密、保真度高,还彻底摆脱了对大规模可验证数据集的依赖。性能提升显著: 实验证明,在不特意训练 Summarizer 的情况下,仅通过 RLTR 强化 Planner 的过程能力,就使核心 Planning 指标提升 8%–12%,并自然带动整个系统的端到端响应准确率提升 5%–6%。
具体案例剖析
论文通过具体 Case Study 展示了 RLTR 奖励机制相较于传统 Answer Reward 的优越性,以及 Planner 优化对最终输出的决定性作用(参见原文 Page 12-13 的 Figure 7):
案例一:当 Agent 学会了“骗”奖励(Reward Hacking)
Query: “计算北京和上海的温差”
Agent 轨迹: Agent 调用了 Search 搜索“北京天气”,获取到了北京温度(16~29℃)。随后,Agent 没有 去搜索上海天气,而是直接基于幻觉(Hallucination)编造了上海温度,并计算给出了一个看似正确的温差数值。
传统终答评估 (Answer Reward): 判定最终回答包含具体数字且“回答了问题”,错误地给出了正向 Reward (1分)。
工具完整性评估 (Tool-Use Completeness): 敏锐捕捉到轨迹中缺失了获取上海天气的 API 调用,直接判定过程“不完整”,给出负向 Reward (0分)。
案例二:优化的 Planner 如何拯救最终结果
Query: “诗集《Moments So Quiet》的作者是谁?”
Unoptimized Planner: 仅仅发起一次搜索,匹配到了一个名为“王宗坤”的作家有类似短篇小说集,便停止调用并直接输出错误结论。
Optimized Planner (RLTR训练后): 发起第一次搜索后,发现存在多义性。其策略被优化为“必须获取充分证据”,因此主动发起了第二次搜索 ,专门查询了澳门诗人“贺绫声”与该诗集的关联。获取到决定性证据后,将完整上下文传给 Summarizer,最终输出了正确答案。
方法论与技术实现
传统范式下,策略 $\pi_e$ 同时生成动作 $a$ 和最终答案 $y$,优化目标高度耦合。RLTR 框架将其解耦,使得 Planner $\pi_p$ 根据查询 $q$ 和历史交互 $\mathcal{H}_t$ 仅负责生成轨迹 $\tau = (s_0, a_0, \dots, s_T, a_T)$。其整体优化目标重定义为:
$$ \pi^*_p = \arg\max_{\pi_p} \mathbb{E}_{\tau \sim \pi_p}[R(\tau)], \quad y = \pi_s(\tau), \text{where} \; \tau \sim \pi^*_p $$
具体的工程实现划分为三个核心阶段:
冷启动 (Cold Start): 利用强大的 Teacher LLM(如 Qwen3-32B)执行知识蒸馏。通过模拟环境生成交互轨迹,并进行拒绝采样(Rejection Sampling),保留 best-of-n 的轨迹,对 Planner 进行监督微调(SFT)。工具调用完整性奖励 (Tool-Use Completeness Calculation):
为了避免对可验证答案的强依赖,定义完整性检查函数 $\gamma: \mathcal{S} \to \{0, 1\}$,由另一个 LLM(Comp. Checker)按特定 Prompt 执行。对生成的轨迹进行 $N$ 次采样取平均:
$$ R_{comp} = \frac{1}{N} \sum_{i=1}^N \gamma_i(\tau) $$
多轮强化学习 (Multi-Turn Reinforcement Learning):
将工具完整性奖励与规则惩罚(重复调用惩罚 $R_{repeat}$、错误调用惩罚 $R_{error}$)结合:
$$ R_{total} = \begin{cases} -1, & \text{if trajectory format is invalid,} \\ R_{comp} + R_{rule}, & \text{otherwise.} \end{cases} $$
利用标准的 RL 目标更新 Planner(支持 PPO/GRPO/REINFORCE++ 等算法):
$$ \pi^*_p = \arg\max_{\pi_p} \mathbb{E}_{x \sim \mathcal{D}, a \sim \pi_p(\cdot|x;\mathcal{T})} [R(x, a)] - \beta \mathbb{D}_{KL} [\pi_\theta(a|x;\mathcal{T}) \| \pi_{\text{ref}}(a|x;\mathcal{T})] $$
训练模板 Trick: 在构建 RL 轨迹时,作者使用 Mask 技术屏蔽了“非动作/非思考”部分的 Loss(例如屏蔽了工具返回的观测结果和最终 summary)。这使得梯度完全聚焦于 Agent 的“决策行为”,防止了梯度信号稀释。
实验设置与结论分析
实验在包含搜索(Search)和代码执行(Code)工具的沙盒环境中进行。模型基座选择了 Qwen3-1.7B 和 Qwen3-8B,基线对比包括直接推断(DIRECT)、端到端SFT(E2E SFT)、端到端RL(E2E RL)。
Planning 核心指标大涨: 在工业数据集的 Hard 类别下,端到端 RL(E2E RL)由于信号稀疏和梯度冲突,往往在深层推理上失效。而在 RLTR 框架下,8B 模型的“完整性”得分从 53.5 飙升至 65.6,1.7B 模型从 45.2 提升至 49.4,体现了强悍的动作探索能力。端到端响应(Match/Helpfulness)自然提升: 在使用未经针对性训练的 LLM 充当 Summarizer 的前提下,因为 Planner 搜集的信息更加充分准确,Agent 的端到端回答准确率提升了 5%~6%。强化学习算法的兼容性: 作者在 PPO、GRPO 和 REINFORCE++ 上都测试了该框架,三种算法均展现出稳定的性能提升。有趣的是,GRPO 的优化逻辑(Group Normalization)使其更倾向于“少次、精准”地调用工具,而 PPO/REINFORCE++ 会通过堆积大量的探索(更多轮次)来获取更高的完整性。奖励模型可靠性对比: 抽查 925 条人工标注数据,Tool-Use Completeness 奖励的 F1 值为 84.64%,远超传统 Answer Reward 的 76.17%,证明了“评估过程”比“评估结果”在现阶段更具鲁棒性。
关键技术亮点分析
这篇论文为大模型 Agent 落地的两个致命瓶颈(可验证数据稀缺、长轨迹 RL 梯度混乱)提供了一个优雅的工程化解决方案。亮点总结如下:
巧妙的转化思路(Shift in perspective): 当前大部分 Agent 的 RL 工作(如 DeepSeek-R1 延伸的相关研究)仍执着于找寻“数学/代码”这类自带客观对错的场景。而本文立足于工业界 99% 的 Unverifiable 场景 ,通过将评估标尺从“答案对不对”转移到“动作完不完整”,开辟了弱监督强化学习的新路。精准绕开 Credit Assignment 陷阱: 在复杂工作流中,如果把生成动作和生成最终文本放在同一个模型的同一次 forward-backward 中优化,必然面临表征空间的拉扯。解耦之后,Planner 的 Loss 和 Reward 完全贴合“工具交互”的特性,模型可以心无旁骛地学习如何当一个好“搜索员/程序员”,而把“发言人”的任务交给后置模块。落地的极高泛化性: RLTR 提出的训练 Template 和 Mask 机制非常轻量级,它不需要专门收集特定的标注数据,可以直接利用现有的 SFT 经验进行冷启动,并通过验证模型快速自举,极大地降低了工业级复杂 Agent 系统(尤其是具备深层搜索、计算需求的 AI 助手)的 RL 对齐成本。
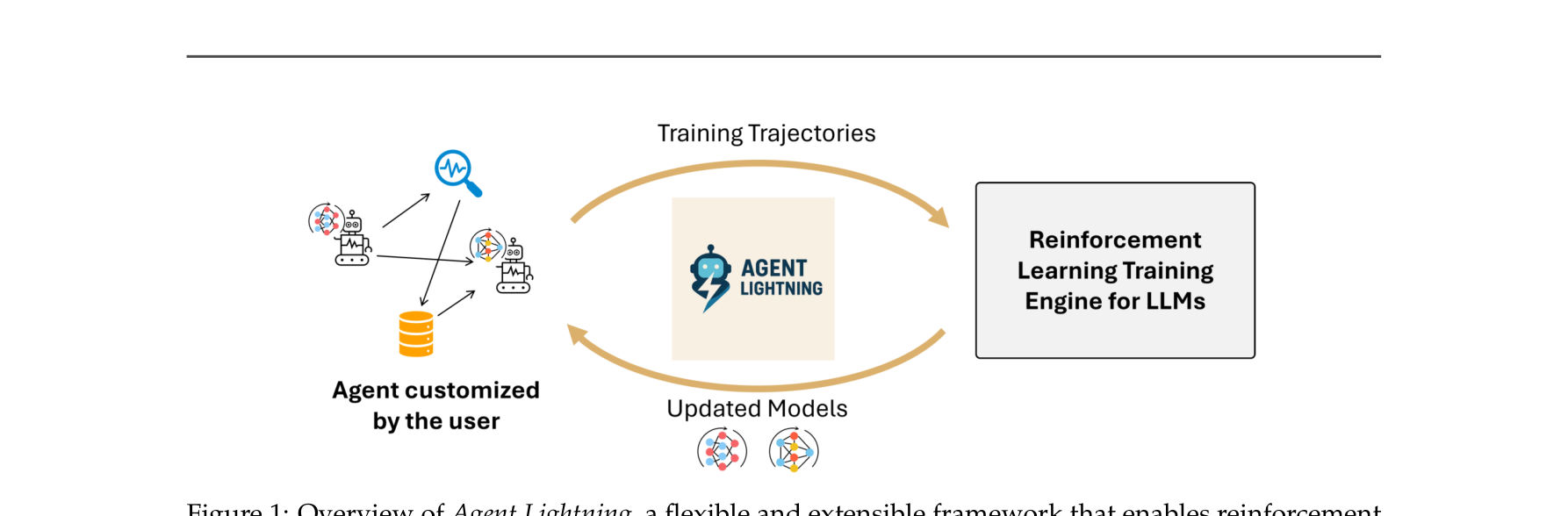
Agent Lightning: Train ANY AI Agents with Reinforcement Learning
中文标题: Agent Lightning:用强化学习训练任意AI Agent
作者: Xufang Luo, Yuge Zhang, Zhiyuan He, 等
机构: Microsoft Research (微软亚洲研究院)
📄 查看 ArXiv 原文
🔍 研究背景与痛点
随着DeepSeek-R1等模型的成功,基于强化学习(RL)提升大模型(LLM)的推理和复杂决策能力成为当前的重中之重。然而,现有的RL训练框架(如verl、TRL、OpenRLHF)主要面向单轮交互(Single-turn) 场景(如数学证明或指令对齐),当扩展到复杂的、需要多轮交互、工具调用甚至多智能体协同的真实AI Agent场景时,面临巨大的系统和算法瓶颈:
训练与执行严重耦合: 现有RL框架往往要求开发者将Agent的执行逻辑(Workflow)硬编码到训练系统的Rollout阶段。真实世界中的Agent通常由LangChain、AutoGen等高度定制化的框架开发,将其移植重写到RL框架中不仅成本高昂,且难以维护。Sequence Concatenation + Masking 的局限性: 为了复用单轮RL算法,现有做法通常将多轮交互的上下文拼接成一个超长序列,并通过极其复杂的Masking策略来区分哪些token参与梯度回传。这种方法不仅大幅增加了Context Length导致显存和计算爆炸,还破坏了模型位置编码(如RoPE)的连续性,且针对不同Agent需定制不同的Mask逻辑,泛化性极差。Reward稀疏且Credit Assignment困难: 多步长决策任务通常只能在最后一步获得稀疏的最终Reward,如何有效地将功劳(Credit)分配到多轮调用中的具体某次LLM生成,是当前算法的痛点。
💡 核心贡献
微软提出了 Agent Lightning ,这是首个实现了 Agent执行与RL训练完全解耦(Complete Decoupling) 的灵活可扩展框架,允许开发者以“近乎零代码修改” 的方式对现有任意Agent进行RL微调:
系统架构解耦 (Training-Agent Disaggregation): 提出将计算密集的LLM训练(Server)与轻量灵活的Agent业务逻辑(Client)彻底分离,通过标准的OpenAI-like API进行通信,兼容任何第三方Agent框架。统一数据接口与MDP建模: 将复杂的Agent执行抽象为马尔可夫决策过程(MDP),无需解析复杂的有向无环图(DAG),只需提取每次LLM调用的(输入状态, 输出动作, 奖励)三元组(Transition)。分层强化学习算法 (LightningRL): 摒弃了低效的长序列拼接与Masking。通过Credit Assignment将Episode级别的Reward分配到每个Transition,直接将其转化为单轮数据形式,无缝复用现有的免价值函数RL算法(如GRPO、REINFORCE++)。强大的Agent Runtime观测性: 整合OpenTelemetry等观测性基础设施,实现Agent轨迹的无侵入式采集,并支持自动中间奖励(AIR)机制缓解Reward稀疏问题。
🛠️ 具体案例剖析 (Case Study)
为了直观展示 Agent Lightning 如何将复杂工作流转换为 RL 数据集,论文给出了一个典型的 Retrieval-Augmented Generation (RAG) 多轮交互Agent的执行流程(基于OpenAI Agents SDK开发,执行基于维基百科的MuSiQue数据集问答):
Agent Workflow 拆解与变量追踪:
Turn 1 - 检索意图生成:
Input/State: 用户输入问题 UserInput: "xxx"。Action/LLM Call 1: 策略模型(待优化LLM)根据输入生成搜索查询 Query = "xxx"。Environment: 外部搜索工具 (Search Tool) 获取Query,返回文档片段 Passages。此步骤仅为环境反馈,无策略模型梯度。
Turn 2 - 答案生成与汇总:
Input/State: 此时系统的状态不仅包含初始的 UserInput,还融合了 Passages,以此作为 LLM 的新上下文。Action/LLM Call 2: 策略模型基于上述综合上下文,生成最终答案 Answer。Reward: 基于生成的 Answer,计算最终的任务级奖励 $R$(如 F1-Score)。
传统框架做法: 将上述所有 Prompt、Query、工具调用记录、Passages、Answer 拼接为一个长达数千Token的超长序列,通过精细计算Mask,仅对 Query 和 Answer 计算 Loss。
Agent Lightning 做法: 提取并分解出两条独立的 Transition:(Input = Prompt1 + UserInput, Output = Query, Reward = R)(Input = Prompt2 + Passages, Output = Answer, Reward = R)
图注:Agent Lightning 框架概览图。展示了用户定制的Agent(左侧,涵盖不同的逻辑、外部工具调用和数据源)如何通过高度解耦的接口,将轨迹数据(Trajectories)自动提取并输入到强化学习引擎中(右侧),形成“模型更新->Agent能力提升”的闭环迭代。 ⚙️ 方法论与技术实现
1. 基于MDP的Agent状态转移抽象
将待优化的 LLM(参数 $\theta$)视为 Policy,Agent框架的每次执行视为部分可观测马尔可夫决策过程 (POMDP)。在时刻 $t$,系统捕获语义变量形成上下文 input_t。LLM生成一个Token序列 output_t 作为动作 $a_t$。每次完整执行(Execution)可抽象为:
$$ execution^{RL}(x, k) = \{ (\text{input}^{x,k}_t, \text{output}^{x,k}_t, r^{x,k}_t) \}_{t=1}^T $$
2. LightningRL 算法
由于LLM往往是以自回归形式逐Token生成的,而Agent侧的交互是以单次完整Call为粒度。LightningRL 采用分层强化学习 (HRL) 范式连接两者:
Credit Assignment 模块: 将整条轨迹的最终 Reward $R$ 合理分配给各个中间生成的动作 $a_t$。(当前版本采用简单的均等分配策略:将最终的返回 $R$ 赋给该Episode内的所有有效调用)。优势函数估计(Advantage Estimation): 将分离出来的各个 (input, output) 视为单次交互样本,直接应用 GRPO / PPO 的数学公式计算 Token-level 的优势 $A_j$ 并优化目标:
$$ \mathcal{L}(\theta) = -\mathbb{E}_{x \sim \mathcal{X}, \text{output} \sim \pi_\theta(\cdot|x)} \left[ \sum_{j=1}^N \log \pi_\theta(y_j|x, y_{
3. Training-Agent Disaggregation 分离架构
为解决训练态与执行态的资源错配与工程耦合,系统划分为 Server 和 Client :
Lightning Server: 驻留在带GPU集群的训练侧(整合了VeRL等底层框架),充当整个系统的调度中枢。它给 Client 下发任务 Batch,并暴露一个类似 OpenAI 的 Endpoint 用于接收 Client 在 Rollout 时产生的响应和 Traces。Lightning Client: 部署在 Agent Runtime 环境中(可分布式横向扩展)。利用 OpenTelemetry 无缝监控已有的 LangChain/AutoGen 代码,捕获 LLM 调用的 Input/Output 闭环,完成 Data Capture without Code Modification。
📊 实验设置与结论分析
为了证明框架通用性,论文选用了3个差异巨大的Agent任务(基座模型统一为 Llama-3.2-3B-Instruct):
Text-to-SQL (LangChain, Spider数据): 这是一个3个智能体协同的系统(Writer, Executor, Checker)。实验证明,LightningRL能选择性地对多智能体系统中的部分Agent(Writer和Checker)同时进行联合策略强化。Open-domain QA (OpenAI SDK, MuSiQue数据): 依赖维基百科全文检索的高难度RAG,需要 LLM 自发决定何时停止检索并回答。实验显示不仅 Reward 稳步上升,且正确率大幅跃升。Math QA (AutoGen, Calc-X数据): 极度依赖外部计算器工具(Calculator)准确调用的数学推理场景。验证了框架在函数调用/工具集成学习上的可靠性。
结论: 所有的Reward曲线都展现出稳定且持续的上升趋势,彻底验证了通过离散 Transition 代替长序列拼接这一范式的正确性和训练稳定性。
🌟 关键技术亮点分析 (Takeaways for LLM Practitioners)
直击落地痛点: 对于工业界而言,用RL做Agent的对齐一直是个脏活累活,大家苦于“怎么把复杂的LangChain逻辑塞进PPO框架里”。Agent Lightning 的 Client-Server 架构优雅地解耦了算力密集(Trainer)与逻辑密集(Agent)的模块。这种 RPC 风格的微服务架构是做大规模 Agent 微调的必经之路。打破 Sequence Masking 的“迷信”: 过去社区一直认为要保持完整的 KV-Cache 和绝对位置编码,必须把历史 Interaction 全部塞进一条巨长的 Context 中并做复杂的 Loss Masking。本文证明了在 MDP 假设下,截断上下文为独立 Transition 不仅完全可行,更能极大程度节约长序列注意力计算(Quadratic Cost),显著提升训练 Throughput。对 MARL (Multi-Agent RL) 极度友好: 由于 Transition 被打散,系统可以非常容易地通过筛选 Component ID,只针对系统中特定的“思考型 Agent”回传梯度,而冻结“总结型 Agent”或外部大模型,这种灵活性是传统框架难以企及的。
基于大语言模型的深度搜索智能体综述:范式、优化、评估与挑战
A Survey of LLM-based Deep Search Agents: Paradigm, Optimization, Evaluation, and Challenges
👥 作者: Yunjia Xi, Jianghao Lin, Yongzhao Xiao, Zheli Zhou, Rong Shan, Te Gao, Jiachen Zhu, Weiwen Liu, Yong Yu, Weinan Zhang
🏛️ 机构: 上海交通大学,中南大学
🔗 链接: 📄 查看 ArXiv 原文
🔍 研究背景与痛点
近年来,大语言模型(LLMs)的出现彻底改变了信息检索范式。从最初依赖用户手动筛选信息的传统网页搜索 (Traditional Web Search) ,发展到现今广泛使用的LLM增强搜索 (LLM-enhanced Search, 如传统的 RAG) ,即通过LLM进行单轮的 Query Rewriting(查询重写)或摘要总结。然而,这种结合往往是静态 的:模型高度依赖单轮检索或预设规则,缺乏主动探索能力,面对长尾知识、复杂逻辑或需要多步推理的动态上下文时显得捉襟见肘。
在此背景下,搜索智能体 (Search Agents) 应运而生。它标志着从“被动信息聚合”向“主动、深度、动态的自主信息搜寻”的关键转变。典型的代表如 OpenAI 的 Deep Research、Google Gemini、Perplexity 等,它们能够自主理解用户意图和环境上下文,执行多轮动态检索,不仅局限于互联网,还能深挖私有数据库和智能体内部记忆。然而,目前学术界和工业界对 Search Agents 的架构、优化路径及评估体系尚未有一个全局且系统性的梳理,这正是本篇综述试图解决的核心痛点。
💡 核心贡献
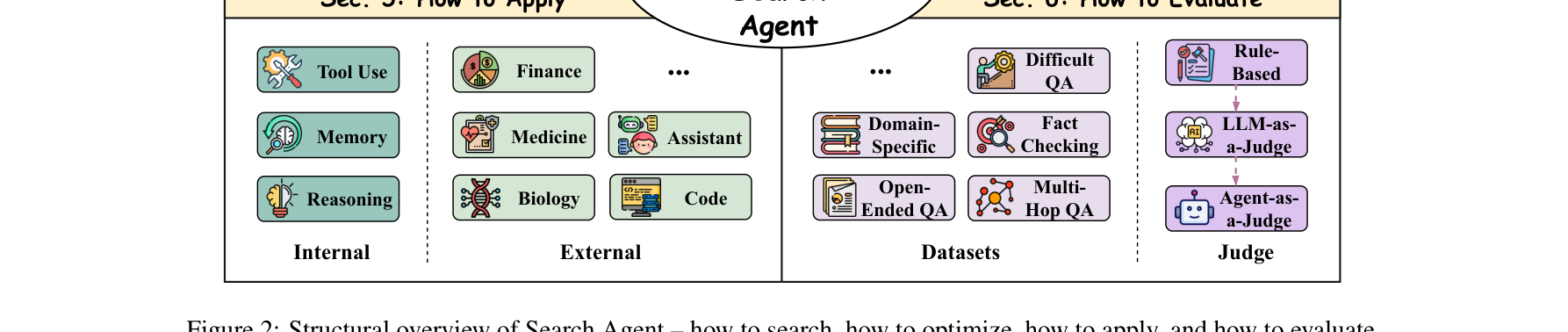
首次提出 Search Agents 的系统性分类框架: 将 Search Agents 的研究划分为四个核心维度:如何搜索 (How to Search) 、如何优化 (How to Optimize) 、如何应用 (How to Apply) 和 如何评估 (How to Evaluate) 。系统梳理了前沿优化策略: 深度对比了 Tuning-Free(如 Test-Time Scaling、多智能体协作)与 Tuning-based(如 SFT、定制化 RL 与 PRM 奖励函数)的最新技术路线。构建了全面的评估与应用图谱: 整理了当前针对 Deep Research、Fact-checking、多跳 QA 乃至各垂直领域(金融、医疗、代码)的 Benchmark 及评测范式(如 LLM/Agent-as-a-Judge)。指明了未来关键挑战: 从多模态搜索、不完美检索的信息核实、定制化 RL 到智能体的自我进化(Self-Evolution)指出了极具潜力的研究方向,并维护了一个持续更新的开源代码库。
🎯 具体案例剖析:Deep Research 的执行轨迹
为了直观理解 Search Agent 的运作模式,我们可以将其形式化为一个马尔可夫决策过程(MDP)。假设用户输入一个高度复杂的意图 $q$ 及其上下文 $C$(例如:“分析近三年生成式AI在药物研发领域的商业化进展及最新监管政策”)。
Plan (初始规划): Agent 根据 $q$ 初始化搜索策略 $\pi_0 = \text{Plan}(q, C)$,例如将其分解为“AI药物研发商业化现状”与“FDA最新AI医疗监管政策”。Act & Observe (执行与观察): 在步骤 $t$,Agent 执行动作 $a_{t+1} = \text{Act}(\pi_{t+1})$(如在特定领域数据库搜索或调用浏览器)。环境返回观察结果 $o_t$(如检索到的数篇网页长文)。Reflect (反思与动态调整): 这是与传统 RAG 最大的区别。Agent 阅读 $o_t$ 后,结合历史轨迹 $h_t$,评估当前信息是否充分或存在矛盾,并动态更新下一步计划 $\pi_{t+1} = \text{Reflect}(o_t, h_t, \pi_t)$。Select & Generate (综合生成): 经过多次迭代,直到获取充足信息,Agent 提取核心证据集 $E = \text{Select}(q, O)$,并最终输出符合用户意图的高质量研究报告 $\hat{y}_q = \text{Generate}(q, E)$。
图注:Search Agent 的全景结构概览:涵盖了如何搜索(搜索范式)、如何优化(Tuning/Tuning-free)、如何应用(内部/外部环境)以及如何评估(数据集与判别方法)。 🛠️ 方法论与技术实现
论文将当前构建 Search Agent 的技术栈拆解为“搜索结构”与“优化方法”两大核心支柱:
1. 如何构建搜索策略 (How to Search)
Parallel Structure (并行结构): 主要应对复杂意图的分解(Decomposition)与搜索关键词的多样化(Diversification)。通过生成多个子查询同步执行,增加检索覆盖面。Sequential Structure (序列结构): 更具动态性。基于反思驱动(Reflection-Driven,搜索->生成->反思->再搜索)或主动性驱动(Proactivity-Driven,Agent自主决定何时触发检索及搜什么)。Hybrid Structure (混合结构): 结合并行与序列的优势,典型的如基于树的搜索(Tree-based Search) ,在每个节点并行扩展多条查询路径,并结合蒙特卡洛树搜索(MCTS)进行剪枝与最终答案合成;以及基于图的搜索(Graph-based Search) ,允许状态回溯。
2. 如何优化 Agent (How to Optimize)
无微调方法 (Tuning-Free):
Multi-Agent 架构: 将复杂流程解耦为规划者 (Planner)、检索者 (Searcher)、验证者 (Evaluator) 等专业 Agent,通过中心化调度或固定流水线协作。Test-Time Scaling (推理期计算扩展): 对齐 OpenAI o1 模型的思路。由于 Search Agent 与外部环境交互,不仅涉及内部逻辑的 Reasoning-centric scaling ,还涉及增加外部探测次数的 Search-centric scaling ,两者结合能显著提升深度信息的挖掘质量。
微调方法 (Tuning-based):
SFT (监督微调): 核心在于高质量轨迹数据(Trajectories)的构造。通常通过强模型(Teacher LLM)加 Rejection Sampling 构建正向样本,用于模型的自我改进或作为后续 RL 的热身阶段。RL (强化学习): 业界前沿正全面拥抱端到端 RL(如 PPO, GRPO, Reinforce++)。难点在于多目标奖励函数(Multi-objective Reward) 的设计:除了格式服从和答案正确性外,还需引入检索增益、信息多样性、冗余步数惩罚等指标。特别是针对长轨迹的 过程奖励模型 (PRM, Process-based Reward Models) ,对每一步搜索与反思进行精细化打分,已成为提升搜索智能体天花板的关键。
📊 评估体系与现状分析
对于 Search Agent,传统的单轮 QA 评估显然已失效,目前的评估体系正向以下维度演进:
数据集设计 (Datasets): 从传统的闭卷/单步 QA 演变为:多跳 QA (Multi-hop QA) (需融合多源信息)、挑战性 QA (长尾知识、长程干扰项)、事实核查 (Fact-checking) ,以及针对 Deep Research 的开放式研究数据集 (缺乏唯一正确答案,需输出长文报告)。评判指标与裁判 (Metrics & Judgment):
闭源确定性任务沿用 EM (Exact Match)、F1 等,并在动态环境中考察中间轨迹的 Retrieval Recall 等。
开放域深度研究则高度依赖多维定性指标(如信息广度/深度、条理性、引用准确度)。
裁判模型经历了从 Rule-based 到 LLM-as-a-Judge ,甚至开始流行 Agent-as-a-Judge (使用专门配备工具和搜索能力的 Agent 来评估另一个 Search Agent 的长期轨迹与报告质量)。
🚀 资深从业者视角:核心挑战与未来破局点
尽管学术界与 OpenAI/Perplexity 等工业界产品在 Search Agent 取得了巨大进展,但论文指出的几个方向也是目前研发面临的核心壁垒:
从纯文本向多模态迈进 (From Text to Multi-Modality): 真实的搜索环境是网页、PDF、图片、视频交织的。下一代 Agent 必须能基于图像生成查询动作,或在反思环节 (Reflect) 综合处理跨模态观测(Observations)。不完美检索下的鲁棒性 (Imperfect Retrieval): 现实中的外部知识库充满了噪音、偏见甚至事实冲突。Search Agent 急需强化自身的“批判性质疑能力(Skepticism)”,不仅是检索,而是具备跨源比对与去伪存真的事实核查机制。定制化强化学习 (Customized RL for Search): 传统的 RL 框架面对长周期搜索任务时存在奖励稀疏、知识边界模糊的问题。对于 Open-ended 任务(没有标准答案),如何定义并训练鲁棒的 PRM 和 ORM 奖励模型,将是拉开各家大厂 Deep Research 能力差距的核心技术。智能体的自我进化 (Self-Evolution): 终极的 Search Agent 应该能够通过在环境中持续交互,自主发现其搜索策略的局限性,自发生成修正假设,实现无人类干预的策略迭代,迈向更高级别的 AGI 探索能力。
WebAgent-R1:通过端到端多轮强化学习训练网页代理
英文标题: WEBAGENT-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
作者团队: Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang 等
研究机构: University of Virginia, Amazon, Georgia Institute of Technology
📄 查看 ArXiv 原文
研究背景与痛点
尽管强化学习(RL)在提升大语言模型(LLMs)能力方面取得了巨大成功(如近期引起轰动的 DeepSeek-R1),但现有应用绝大多数仍局限于单轮(Single-turn)、非交互式 的任务,例如数学推理和代码生成。对于需要长视野(long-horizon)决策和持续动态交互的网页代理(Web Agents),RL 的潜力远未被充分挖掘。
当前业界训练 LLM-based Web Agent 面临以下核心痛点:
SFT 的局限性: 目前最主流的方法是基于 Prompting 或行为克隆(Behavior Cloning, BC)的监督微调(SFT)。但这种方式缺乏试错(Trial-and-Error)机制,导致模型只会死板模仿,无法在动态网页中探索多样化策略,泛化性不足。现有 RL 方法过于复杂: 近期的 Web Agent RL 方案(如 WebRL、DigiRL)大多依赖异策略(Off-policy)离线 RL 或迭代优化。这种非端到端的方式不仅需要维护重放缓冲区(Replay Buffer)、过滤过期轨迹,还需要训练额外的外部结果奖励模型(Outcome Reward Model),部署门槛极高,且易因环境陈旧状态引入假阳性奖励。
核心贡献
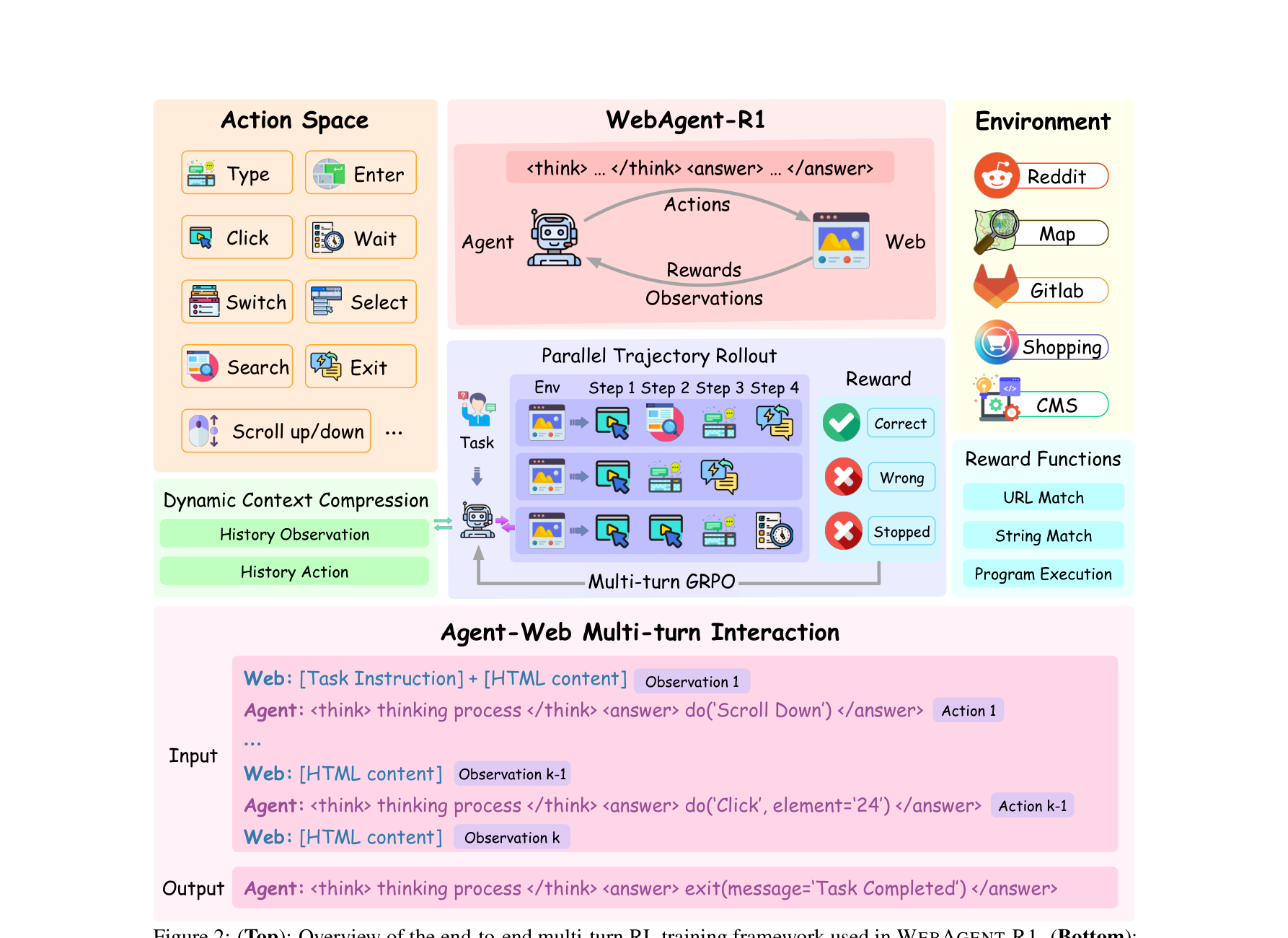
为了解决上述痛点,本文提出了 WebAgent-R1 ,一个极简且高效的端到端多轮强化学习框架:
提出了真正的端到端多轮 RL 范式: 无需复杂的 Off-policy 数据清洗和额外的 Reward Model,纯靠与环境在线交互并依赖规则级成功指标(Rule-based binary reward)即可完成闭环。引入两大工程机制: 针对网页 DOM 动辄上万 Token 导致的 OOM 问题,提出了动态上下文压缩(Dynamic Context Compression) ;为了提高 M-GRPO 的采样效率,实现了并行轨迹展开(Parallel Trajectory Rollout) 。刷新多轮交互 SOTA: 在 WebArena-Lite 严苛测评下,Qwen-2.5-3B 成功率从 6.1% 暴涨至 33.9%,Llama-3.1-8B 从 8.5% 飙升至 44.8%,在同量级模型中形成代差优势,并显著超越闭源模型 OpenAI o3。深入消融实验与洞见: 探讨了纯 RL(Zero)、长思考微调(Long-CoT)对冷启动的影响,并揭示了多轮 Web Agent 在 Test-time Scaling 上的独特表现——即“通过增加交互轮数来换取成功率”。
具体案例剖析
论文对 R1(标准版)和 R1-CoT(基于长思考链预微调版)的决策轨迹进行了对比,任务目标是:"What are the top-3 best-selling products in Jan 2023?" (2023年1月销量排名前三的产品是什么?)
在 Step 2 阶段,需要代理在页面上准确点击报告,两者的输出截然不同:
WebAgent-R1: (简练直接)<think> # Element: the 'Bestsellers' report option under the 'Products' section in the 'REPORTS' </think><answer> do(action="Click", element="27") </answer>
WebAgent-R1-CoT: (极度冗长,模拟深层逻辑)<think> Alright, let's break down my thought process here. The user wants the top-3 best-selling products for January 2023. I previously clicked the "Reports" menu (element 7) to access analytical sections. Now, analyzing the current HTML structure: 1. **Locating the Reports Hierarchy**: The Reports section's dropdown... 2. **Identifying the Target Element**: The element with id="27" is explicitly labeled 'Bestsellers'... 3. **Ruling Out Distractors**: Other options like "Orders" or "Tax"... don't specifically target product performance. 4. **Next Step Justification**... **Decision**: Proceed to click element 27... </think><answer> do(action="Click", element="27") </answer>
从业者视角: 虽然 R1-CoT 展现了令人惊艳的自我独白(如同 DeepSeek-R1 的输出风格),但后续实验数据却揭示了一个反常识现象:极其冗长的显式 CoT 模板反而可能限制 RL 在多轮复杂任务中的探索多样性,简单的 SFT 启动往往能在 RL 中取得更高上限。
图注:WebAgent-R1 端到端多轮 RL 架构概览。包含动态上下文压缩、并行轨迹采样(Parallel Rollout)以及基于多轮交互的 M-GRPO 优化回路。
方法论与技术实现
模型将 Web 导航任务形式化为一个部分可观察的马尔可夫决策过程 (POMDP) $\mathcal{(S, A, T, R)}$。实现端到端训练分为了两个关键阶段和三大组件:
1. 阶段一:Behavior Cloning(行为克隆热身)
完全放弃从随机初始化或通用 Base 模型做 RL。使用专家演示数据集 $\mathcal{D} = \{(h_t, a_t)\}$ 进行 SFT:
$$\mathcal{L}_{BC} = - \mathbb{E}_{(h_t, a_t) \sim \mathcal{D}} [\log \pi_{\theta} (a_t \mid h_t)]$$
这一步是后续 RL 能否存活的绝对关键,否则在极大的 DOM 动作空间中,模型根本无法拿到正向 Reward。
2. 阶段二:End-to-End Multi-Turn RL 优化
Dynamic Context Compression(动态上下文压缩):
在多轮对话中,如果不断 append HTML 源码,Token 很快会达到几万。作者采取的做法是:维护历史互动栈 $h_{t+1} = (s'_1, a_1, s'_2, a_2, \dots, s'_t, a_t, s_{t+1})$。只有当前最新观察帧 $s_{t+1}$ 是完整 HTML,之前的 $s_i$ 会被极度压缩为简明占位符(如 "Simplified HTML"),仅保留过去的行动 $a_i$。在实现 M-GRPO 优化时,只对 action token 进行 loss 掩码计算。
Multi-turn GRPO (M-GRPO):
将近期的 GRPO 扩展为支持多轮的轨迹。对于任务 $q$,并行采样一组轨迹 $\{\tau_1, \tau_2, \dots, \tau_G\}$,每个轨迹有其包含的 action 序列 $a_{i,j}$。
$$\mathcal{L}_{\text{M-GRPO}}(\theta) = - \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\tau_i|} \sum_{j=1}^{|\tau_i|} \left( \frac{1}{|a_{i,j}|} \sum_{t=1}^{|a_{i,j}|} \left[ \tilde{A}_{i,j,t} - \beta D_{KL}(\theta) \right] \right)$$
这里的 $\tilde{A}_{i,j,t}$ 是通过轨迹级别的最终规则评分(Rule-based binary outcome)算出的组相对优势(Group Relative Advantage)。纯粹的二值 0/1 Reward(比如任务是否达成了正确的最终 URL),舍弃了中间态 Reward Model。
Parallel Trajectory Rollout(并行展开):
为了计算组相对优势,作者通过实例化多个独立的无头浏览器实例(包含各自的 Context, Cookies),从同一个起点独立地与环境在线交互,从而高效地生成多个有差异的轨迹用于 M-GRPO 优化。
实验设置与结论分析
模型评测在高度拟真的 WebArena-Lite 基准上进行。环境包含 Reddit、GitLab、CMS、Map 商业等全链路 Web 任务。评价纯依赖内置规则脚本检测。
主干战绩: 在 Llama-3.1-8B 上,SFT(行为克隆)取得了 20.6% 的基线,而经过 M-GRPO 优化的 WebAgent-R1 高达 44.8% ,相比 WebRL (42.4%, 依赖复杂架构和 GPT-4 数据辅助) 更高,且大幅超越目前地表最强推理模型 OpenAI o3(39.4%)。Ablation - RL 极度依赖行为克隆基底: 如果剥离 BC 阶段,直接让纯模型(即使具有极高智商)去做 Zero-shot RL,成功率仅为 6.1%,训练后甚至出现倒退(4.8%)。这是因为网页环境动作容错极低,乱点基本吃不到 Reward。Ablation - 长 CoT 带来更深困境?: 团队利用 QwQ-32B 蒸馏出长逻辑 CoT 数据来重新进行 BC (得到 WebAgent-R1-CoT)。虽然这使得模型在 SFT 阶段提高了起步能力(24.5% vs 20.0%),但一旦套用后续 RL 训练,R1-CoT 仅能提升到 30.3%,被没有用 CoT SFT 的标准 WebAgent-R1 (33.9%) 反超。推论: 过早固化的确定性长推理模板,极大程度地破坏了模型在 RL 阶段的多样性探索能力。Test-Time Scaling:多轮交互就是 Web 领域的 Scaling Law。 在单轮数学题中,Test-time Scaling 表现在模型想得越长越准;而在 Web Agent 中,图 5 明确展示出:随着允许 Agent 环境交互回合数的增加(Max Interactions 从 5 放宽到 30),任务成功率持续提升 。让 Agent 在环境中不断地碰壁、后退(Go Back)再尝试,是提升性能最有效的策略。
关键技术亮点分析
作为资深从业者,这篇论文揭示了 Agentic 领域几个非常重要的发展信号:
"Less is More" 的奖励设计哲学: 前几代 Web Agent 为了缓解探索难度,不惜引入 GPT-4 作为中间步骤打分器(Outcome Reward Model)。本文证明,只要保证了基础的 BC 冷启动,**单纯基于 0/1 的 Final Reward 加上 On-policy M-GRPO**,反而能压榨出 Agent 最高的性能上限,也避免了 Reward Hacking。拒绝 Off-policy 带来的架构膨胀: 异策略 RL(如 PPO+Replay Buffer 或者离线 DPO 迭代)在网页这类强相关性状态(比如账号登录后才能修改头像)的环境中,极其容易因为采样到的环境过期(Agent用旧权重产生了已无法复现的环境)而崩盘。采用极致简化的 On-policy 边采边训,正在成为解决强交互环境的最优解。破除了迷信 Long-CoT: "加长 CoT 一定好"在数学域成立,但在决策空间开放的域内,蒸馏来的冗长伪思考可能成为 RL 的毒药(扼杀了行为熵)。给它一个基础能力范式,然后完全抛给纯粹的强化学习去 Trial-and-error,才是通往更泛化智能的正道。
Towards Scientific Intelligence: A Survey of LLM-based Scientific Agents
中文标题: 迈向科学智能:基于LLM的科学智能体综述
作者: Shuo Ren, Can Xie, Pu Jian, Zhenjiang Ren, Chunlin Leng, Jiajun Zhang
机构: 中科院自动化研究所 多模态人工智能系统全国重点实验室 (CAS)、中国科学院大学等
📄 查看 ArXiv 原文
🔬 研究背景与痛点 (Background & Problem Statement)
随着现代科学研究的复杂性呈指数级增长,科研人员需要处理海量异构数据、进行跨学科协作并加速实验迭代。虽然通用大语言模型(如 GPT-4、Claude)在文本生成和通用对话中表现出色,但当它们被直接应用于严谨的科学发现(Scientific Discovery) 时,暴露出显著的局限性。
领域知识壁垒与幻觉风险: 通用 LLM 缺乏针对特定学科(如量子化学、分子生物学)的深度预训练,容易在生成假设或化学反应路径时产生“看似合理但违背物理定律”的幻觉。操作空间(Action Space)受限: 科学研究不仅需要“动嘴”,还需要“动手”。通用 Agent 的工具箱通常局限于网络搜索或基础代码执行,无法与专业的科学模拟器(如 VASP, LAMMPS)或高通量自动化实验室硬件(Self-driving Labs)深度集成。缺乏严谨的验证闭环: 科学方法论的核心在于“可证伪性”与“可重复性”。通用 Agent 往往缺乏系统的假设检验、多智能体同行评审(Peer Review)和物理/化学引擎验证机制。
因此,亟需将通用 LLM 进化为领域专用的科学智能体(Scientific Agents) 。本篇综述首次跳出了按“应用场景”分类的传统视角,独创性地从底层机制(Mechanism-centric) 出发,对 LLM 科学智能体的架构设计进行了全面且深度的解构。
💡 核心贡献 (Core Contributions)
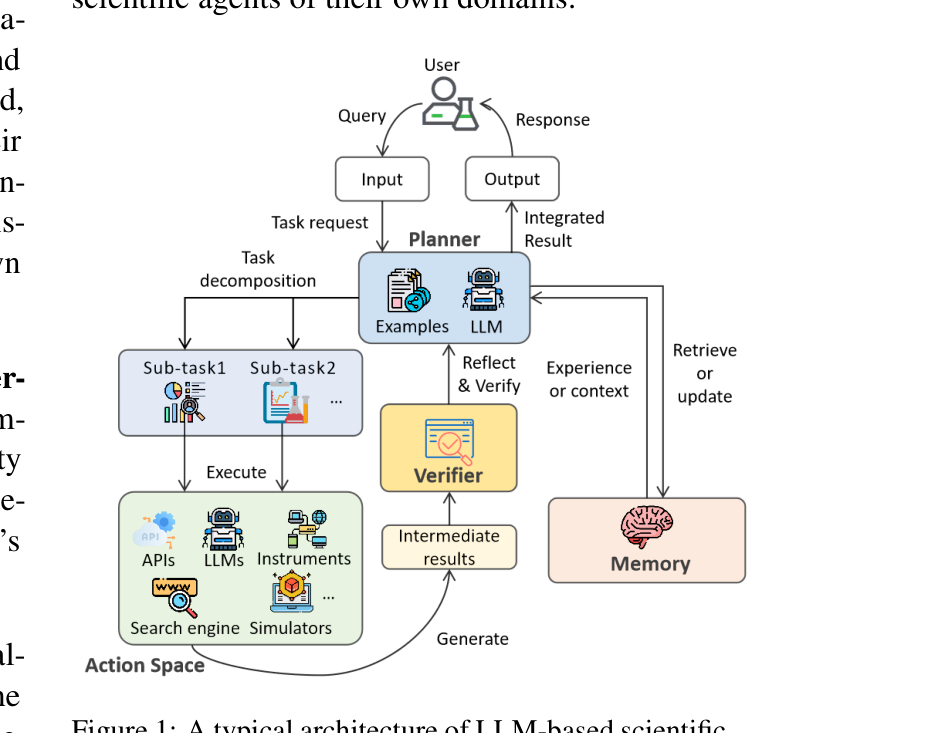
构建了以“机制为导向”的分类法(Mechanism-oriented Taxonomy): 将科学智能体解构为四个核心模块——Planner(规划器)、Memory(记忆)、Action Space(动作空间)和 Verifier(验证器),揭示了其区别于通用智能体的本质特征。提供模块化的“组装蓝图”(Component-wise Blueprint): 将每个核心模块进一步细化为多个子类型(如将 Planner 分为提示原生 P1-P6 与参数学习 L1-L2),并贯穿了一个“锂离子电池正极材料设计”的端到端案例,为从业者提供了清晰的工程落地指南。全面的文献与基准测试图谱: 梳理了超过 120 篇代表性论文和 40 多个领域基准测试(Benchmarks),按照机制和应用领域(化学/材料、生物医学、物理/天文等)进行了细粒度映射。将伦理与可重复性内化为设计约束: 强调在架构设计阶段(尤其是 Verifier 模块)就必须引入护栏机制(Guardrails)、溯源日志与人类监督(HITL),以确保科研的严谨性与伦理性。
🔍 具体案例剖析 (Case Study: 锂离子电池正极材料设计)
为了直观展示四大模块如何协同工作,论文通篇使用了一个极具代表性的材料科学案例。以下是该 Scientific Agent 的完整执行流:
Input (科研目标): "设计并合成一种用于锂离子电池的高容量正极材料(要求:>200 mAh/g,且在 500 次循环以上保持稳定)。" Step 1 - Planner (规划分解): Agent 将高维目标分解为结构化工作流:1. 晶体结构设计 -> 2. DFT (密度泛函理论) 筛选 -> 3. 合成路径规划 -> 4. 电化学测试。Step 2 - Memory (背景增强):
外部知识 (External KB): 检索到最新文献,明确目标电导率需要 σ >1000 mS/cm。历史上下文 (Historical Context): 调取早期失败记录:“NMC811 在 400 次循环后容量衰减,主要因为锰溶解;LFP 稳定但容量仅为 160 mAh/g。”
Step 3 - Action (执行操作): Agent 提出新结构:“富锂氧化物”。随后调用 Python/DSL 代码 生成计算脚本,调用 VASP 模拟器 (Simulator) 计算该材料的反应能垒(ΔE)和循环寿命。Step 4 - Verifier (严谨验证):
多智能体批判 (Multi-Agent Critique): 安全专家 Agent 发现该设计存在 O2 释放风险,成本专家 Agent 提示 Co 元素超标。工具验证 (Tool-based Validation): 模拟器返回结果显示循环次数仅为 480 次,未达标。
Step 5 - Self-Correction (重规划): 基于反馈,Agent 修正设计思路:引入 Mg 掺杂 + Al2O3 表面涂层,重新走计算与验证流程,最终通过所有验证。Output (最终方案): 输出包含完整微观结构、DFT计算支持数据、安全评估及合成步骤的可执行代码/报告。
图注:LLM科学智能体的典型架构。用户输入请求后,Planner(规划器)进行任务分解并结合 Memory(记忆)生成计划;通过 Action Space(动作空间,含 API、模拟器等)与外部环境交互;生成的中间结果交由 Verifier(验证器)进行事实与科学逻辑校验;经验证的知识存入记忆库,持续迭代直到生成符合科学标准的最终结果。 ⚙️ 方法论与技术实现 (Methodology & Architecture)
论文将科学智能体的底层技术解构为四大基石:
1. Planner (规划器):应对科学问题的高维与开放性
分为 提示原生规划器 (Prompt-Native) 和 基于学习的规划器 (Learned Planners) :
Prompt-Native: 包含指令/Schema驱动(固定SOP)、上下文增强(RAG介入)、反思型(Self-critique)、搜索型(如运用 MCTS 或 ToT 探索化学空间)、多智能体交互(角色扮演,如化学家+安全审查员)、编程式(输出 DSL 或 DAG 直接驱动工作流)。Learned Planners: 通过 SFT(在百万级科学推导轨迹上微调,如 LLaMA-2-7b 微调的 Chemma)或 RL/DPO(利用实验成功率、能耗等作为 Reward 进行策略优化)将规划能力内化进参数。
2. Memory (记忆模块):跨周期的知识累积
Historical Context: 维护工作区内的推理链条、过往实验失败的 Error Trace,支持跨 Session 的经验回放(Experience Replay)。External Knowledge Base: 与大规模本体库(如 MatSciKB, 蛋白互作网络)和实时学术文献库深度融合,避免知识陈旧和幻觉。Intrinsic Knowledge: LLM 预训练或持续预训练阶段内化的领域知识(如经过 16.8万 GPU小时天文文献 Continual Pretraining 的 AstroMLab)。
3. Action Space (动作空间):连接赛博与物理世界
这是科学 Agent 区别于通用 Agent 的最大特征:
工具与环境控制 (Tool/Environment Control): 调用特定 API (如 RDKit);更核心的是模拟器与仿真平台集成 (如 OpenFOAM 计算流体力学,VASP 量子化学计算);以及直接生成控制机器人湿实验室(Wet-lab)的底层指令。代码生成与执行 (Code Generation): 编写数据处理、生信分析(如 scRNA-seq 分析流)的 Python/R 脚本,并在沙盒中执行。
4. Verifier (验证器):科学研究的“质检员”
针对 LLM 的幻觉,引入了硬性护栏:
Tool-Based Validation (基于工具的物理校验): 这是最硬核的验证,将 LLM 提出的假说转换为代码,抛给物理仿真器计算能量、稳定性,用客观物理定律而非 LLM 自身的语义判断来做奖励信号 。Human-in-the-loop (专家干预): 在高风险步骤(如合成有毒物质或启动昂贵实验前)强制切入人类审批 (Approval Gates)。Multi-Agent Critique: 引入专门的 Adversarial Agent(如“安全评审员”、“预算审核员”)进行多角度挑刺。
📊 实验基准与评估体系 (Benchmarks & Evaluation)
文章整理了科学 Agent 的两类核心 Benchmarks:
通用推理能力 (General Reasoning): 涵盖从 K-12 基础数学到专家级(如 GPQA, FrontierMath, OlympiadBench )。这些基准测试证明,当前的 LLM 已经具备了深度的多步逻辑推演能力。面向科学研究的能力 (Scientific Research-Oriented): 这类 Benchmark 正在成为前沿重点,包括:
图表与文献理解: ArXivQA, MMSCI。科学假说发现: DiscoveryBench, SciMON ,测试模型从大量文献或实验数据中发掘“新颖且合理”的 Research Idea 的能力。实验设计与自动化: ScienceAgentBench, LAB-Bench, ChemToolBench ,这要求 Agent 能够调用专业工具、生成控制代码并排除真实的实验故障。
结论: 评估范式正在从传统的“静态问答(Static QA)”向“端到端动态工作流(End-to-End Dynamic Workflow)”转变,强调在真实世界交互中的容错与迭代能力。
🌟 关键技术亮点与从业者启发 (Key Takeaways)
从“工具”到“自主科研伙伴”的范式跃迁: AI 正在完成从 Computational Tool(如 AlphaFold 作为单点预测工具)到 Autonomous Research Partner(如 AI Scientist 自主提出课题、写代码验证并撰写论文)的转变。这要求架构设计必须高度重视模块间的协同编排。RL 驱动的自我进化是破局点: 虽然基于 Prompt 的规划器解释性强,但面对广阔的化学空间或物理参数空间,结合强化学习(如基于 Monte Carlo Tree Search + 模拟器反馈的 DPO/PPO 微调)的 Learned Planners 展现出了超越人类直觉的新颖设计能力。Tool-Based Validation 是刚需: 永远不要纯粹相信大模型基于“语义”的自我反思(Self-critique)。在科学领域,必须构建“LLM提出假设 -> 生成物理仿真代码 -> 运行仿真器获取客观指标 -> 反馈给 LLM 修改”的闭环,这是保证科学有效性的唯一途径。AI 科研的伦理与问责 (Accountability): 随着 Agent 能够自主控制实验室硬件,恶意修改知识图谱(如毒化药物靶点关系)或合成危险物质的风险剧增。系统设计中必须强制引入不可篡改的执行日志(Audit Logs)、作用域隔离以及关键节点的 HITL(人类在环)机制。