MindGames Arena Generalization Track: In2AI Solution with Delayed Per-Step Reward Attribution
MindGames Arena 泛化赛道:基于延迟单步奖励归因的 In2AI 解决方案
机构:iMak AI Lab, Coframe, Innopolis University
🎯 研究背景与痛点
当前,利用强化学习(RLHF/PPO 等)提升 LLM 能力的方法大多基于单智能体、单轮交互的假设。在这种设定下,奖励信号是即时且明确的。然而,当 LLM 智能体进入多智能体战略博弈(Multi-Agent Strategic Interaction)环境(如谈判、欺骗、协作)时,传统 RL 假设会彻底失效。
本文将这些痛点(Agentic Workflows 带来的挑战)总结为三大类:
- 时间纠缠 (Temporal Entanglement):即“欲擒故纵”。一个绝佳的策略动作在当前回合可能是失败的(为了长远利益而牺牲短期表现)。传统的即时奖励会错误地惩罚这类策略性动作。
- 结构不对称与信号缺失 (Structural Asymmetry & Missing Signal):回合顺位会带来不对称优势;同时,如果对手输出非法格式导致游戏崩溃,当前 Agent 即便做出了合理的推理和动作,也无法获得有效的对局结果(没有 observable outcome),此时如果强行指派奖励会引入巨大噪声。
- 训练工程瓶颈 (Training Logistics):多智能体交互的 Episode 长度高度不固定,且各模型在不同角色下的推理计算量(异构推理需求)差异极大。传统的“同步批处理 (Synchronous Batching)”会导致严重的计算资源闲置。
💡 核心贡献
- 资格门控与延迟单步奖励归因 (Delayed Per-Step Reward Attribution with Eligibility Gating):提出了一种全新的 Episode 生命周期处理管道,只在 Episode 结束后才计算奖励,并根据任务语义反向传播给特定的动作步;同时动态“过滤”(Gating)掉缺乏有效依赖信息的无效步。
- 全异步的高吞吐训练架构:彻底抛弃同步的 RL 批采样,结合 vLLM 的 Continuous Batching 机制实现了 Asynchronous Rollout,极大化了系统吞吐量。
- 极致的 SOTA 表现:基于 Qwen3-8B 训练的模型,凭借这套系统工程,在 NeurIPS 2025 MindGames Arena 赛事中,击败了大量调用 GPT-5、Gemini 2.5 Pro 等前沿闭源模型的方法,同时夺得 Open(不限参)和 Efficient(≤8B)双赛道冠军。
🔍 具体案例剖析 (Case Study)
案例 1: 欲擒故纵 (Lose to Win) - 选自 Colonel Blotto (上校赛局)
Alpha 故意在第7轮和第8轮使用相同的兵力分配 [A0 B10 C10] 输给 Beta,诱使 Beta 形成“Alpha会一直这么出”的错觉。第9轮 Alpha 突然变阵为 [A2 B12 C6] 并大获全胜。
痛点与解法:如果使用即时奖励,Alpha 第8轮的失败会被赋予负反馈。而在本文的方法中,通过计算 Match 级别的胜率并向后延展,第8轮因为促成了最终的全局胜利,反而被判定为“绝妙的伪装”,获得了正向归因。
案例 2: 连带责任 (Interdependent Rewards) - 选自 Codenames (代号行动)
Spymaster (队长) 给出了提示词 [water 2],希望队员猜 ocean 和 fish。队员第一步猜中了 ocean,第二步却错误联想,猜中了 blue (刚好是刺客牌,直接导致游戏GameOver)。
痛点与解法:第一步猜 ocean 局部来看是完美的,传统强化学习会给予最高奖励。但由于回合最终走向毁灭,本文的方法会将“刺客惩罚”进行Backward propagation(反向传播)——不仅扣除整个回合群组的分数,连带队长给出的 clue [water 2] 也将受到巨额惩罚。
案例 3: 缺失的信号过滤 (Missing Training Signal)
你给出了完美符合规则的操作 [A5 B10 C5],但你的对手回复了非法格式 [A100 B0 C0] 导致系统直接终止对局。
痛点与解法:你的优质动作根本没有得到战场的评估,不存在 observable outcome。此时赋予 0 分会打压探索,赋予任意分数都是噪音。本方案的 Steps Filter 会直接将该步标记为 ineligible(过滤掉,不进入 RL 梯度更新),而对手因为非法输出会被训练一个负向的 Penalty Reward。
⚙️ 方法论与技术架构
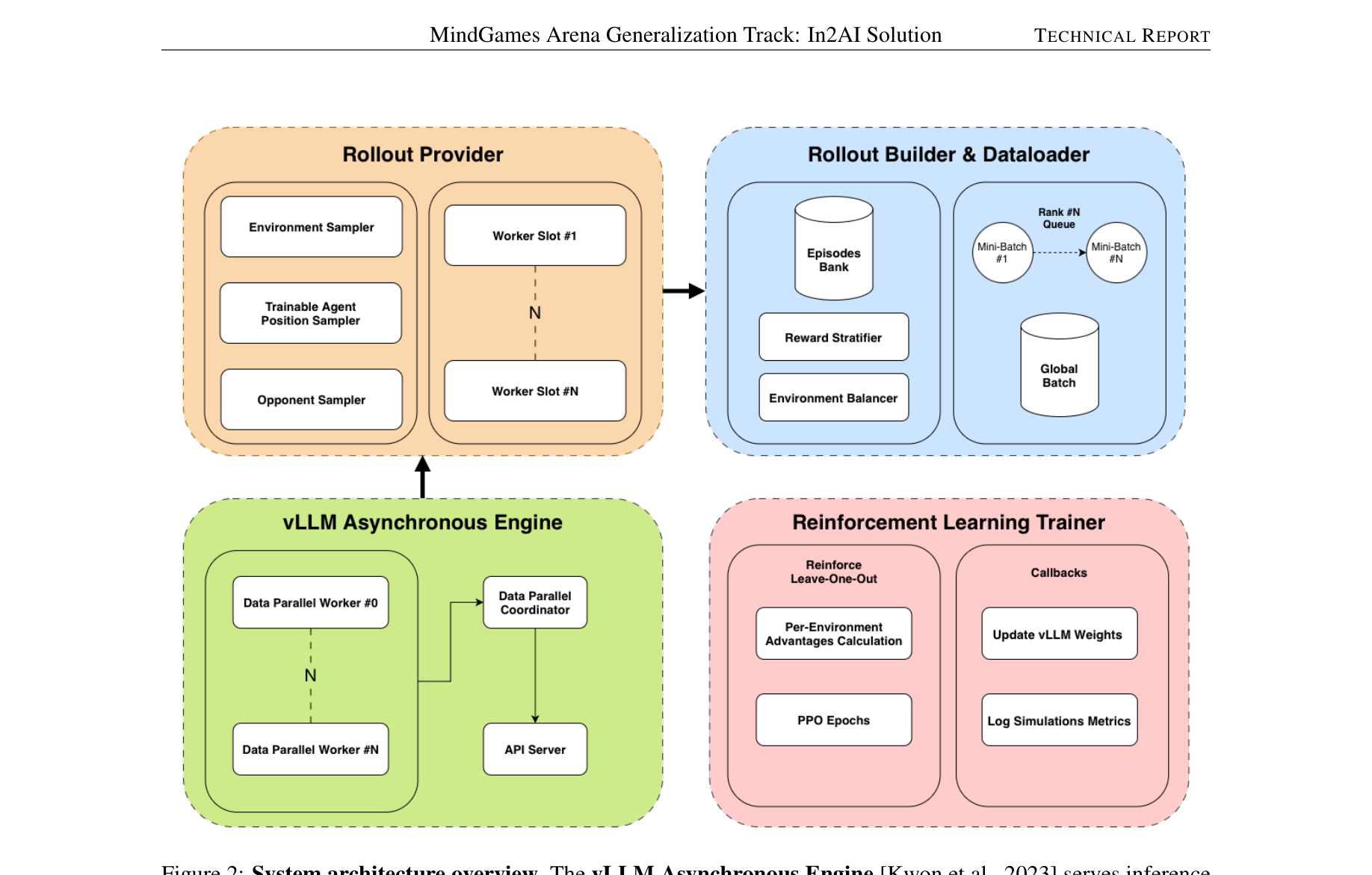
系统主要由四个子系统与后处理管道构成,彻底解耦了生成和训练的同步阻塞问题:
- Action Validation (执行期校验):统一拦截不符合 CoT 模板、Action 格式或游戏规则的输出。直接终止无效输出的 Episode。
-
后处理三段式管道 (Post-Episode Processing):
- Players Builder:负责获取完整的 Episode Outcome,对不同环境计算平滑的 Episode-Level Reward(例如回合制游戏的胜率W / M)。
- Steps Filter (资格门控):实施核心的 "无可见结果 => 无训练信号 => 过滤" 逻辑,极大净化了梯度的信噪比。
- Reward Assigner:实施精细的单步奖励(例如公式:r_clue = (N_eff / L) * (G / N_eff) + Δ_blame),并将最终胜负 outcome 作为乘数去 modulating (调节) 中间步的 Reward。 - vLLM Asynchronous Engine:摒弃了 TRL 原生的同步 Rollout。在面对极端长短不一的 CoT 推理时,利用 Continuous Batching 避免“木桶效应”,所有 Worker 并行生成。
- RLOO 优势估计器:采用了 PPO 配合 Reinforce Leave-One-Out (RLOO)。并且专门针对多游戏混合的设定,在 Advantage 归一化时做到了按 Environment 进行分组比较(Per-Environment Advantages Calculation),避免了不同游戏环境间Reward尺度不同导致的交叉干扰。
📊 实验结果
- 训练设置:基于 Qwen3-8B 作为 Base 模型。实施两阶段的“对手课程机制”(Opponent Curriculum):前期使用具备不同性格 Prompt 的开源 120B 模型;后期引入 OpenRouter 提供的前沿闭源大模型(GPT-5, Gemini 2.5 Pro 等)作为高质量对手。
- 生成超参搜索:研究发现 RL 训练完的模型对 Sampling Parameters 极其敏感。在 Blotto 游戏中由于强博弈性,需要高
Temperature=1.0;而对于 Codenames 则需要Top-p=0.8以保障准确关联推理。 - 排行榜霸榜:在 MindGames Arena Stage 2 的真实盲测中,该 8B 模型在 Open Track (无限制) 中以 TrueSkill=38.0 及 81.0% 的惊人胜率拔得头筹(亚军胜率为 73.5%);同时毫无悬念地统治了 Efficient Track (≤8B)。
✨ 资深从业者 Takeaways
1. Systems-Level Engineering > Model Scale:在复杂的 Agent 环境中(尤其是多智能体交互),系统的信用分配机制(Credit Assignment)与数据清洗(Reward Filtering)比暴力堆叠模型参数重要得多。本文用极其工程化但无比 Solid 的手段,让 8B 模型在逻辑和博弈上战胜了 GPT-5 级的闭源 Agent。
2. “垃圾进,垃圾出”在 RLHF 中依然有效:大部分多轮 Agent 框架往往对失败的互动简单塞个 Reward=-1 完事。本文深入骨髓的洞察是——如果是因为环境 / 队友 / 对手的错误导致当前策略得不到检验,这种轨迹就应该被当做 Missing Signal 直接剔除梯度的计算,否则就是在学噪音。
3. 抛弃同构 Batch:凡是做过复杂多步 CoT 强化学习的从业者都会体会到生成瓶颈。本文的 异步生成池 + 滚动解耦构造 Batch 机制,加上按 Reward 百分位动态 Stratified Sampling 策略,提供了一套能够横扫不同游戏时长、多模态输出、方差巨大的 RL 稳定落地方案。极具实战参考价值。