ToolBrain: A Flexible Reinforcement Learning Framework for Agentic Tools
ToolBrain:面向智能体工具使用的灵活强化学习框架
👥 作者:Quy Minh Le, Minh Sao Khue Luu, Khanh-Tung Tran, Duc-Hai Nguyen, Hoang-Quoc-Viet Pham, Quan Le, Hoang Thanh Lam, Hoang D. Nguyen
🏫 机构:ToolBrain Research (爱尔兰), UCC (爱尔兰), UCD (爱尔兰), IBM Research (都柏林)
🔍 研究背景与痛点 (Background & Bottlenecks)
目前,基于大语言模型(LLM)的智能体(Agent)在执行复杂任务(如规划、代码生成、API交互)中已展现出巨大的潜力。然而,作为资深的LLM从业者,我们深知在真实业务场景中开发和部署 Tool-augmented Agents 的痛点:
- 范式受限:多数Agent系统严重依赖于监督微调(SFT)或复杂的提示词工程(Prompt Engineering),缺乏通过在复杂环境中不断试错(Experience)来持续改进自我行为的能力。
- RL落地的鸿沟:尽管强化学习(RL)在DPO或GRPO等偏好对齐与推理任务上大放异彩,但在Agent的工具调用工作流中极难部署。现有框架(如ART、Agent Lightning)要不缺乏轻量级的接口,要不就强迫用户重构整个MDP环境,学习曲线极其陡峭。
- 算力与生态矛盾:大模型做Tool Calling很稳,但推理贵;小模型便宜,但零样本调用极差;此外,现实世界工具库(Tool Ecosystem)庞杂,大模型很容易因为过长的 Context 和无数无关工具产生幻觉(Hallucination)。
- 高质量数据稀缺:人工标注或编写高质量的
Task-Tool轨迹(Execution Traces)成本极其高昂。
💡 核心贡献 (Core Contributions)
本文提出了 ToolBrain,一个极其轻量、对开发者友好的强化学习框架,专门为训练Agent的工具使用能力而设计。其核心贡献包括:
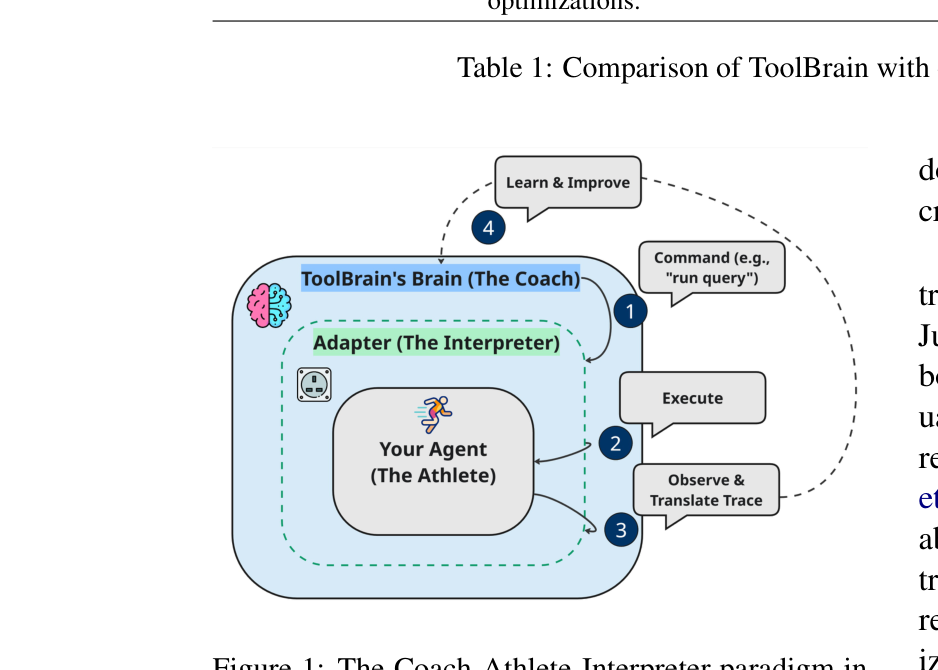
- 创新的 Coach-Athlete 架构:将训练逻辑(Coach/Brain)与任务执行(Athlete/Agent)完全解耦,引入 Adapter 作为通用解释器,无缝兼容业界常见的第三方框架(如
smolagents,langchain)。 - 混合灵活的奖励系统 (Flexible Reward System):打破设计Reward的黑盒。支持用户编写原生Python代码根据 execution trace 提供硬核规则奖励,同时内置支持排序驱动的 LLM-as-a-Judge(基于偏好反馈生成标量奖励)。
- 开箱即用的原生 RL 支持:原生集成最前沿的 GRPO (Group Relative Policy Optimization) 和 DPO (Direct Preference Optimization)。
- 高阶大满贯全家桶:集成了大模型落地的四大法宝:Intelligent Tool Retrieval(大模型辅助前置工具检索)、Zero-Learn Task Generation(无数据冷启动自生成)、Knowledge Distillation(大模型蒸馏小模型策略初始化),以及底层的 QLoRA / Unsloth 极致显存优化。
🛠 具体案例剖析 (Case Study / Input-Output Examples)
论文对 ToolBrain 处理无标注数据的 Zero-Learn 数据合成流水线进行了剖析,通过输入一段高级别的 task_description(如:"Generate tasks to learn to use simple finance tools"),框架会自动引导模型生成三种类型的 Queries:
- Executable Tool Calls(完美的可执行用例):
"Calculate Loan Payment with annual rate of 5%, 7 years, principal of $10,000."(引导Agent调用相应财务函数) - Formula / Explanatory(公式/解释性质,不强制调用工具):
"What is the formula for calculating compound interest?" - Out-of-scope / Noisy(超纲或含噪请求,用于提升鲁棒性):
"...convert this amount to USD using the current exchange rate and compute the NPV."(当前工具可能并不支持汇率转换)
代码层面的极简体验:
ToolBrain 在计算 Reward 时的 API 设计极具实战价值。例如,针对 Agent 的执行步骤,开发者可以简单传入一个 Python callable 进行效率惩罚(如附录代码所示):
penalty = (num_turns - max_turns) * 0.1
return max(0.0, 1.0 - penalty)
配合 brain.train() 一行代码即可开启端到端的 GRPO 强化学习。
⚙️ 方法论与技术实现 (Methodology & Implementation)
ToolBrain 的工作流封装在高度模块化的技术栈中:
- Execution Trace(执行轨迹)标准化:Adapter 模式将底层 Agent 的多轮交互抽象为一个标准化列表。每个
Turn包含:prompt_for_model,model_completion,解析出的tool_code以及tool_output。这使得下游的 RL 算法完全与具体的 Agent 实现隔离。 - GRPO 优化 (Group Relative Policy Optimization):
ToolBrain 在支持显式标量奖励时,使用了现代的 GRPO 算法(相比PPO省去价值网络的开销)。对于每个 Query $q$,生成一个 Group $G$ 数量的 Traces,计算奖励 $r_i$,进行组内优势归一化:
$\hat{A}_i = \frac{r_i - \text{mean}(\{r_j\}_{j=1}^G)}{\text{std}(\{r_j\}_{j=1}^G)}$
随后优化策略 $\pi_\theta$ 以最大化奖励并控制与参考模型的 KL 散度。 - DPO 优化 (Direct Preference Optimization):
无需单独训练 Reward Model。使用 LLM-as-a-Judge 输出 preferred $y_w$ 和 dispreferred $y_l$ 的 pair,直接应用 DPO 损失:
$\mathcal{L}_{\text{DPO}}(\theta) = -\log \sigma \left( \beta (r_\theta(y_w \mid x) - r_\theta(y_l \mid x)) \right)$ - Distillation for Policy Initialization(策略初始化蒸馏):
在进行复杂 RL 前,ToolBrain 支持使用一个 Teacher model(如 7B/GPT-4)运行任务生成 Traces 缓存,过滤出奖励 $r_i > \rho$ 的高质量轨迹组合成 $\mathcal{F}$,对 Student model(如 0.5B)执行 Cross-Entropy 的 SFT:
$\mathcal{L}_{\text{distill}}(\theta) = -\frac{1}{|\mathcal{F}|} \sum_{x \in \mathcal{F}} \sum_{t=1}^{|y|} \log \pi_S(y_t | x, y_{
📊 实验设置与结论分析 (Experiments & Results)
文章设计了一个核心实验和两个补充实验,验证了框架对不同规模模型的能力提升:
- 核心实验(Email Search Agent):基于真实的 Enron Email Corpus(约50万封邮件)。Agent 需要通过调用多个工具进行检索、阅读和信息整合。
- Qwen2.5-3B:未经训练时完全失败(成功率0%)。通过60步的GRPO训练,任务成功率飙升至 16.7%。
- Qwen2.5-7B:Zero-shot成功率为 13.3%(伴随高达60%的幻觉率)。经过60步训练后,成功率提升至 43.3%,幻觉率大幅下降至 35.0%,同时平均交互轮数从 7.03 降至 4.77(表明工具调用变得更精准高效)。
- 补充实验(0.5B 极小模型的垂直领域蒸馏):
- Finance Agent(量化推理):在经过蒸馏后,精准调用正确工具的比率从未训练时的 20% 翻倍至 40%。
- API Agent(真实世界天气API调用):成功率从 30% 提升至 60%。
实验清晰地证明了无论是大模型的泛化推理提效,还是极小模型的特定领域任务注入,ToolBrain 的整套流程都极其有效。
🌟 关键技术亮点分析 (Key Technical Highlights)
站在工业界大模型研发的视角,ToolBrain 这篇论文最打动人的并非是提出了什么震惊世界的全新算法,而是其在 “工程化解耦” 和 “训练生态大一统” 上做的卓越抽象:
- “闭环思维”极度完善:当前许多论文只讲怎么做RL,却不提数据从哪来。ToolBrain 串联了
无中生有(Zero-Learn) -> 大带小(Distillation Warm-up) -> 精细雕琢(GRPO/DPO + Tool Retrieval)的全套范式。这正是目前企业界快速适配垂直领域 Agent 最急需的 Standard Operating Procedure (SOP)。 - Reward API 的降维打击:把复杂且难以定义的 RL 环境,拍扁成了对一串 JSON / Text 的后置打分。不仅让开发工程师极易上手(仅需写简单的 Python if-else 规则或配置个 GPT-4 裁判),还避开了传统 Gym 环境那令人窒息的状态空间定义。
- 面向显存贫穷的友好支持:能将 Unsloth 和 QLoRA 这种底层的 Optimizer/Quantization Config 作为参数一键传给 Brain(强化学习容器),这是真正的工业级思维,大大降低了开发者复现和微调 Tool Agent 的门槛。